AtScale 6.0 and Kinetica 6.1 announced; SAP gets NVIDIA GPU religion

There's just no rest for the proverbially weary. Less than 2 weeks after the Strata Data Conference wound down in New York, Tableau Conference 2017 kicks off today in Las Vegas.The Tableau Conference brings with it another basket of data industry news, the activity around which will hopefully contribute in some small way to helping Las Vegas heal.
AtScale turns 6.0, gets Google BigQuery
The first piece of news comes from AtScale, which sits at the intersection of Business Intelligence (BI) and Big Data, perhaps even more so now with its newly announced 6.0 release. AtScale builds virtual (non-materialized) OLAP (online analytical processing) cubes over data in Hadoop, an approach which meshes nicely with front-end BI tools like Tableau which were designed for such models and repositories. And now, with the 6.0 release, AtScale is diversifying past Hadoop data, to offer connectivity to Google BigQuery as well.
Also read: Google's BigQuery goes public
I wrote about BigQuery when it first came out. At that time, Google was promoting it as an OLAP server. But BigQuery functions much more like a Data Warehouse, and Google's rhetoric has changed to match that reality. AtScale, meanwhile, allows users to build a semantic layer (an OLAP schema, in other words) over data in BigQuery. When combined with the company's Active Cache technology (explained very nicely in this blog post about 6.0), AtScale accommodates live connections to the cloud-based BigQuery service from tools like Excel, and provides OLAP-league query response times in the process.
The Adaptive Cache technology is primarily defined by a combination pre-calculated aggregations, some dimension members that may be used to populate selectable filter values (a new feature) and a query optimizer that uses both of these to avoid superfluous queries to the back end. In the Hadoop context, this speeds things up immensely as it avoids overexposure to the batch job tendencies of that platform (which still exist, even with modern optimizations like Spark and YARN).
In the BigQuery context, the optimizations get even more interesting. Because if the Adaptive Cache can avoid needless repetitive queries to the database, that avoids the latency of calling a cloud service. And operations like Excel PivotTable drill downs and filter population can generate a lot of discrete queries MDX to the back end.
Pruning out a bunch of those (which AtScale says can be done, given the alignment of queries that tend to be issued by a bunch of users looking at the same data) can save a lot time and cut costs. AtScale says its initial tests on BigQuery indicate that "query costs have been reduced by up to 1,000X per query." I haven't and cannot verify this finding, but I don't doubt that a little optimization with a cloud service like BigQuery can go a long way. And since BigQuery is monetized based on query activity, the economic impact of AtScale's tech may well be significant.
While adding BigQuery as a supported back-end is a big departure from AtScale's previously Hadoop-exclusive approach, it seems likely that more data sources will get on-boarded. AtScale doesn't think Hadoop is dead; far from it in fact. CEO Dave Mariani told me they see Hadoop adoption continues to grow. But as it does so, people are increasingly understanding that federating that data with their more conventional database engines, including MPP (massively parallel processing) data warehouses, is imperative. And AtScale wants its Universal Semantic Layer (a concept it introduced with its 5.5 release) to be the place where that federation happens.
Parallelism thinks global, can act local
The interesting thing about MPP data warehouses is how they achieve their parallelism: by combining an array of database instances, each on a separate server, and then having a master node that delegates subqueries to each one. The individual servers execute their subqueries in parallel, get the result sets back to the master node, which combines them and sends a single one back to the client. This divide-and-conquer approach is what drives Hadoop and Spark, too. In fact the whole notion of making Big Data processing feasible is based on the idea of splitting the work up in enough (smaller) pieces where parallel processing can take on ever-growing volumes.
But why couldn't all that divide-and-conquer work happen within individual servers as well? It turns out that GPUs (graphics processing units) can accommodate just that scenario. They take the notion of vector processing on a CPU (where multiple pieces of data are processed at once, rather than one at a time) and project it out over much greater scale. That's why, in addition to graphics processing itself, GPUs work so well for AI and Deep Learning. Models of the latter type have layers of neural networks, and that layering means that training the models benefits greatly from having the parallelization that GPUs afford.
Kinetica makes MPP go GPU
Why can't we bring this idea back home to the database? We can, as it turns out and that's what the folks at Kinetica have done. They've created the same kind of in-memory, columnstore database that the MPP guys have, but instead of parallelizing only over multiple servers, they do within each node, over GPU architectures. The company made announcements at Strata, which I covered, including a way to use their product as a massive performance-improving cache for Tableau.
Also read: Strata NYC 2017 to Hadoop: Go jump in a data lake
It's no surprise, then, that the company is making announcements at Tableau Conference in addition to Strata. Specifically, the company is announcing its new 6.1 release. 6.1 brings with it a few key improvements:
- The back-end rendering of geospatial visualizations (data on maps), already unique for a database, is now being improved through the adoption of OpenGL: and the leveraging of the GPU for its original use case: graphics.
- Speaking of geospatial, Kinetica is updating its product so that a large array of geospatial functions are available from its SQL dialect, and not just through arcane API calls. Functions like nearest neighbor calculation and calculating points within a region -- over 80 geospatial operations in all -- can now be run from the SQL layer, using the syntax already defined for those workloads in PostreSQL's PostGIS extender.
- A number of new enterprise features have been added to the product. These include compression and dictionary encoding; enhanced monitoring; simplified administration and dynamic resource provisioning; and new security features including role mapping and an auditing log facility, so it's always possible to look back and figure out who conducted an operation, and when.
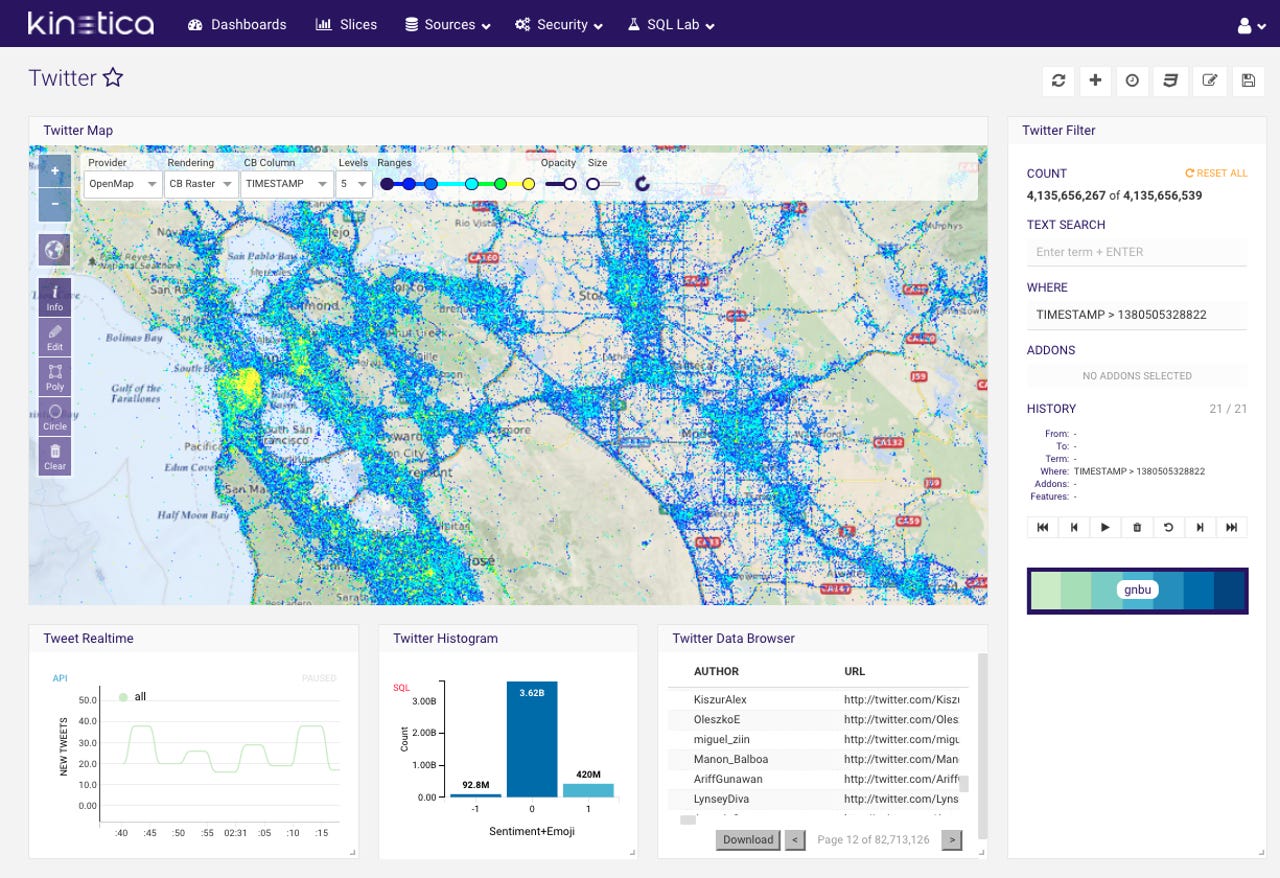
A Kinetica server-rendered, GPU-accelerated, geospatial visualization.
Kinetica has also greatly streamlined cloud deployment. It has new simplified deployment on Amazon Web Services and Microsoft Azure...straightforward enough, apparently, that the company calls it "One-Click Cloud." The licensing is getting easier too, as users have the option of bringing their own license, or simply paying on a usage-based/metered basis for the work they do on cloud-hosted instances of Kinetica.
Combine all that with the fact that a new 90-day trial edition of the product will be available by October 31st, along with the Azure and AWS 6.1 releases themselves, and curiosity about this interesting product can be addressed at very reasonable expense (it can run on conventional CPUs too).
Leonardo likes GPUs too
In my roll-up of news from Strata, I mentioned that Kinetica runs on NVIDIA GPUs. Well, today's round of news includes a non-Tableau related item: NVIDIA GPUs are now finding their way into SAP data centers and, by extension, its cloud services too. The immediate impact of this is that SAP says its Leonardo Machine Learning Portfolio is the first Enterprise offering to use NVIDIA's Volta AI Platform.
Leonardo Machine Learning Foundation services -- including SAP Brand Impact, which automatically analyzes large volumes of videos to detect brand logos in moving images (and, by extension, ROI on product placements), and SAP Service Ticket Intelligence, which categorizes service tickets and provides resolution recommendations for the service center agent -- will feature NVIDIA Volta-trained models behind the scenes. When you consider SAP's roots in Enterprise Resource Planning (ERP), and its business application orientation, its partnership with NVIDIA should go a long way toward integrating AI into line-of-business workloads.
That's not all, folks
I wish I could say the data and analytics news cycle is about to settle down, but I know that's not the case. This week and beyond, there's more stuff in the pipeline. We live in a pretty turbulent world right now, both in terms of politics and data protection. Despite the relative instability that would suggest, the data world is going gangbusters anyway. Because the only way through entropy is mastery over data, information, and trends -- and the control and predictive capabilities that comes along with it.