Xilinx and Numenta claim dramatic speed-up of neural nets versus Nvidia GPUs

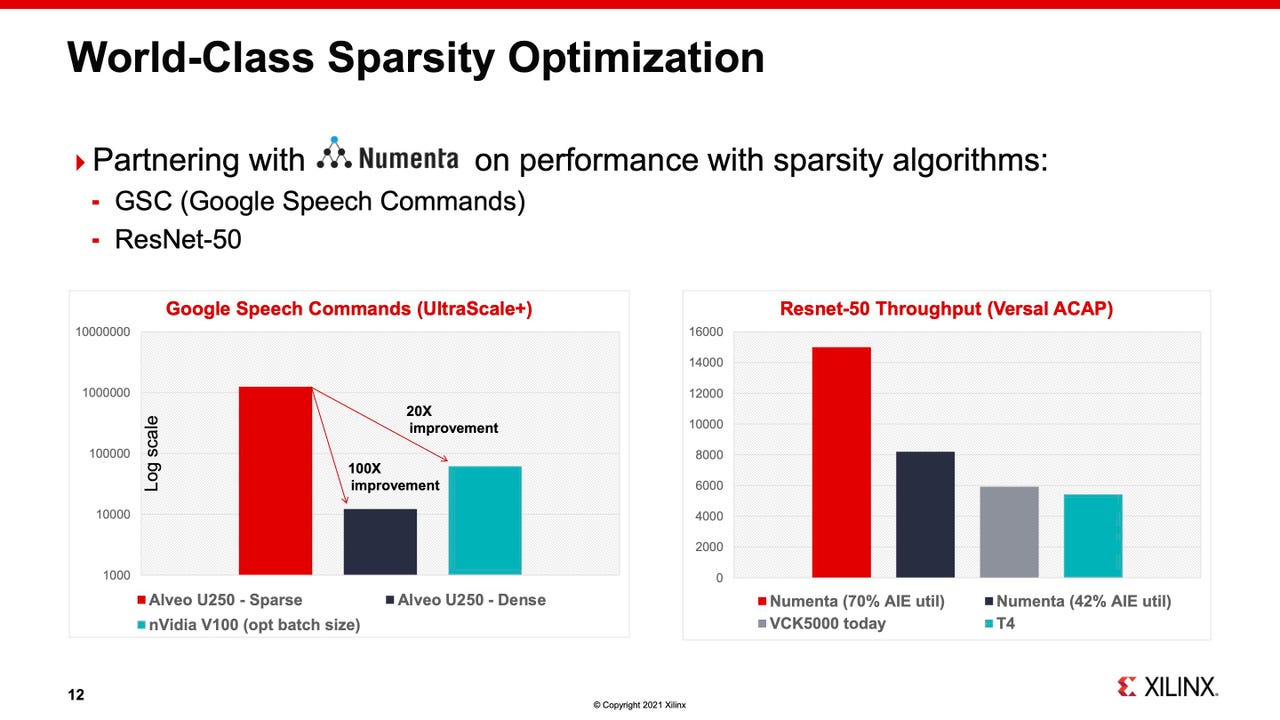
Benchmark tests results offered by Xilinx and Numenta for Xilinx FPGAs on two standard machine learning AI tasks, Google Speech Commands, and ImageNet. In both cases, the Y axis is a measure of throughput, words per second in the case of Google Speech Commands, and images per second in the case of ResNet-50 on ImageNet, where the higher bar is the better score because it equals greater throughput.
Numenta, the Silicon Valley artificial intelligence firm founded by Palm Pilot creator Jeff Hawkins, has been able to achieve a dramatic speed up in conventional neural networks using Xilinx programmable logic devices, Xilinx CEO Victor Peng told ZDNet in an interview Friday via Zoom.
The speed-up offers orders of magnitude improvement over the industry heavyweight, Nvidia's, chips, claims Xilinx in benchmark tests.
"We achieve factors of improvement, and we beat the GPU," said Peng, discussing benchmarks the company conducted with Numenta. The measure of success is throughput that trained neural networks are able to perform.
Xilinx is in the process of being acquired by Advanced Micro Devices for $34 billion dollars, a deal announced last October. The deal has been approved by the two companies' shareholders, is in the midst of the European Union approval process, and is expected to close by the end of this year.
Xilinx offered time with Peng as a general update on progress at Xilinx while the transaction is underway.
"People always talk about TOPS, TOPS, TOPS," says Xilinx CEO Victor Peng, referring to benchmark machine learning stats. "TOPS only talks about the peak performance of your data path."
The benchmark performance carried out by Xilinx and Numenta was done on two common benchmark tests of machine learning algorithms.
The first was the Google Speech Commands, a dataset introduced by Google in 2017 to test speech recognition. The second was ResNet-50, an image recognition algorithm used on the popular ImageNet dataset.
Also: AI is changing the entire nature of compute
A Xilinx Alveo FPGA, said Peng, was able to achieve a 100-times increase in the amount of throughput in terms of words recognized correctly per second in the Google Speech test, relative to an Nvidia V100 GPU. The data had been disclosed by Numenta back in November.
The ImageNet test on ResNet-50 had not previously been disclosed by either party. In that instance, the throughput in images per second recognized was accelerated by three times on the Xilinx part, called Versal, versus an Nvidia T4 part.
One part of the performance comes from what Xilinx calls its "AI Engine," or AIE, which is a set of reconfigurable circuits that are able to speed up the basic operations of neural networks, the multiplication of vectors and matrices representing input data and weight values, respectively.
Equally important, in both tests, the AI ability of the Xilinx chips was helped by Numenta scientists, led by Subutai Ahmad, Numenta's head of research and Engineering.
Numenta is conducting research into the brain, specifically the youngest part of the brain, the neocortex, which performs the higher-level cognitive functions in mammals, including visual perception. Founder Hawkins has written about the complex way in which the neocortex may function, a manner very different from conventional deep learning forms of AI.
Also: A love letter to the brain: in his new book on AI, Jeff Hawkins is enamored of thought
Despite that difference, Numenta, under Ahmad's directions, is simultaneously trying to turn knowledge of the neocortex into usable algorithms to speed up deep learning.
Numenta's insight was to eliminate some zero-valued numbers from the matrix multiplications, an approach that is increasingly common, called sparsity. Removing the need to compute zero values reduces the overall compute burden of a chip.
As Ahmad explained to ZDNet in December, "The thing we've done with hardware is leveraged the sparsity to increase the efficiency of computation."
"In neural networks, everything happens with these matrix products, and if you multiply two numbers together, if either number is zero, you can skip that multiplication, because the result will be zero, so you can skip a large percentage of the multiplications."
The implementations of sparsity in the Xilinx chips, said Ahmad, means "we can design the circuitry to be custom-built for sparse networks."
Not only can a sparse network on the custom chip be faster, it can be spatially compact, said Ahmad, "and so we can run more of them on a chip."
"We can run twenty of these networks on the chip versus four dense networks, so when you multiply it all out, the full chip is fifty times faster than you could get with a dense network."
More details on the collaboration are available in a formal announcement by Numenta.
The numbers offered by Peng are a kind of response to numbers typically bandied about by Nvidia, which tends to dominate measures of neural network performance.
Those performance metrics, of which trillions of operations per second, or TOPS, are criticized by some as not representing real-world tasks, being just to pump up Nvidia's results.
"People always talk about TOPS, TOPS, TOPS," said Peng. "TOPS only talks about the peak performance of your data path."
"What the application performance is really dependent on is not only the data path, but the memory, and how the memory moves."
Also: To proliferate AI tasks, a starter kit from Xilinx, little programming required
Being able to customize things such as memory throughput mechanisms allows the Xilinx chips to "get better real, sustained performance even if we don't win theoretical peak TOPS number."
"We are doing really well in AI," said Peng.
Xilinx's bet is that products such as Versal will win deals because they do more than just AI. Although the AIE is a key ingredient, the Xilinx chips can do well at accelerating other tasks, not just the linear algebra, what the company calls "whole-application acceleration."
"Even if we're not the all-out winner in AI in a particular case, though in some cases we are, we can still actually deliver a better user experience in the whole application," he said, "and I think that's what matters.