Wave Computing close to unveiling its first AI system

The rapid evolution of deep learning has started an AI arms race. Last year, venture capitalists poured more than $1.5 billion into semiconductor start-ups and there are now some 45 companies designing chips purpose-built for artificial intelligence tasks including Google with its Tensor Processing Unit (TPU). After quietly testing its "early access" system for nearly a year, one of these startups, Wave Computing, is close to announcing its first commercial product. And it is promising that a novel approach will deliver some big gains in terms of both performance and ease of use for training neural networks.
"A bunch of companies will have TPU knock-offs, but that's not what we do--this was a multi-year, multi millions of dollars effort to develop a completely new architecture," CEO Derek Meyer said in an interview. "Some of the results are just truly amazing."
With the exception of Google's TPUs, the vast majority of training is currently done on standard Xeon servers using Nvidia GPUs for acceleration. Wave's dataflow architecture is different. The Dataflow Processing Unit (DPU) does not need a host CPU and consists of thousands of tiny, self-timed processing elements designed for the 8-bit integer operations commonly used in neural networks.
Last week, the company announced that it will be using 64-bit MIPS cores in future designs, but this really for housekeeping chores. The first-generation Wave board already uses an Andes N9 32-bit microcontroller for these tasks, so MIPS64 will be an upgrade that will give the system agent the same 64-bit address space as the DPU as well as support for multi-threading so tasks can run on their own logical processors. (Meyer and others on the management team previously worked at MIPS, and Wave is backed in part by Tallwood, the same venture capital firm that recently acquired MIPS from Imagination Technologies for $65 million.)
But that's for future processors. The current design consists of thousands of independent processing elements, each with its own instruction memory, data memory, registers and an 8-bit logic unit. These are grouped into clusters, each of which contain 16 processing elements and additional compute units including two 32-bit MAC (multiply-accumulate) units that perform some of the key arithmetic functions in convolutional neural networks (CNNs).
Manufactured by TSMC on a 16nm process, the Dataflow Processing Unit (DPU) contains 1,024 of these clusters for a total of 16,384 processing elements with a mesh interconnect. These are grouped into an array of 24 Compute Machines each with 32 or 64 clusters and a bus that connects to the memory and I/O. It has a peak capacity of 181 trillion 8-bit integer operations per second, but the 2,048 MAC units (8 trillion MACs per second) should deliver up to 16 teraops.
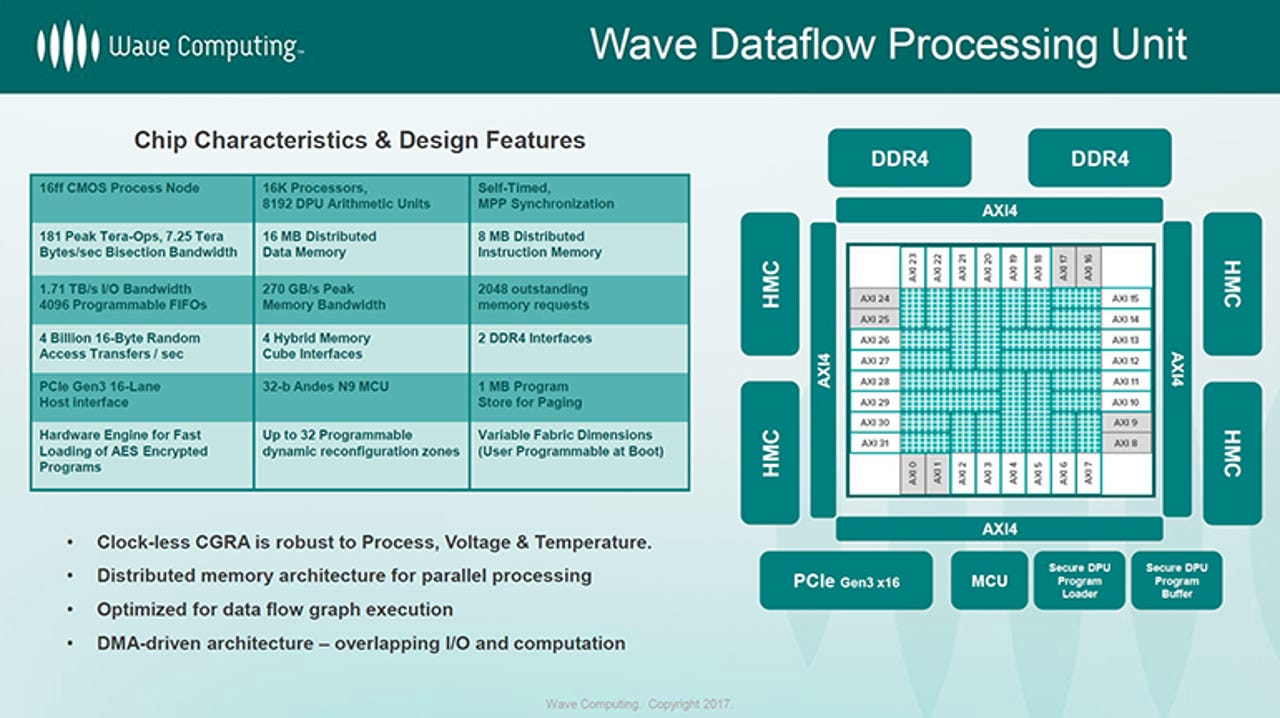
Wave's goal isn't to sell these chips. Instead it wants to provide a complete AI system. The beta board has four DPUs (65,536 processing elements) 256GB DDR4 system memory and 8GB of high-bandwidth DRAM (four 2GB Hybrid Memory Cube stacks). A PCI-Express switch connects it to other boards as well as the system agent. Four of these are packaged in a 3U rack enclosure and a single node can have up four of these Wave Compute Appliances with more than one million processing elements, 8TB of DRAM and 128GB of HMC memory delivering peak capacity of 11.6 petaops. A host Linux server manages sessions across multiple nodes.
It's an impressive design, but Meyer hinted that the commercial version will look quite different. It may not be a rackmount server at all. One possibility is that Wave will opt for a workstation along the lines of the Nvidia DGX1 Station, which has four Tesla V100 GPUs. Wave could also make its DPUs available as a service through the cloud either on its own or with a partner.
Regardless of how it looks on the outside, Wave's first product will be a test of a very different architecture on the inside. As the name implies, the dataflow architecture focuses on moving data through a processor array quickly, rather than executing a series of instructions in sequence. The Wave DPU does not require a host CPU and it has no operating system or applications. Unlike a CPU, which can execute instructions out of order and combine instructions, the DPU has no global clock and is statically scheduled. Since there is no shared cache, there's no need to worry about maintaining coherency.
To run a neural network, the Wave compiler breaks it down into a series of steps and assigns them to groups of processing elements where they are stored in local instruction memory. When data is loaded from DRAM or the HMC stacks into the DPU, the asynchronous logic immediately performs an operation and then passes the result on to neighboring processing elements. The process continues until there is no more data left, at which point the cluster goes to sleep.
This extremely simple design has a number of advantages for deep learning. It allows the processing elements to run at much higher speeds. The self-timed logic is theoretically capable of reaching 10GHz, though Wave says in practice it will operate at around 6.7GHz. It also reduces the die area and allows Wave to pack thousands of processing elements on a single chip without having to stay at the bleeding edge of process technology.
All of this depends, however, on having a good compiler that can take existing models and assign tasks to thousands of processing elements in a way that maximizes the dataflow architecture. For now, the DPU and software works with Google's TensorFlow framework, though Wave has also talked about adding support for Microsoft Cognitive Toolkit and MXNet, Amazon's tool of choice for AWS.
While Wave will compete for current users already working in these frameworks, its real goal seems to be to reach organizations that aren't already using artificial intelligence. "There is a much larger market out there of businesses that do not use deep learning and that is a great opportunity for us," Meyer said. "For companies that do not yet use AI, this is going to open up whole new use cases." Wave suggested the design, price and ease of use of the system will all help to attract new users to AI, but we'll obviously need to wait for details on the commercial product.
Ultimately it will need to deliver competitive performance too. When Wave first announced the DPU, at the Linley Processor Conference in 2016, it talked about a 10x speed-up over contemporary GPUs. More recently, Wave has promised up to 1,000 times better performance than current CPUs, GPUs and FPGAs (a relatively wide range of capabilities). It has also showed some test results using a single node (64 DPUs) on several CNNs for image recognition, as well as a Recurrent Neural Network (RNN) for machine translation, that indicate it is capable of training complex neural networks in hours. Meyer said that Wave is on track to deliver he promised levels of performance and "and maybe even beyond" with the commercial system.