Chipmaker AMD plans to super-size its processor

Chipmaker AMD has shed a little more light on efforts to extend its APU technology, which marries a CPU and high-end graphics on the same die, from game consoles and PCs to supercomputers in an attempt to deliver new levels of performance. The company is pushing its heterogeneous architecture, along with a novel memory hierarchy, as the best path to reaching exascale performance in a plausible power budget.
The concept isn't new. AMD has been working on these ideas for several years under its FastForward and FastForward 2 programs funded by the U.S. Department of Energy. But in a paper to be published in the upcoming issues of IEEE Micro journal (a draft is available behind a paywall), AMD researchers described in more detail just what this system might look like.
A system capable of reaching more than one exaflop, or 1,000 petaflops, would need at least 100,000 interconnected servers each capable of around 10 teraflops. And it would need to come in at less than 20 megawatts. To put that in perspective, the current world's fastest supercomputer tops out at 33.86 petaflops and uses 18MW. At the chip level, Intel's fastest Xeon E5-2600v3 (Haswell-EP) processor delivers a little more than half a teraflop and a high-end AMD or Nvidia GPU is capable of around 3 teraflops at double-precision.
In other words, Moore's Law alone isn't going to get us there any time soon. Instead AMD is proposing what it calls an Exascale Heterogeneous Processor (EHP) that combines 32 CPU cores--running either the x86 or ARM instruction set--with a large GPU that does most of the heavy lifting to get to 10 teraflops per node.
An exascale system will also require more memory with greater bandwidth. AMD proposes using the same 3D-stacked High-Bandwidth Memory that it has pioneered in its latest high-end GPU. The Radeon R9 Fury X uses four 1GB stacks (each consisting of four 2Gb chips) for a total of 4GB of DRAM with a bandwidth of 512GBps. For the EHP, AMD wants to boost that to eight stacks (each with four 4Gb chips) for a total of 16GB per server node with around 1TBps of bandwidth based on current specifications. With some enhancements, AMD thinks the bandwidth could eventually be pushed to 4TBps meeting the exascale goal.
But that still won't be enough memory so AMD adds another tier of non-volatile memory to reach the goal of at least 1TB per server node. Unlike the HBM memory, which is located close to the processor on a silicon interposer in the same package, this larger pool of memory would be outside of the package. It could be flash memory or it could be one of the emerging forms of non-volatile memory such as RRAM (resistive RAM), MRAM (magnetoresistive RAM), phase-change memory or memristors. This is very similar in concept to 3D Xpoint memory, which Intel and Micron announced last week, which is meant to fill the gap between high-speed DRAM and high-density flash memory in high-performance computing.
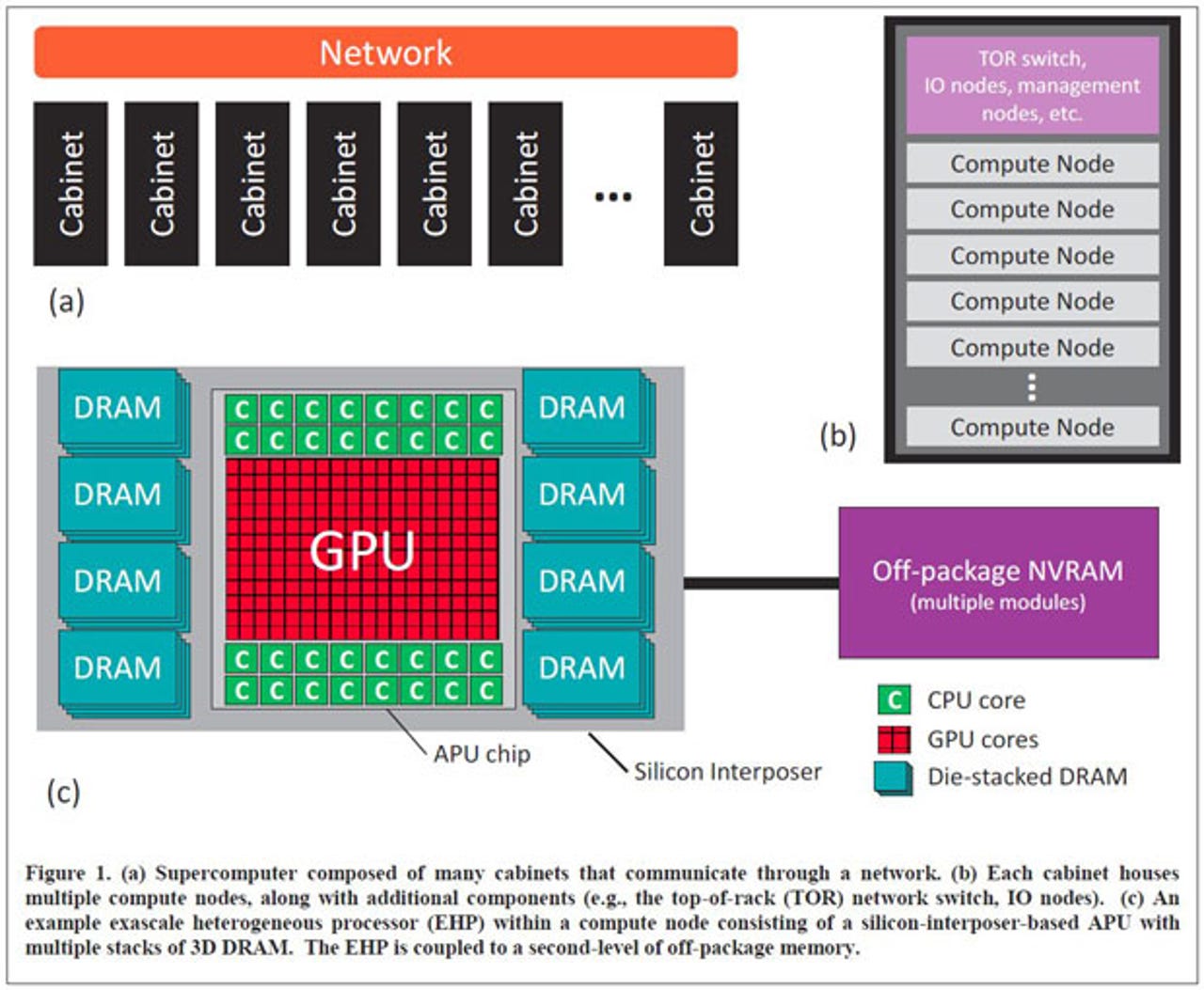
The final piece of AMD's exascale idea is the Heterogeneous System Architecture (HSA), a set of hardware and software specifications that allow the CPU cores and graphics to share a single, virtual memory space so that any core can work directly on data regardless of where it is stored in this complicated memory hierarchy. In theory that takes some of the load off the CPU, minimizes the need to continually shuffle data around, and makes it easier to program. But AMD admits there is still a lot of work that needs to be done on HSA to make it work on such a large, complex system. That's just the start. Other challenges include development of interconnects, both on the chip (Network-on-Chip) and at the system level; new processing-in-memory capabilities; and more robust heterogeneous processors for mission-critical applications.
A number of stories have attempted to connect the dots between the APUs on AMD's 2016-2017 server roadmap and this EHP. They may be related, but it's unlikely they are the same.
Server chips with graphics or other specialized accelerators make sense for a number of cloud and enterprise workloads. That's why AMD already sells a server APU, the Opteron X2150, and Intel's Xeon E3-1200 v4 has integrated Iris Pro P6300 graphics. (It's also why Intel is shelling out nearly $17 billion on Altera to speed up integration of programmable logic in server chips.) It only makes sense that AMD would want to scale this with future APUs for high-performance computing that take advantage of more advanced process technology, the upcoming Zen microarchitecture that supports simultaneous multi-threading, and better graphics.
The EHP, by contrast, is part of a long-term project targeted specifically at future supercomputers. In a blog post announcing the FastForward2 program, CTO Mark Papermaster wrote that AMD's research on using APUs and a next-generation memory targeted "commercial use in in the 2020-2023 timeframe." Last week, when President Obama issued an executive order creating the National Strategic Computing Initiative (NSCI), the administration said the chief goal was to realize an exascale system over the next decade and the Department of Energy is now aiming for 2023-2024.
The best way to reach that goal may well be with heterogeneous systems that use both general-purpose CPUs and accelerators like GPUs. It's why so many of the world's fastest supercomputers have adopted accelerators in recent years. AMD is hardly the only one working in this area, but they are well-positioned to play a leading role.