Databricks launches SQL Analytics

The SQL editor in Databricks' new SQL Analytics Workspace
Data analytics contender Databricks offers a platform that, along with the open source Apache Spark technology on which its core is based, has long been a favorite for attacking streaming data, data engineering and machine learning workloads. It has also "moonlighted" as a SQL analytics platform, able to accommodate popular business intelligence (BI) tools, and their queries, in a pinch. Today, Databricks is announcing SQL Analytics, a set of interface and infrastructure capabilities that transform SQL analytics on the platform from mere sideline to first-class use case.
The big ticket items are the addition of a SQL Analytics Workspace user interface to the Databricks platform, as well as the ability to create dedicated SQL Analytics Endpoints. The former leverages technology derived from Databricks' acquisition of Redash, announced in June. The latter are clusters dedicated to ad hoc analytics/BI workloads, and allow customers to leverage more fully the Delta Engine capabilities added to the core Databricks platform, also in June.
Must read:
- Data Lakehouse, meet fast queries and visualization: Databricks unveils Delta Engine, acquires Redash
- Databricks moves MLflow to Linux Foundation, introduces Delta Engine
Nota bene
Users of the Databricks platform -- including both Azure Databricks and the Unified Data Analytics Platform service hosted on Amazon Web Services -- already had the ability to create SQL-based notebooks. Cells in those notebooks can accommodate SQL queries and present the results in tabular form or as relatively simple visualizations which, in turn, can be combined into a special dashboard view of the notebook. These capabilities accommodate rudimentary analysis and BI workloads, but in reality function more as a convenience feature in service of the data engineering and machine learning workloads at which Databricks has excelled.
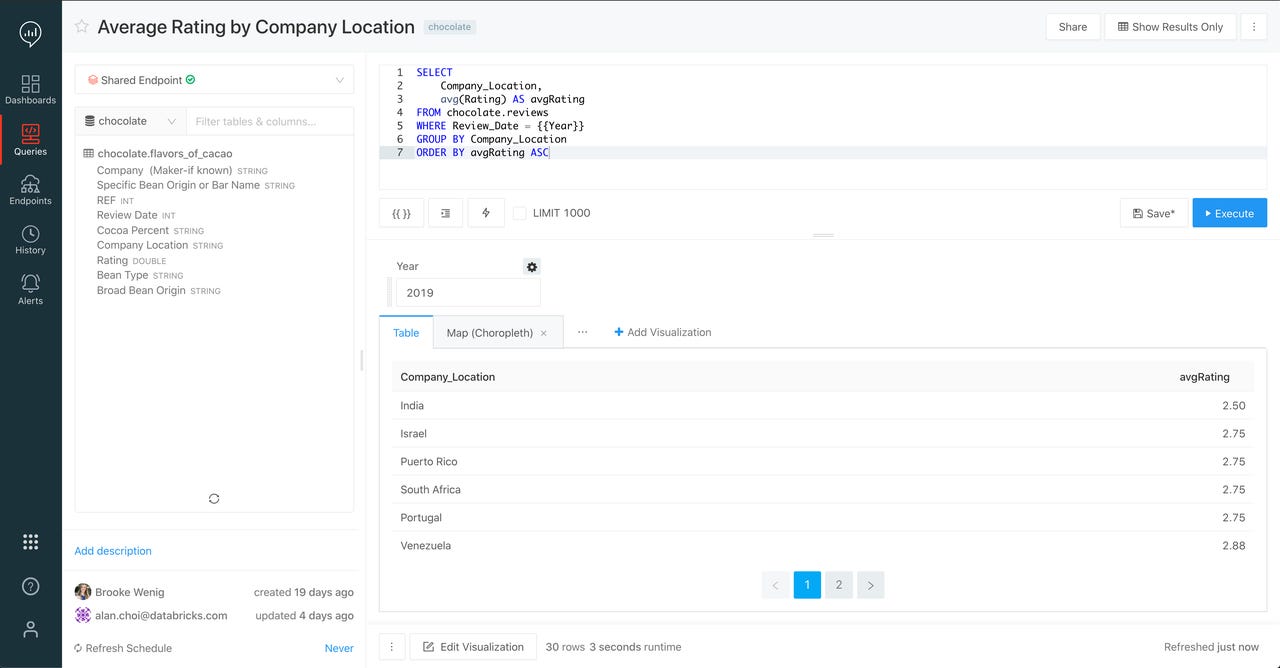
The new SQL Analytics Workspaces, meanwhile, are available in a completely separate view from standard Databricks workspace, via a sort of toggle menu, available by clicking a button at the bottom-left of the Databricks UI. They provide a full-screen query view, with robust syntax completion, a big productivity boost over the free-form text entry of a notebook cell. Also present is a list of existing databases, tables and columns, down the left side of the screen -- something that in the standard workspace requires moving focus away from the notebook. All of this is pictured in the figure at the top of this post.
Data visualizations are a major strength of the Analytics Workspace, with support for multiple visualizations per query. Each visualization can be added to an externally defined dashboard that exists independently of the saved query. All of this compares favorably to SQL notebooks, which either allow either a tabular view or a single visualization of the data returned by queries in the notebook. In addition, more visualization types are available in an Analytics Workspace query than in a notebook. Here's an example of one such visualization:
A Databricks SQL Analytics Workspace data visualization (a temperature heatmap is shown here), in the full-screen Visualization Editor view.
Analytics Workspaces also support rule-based alerting, driven off specific query result conditions, monitored at a configurable frequency. Full auditability of queries is also supported, through a dedicated History view within the Analytics Workspace.
Means to an endpoint
Capabilities of the SQL Analytics Workspace go beyond the user interface, alerting features and History view, though. New SQL Analytics Endpoints are special Databricks clusters, dedicated to serving BI/ad hoc analytics queries. While these clusters offer access to the same data visible to conventional clusters, they isolate their workloads, allowing greater concurrency. These clusters are provisioned based on "T-shirt" sizes (i.e. small, medium, large, etc.) avoiding the need to specify numbers and types of master and worker nodes.
Auto-scaling capabilities are available, allowing additional clusters to be provisioned, and de-provisioned, based on workload demands. The auto-scaling is governed by a customer-specified cluster count minimum and maximum. BI tools and other query clients simply connect to a single endpoint, and can remain blissfully ignorant of the existence of the multiple clusters. The Databricks platform will route all endpoint query requests to a particular cluster, in appropriate load-balancing fashion.
Start your engine
SQL Analytics endpoints make use of the Delta Engine and Photon technology added to Databricks in June. One way to think of Delta Engine is as an optimized C++ based rewrite of the Spark SQL engine. But it really goes beyond that, with Photon providing a vectorized query engine that, according to Databricks, offers fast parallel processing; up to 5x faster scan performance; a cost-based query optimizer; adaptive query execution that dynamically re-plans queries at runtime; and dynamic runtime filters that improve data skipping with greater granularity, to speed queries further still.
Prior to Delta Engine, Databricks added Delta Lake capabilities to Databricks (and subsequently open-sourced them to work with Apache Spark). Delta Lake added the ability to update and delete data efficiently, and do so within the context of ACID (atomicity, consistency, isolation, durability) transactions. Since most data lake technology, including underlying file formats, are geared to reads rather than writes, this was a significant addition, and added support for data versioning and "time travel" queries as a consequence.
Also read: Databricks introduces MLflow Model Registry, brings Delta Lake to Linux Foundation
Partner-friendly
Data Warehouse platforms have supported ACID transactions, and efficient updates and deletes all along, which has made them more versatile than data lakes in some respects. The combination of Analytics Endpoints, Delta Engine and Delta Lake adds real heft to Databricks' "data lakehouse" paradigm, making the data lake a serviceable alternative to a data warehouse in a majority of use cases.
Because this enablement is implemented at the infrastructure layer, the lakehouse optimizations become usable not just from the SQL Analytics Workspace, but from third-party BI and data integration platforms as well. Likely for that reason, BI juggernaut Tableau is participating in the Databricks announcement today, as is ELT (extract-load-transform) platform provider Fivetran.
Executives from both companies see the lakehouse model and its unifying effect as significant. Francois Ajenstat, Tableau's Chief Product Officer, said "As organizations are rapidly moving their data to the cloud, we're seeing growing interest in doing analytics on the data lake." Fivetran's CEO, George Fraser, called Databricks SQL Analytics "a critical step in...the unification of traditional SQL analytics with machine-learning and data science" adding that companies "should be able to...implement multiple analytical paradigms in a unified environment. The lakehouse architecture supports that."
While the likes of Teradata and Snowflake might take issue with the notion of the data lake as a primary analytics repository, it's clear Databricks and its partners see the model as legitimate. It's also clear that Databricks is prepared to invest what's needed to make the lakehouse model credible, and take its platform well past its beginnings as a commercially-enhanced cloud-based Spark service. With the addition of SQL Analytics, Databricks will have the opportunity to see that credibility rebutted or proven out. It will be more competitive, no matter what, though, and customers will benefit.