Facebook AI cuts by more than half the error rate of unsupervised speech recognition

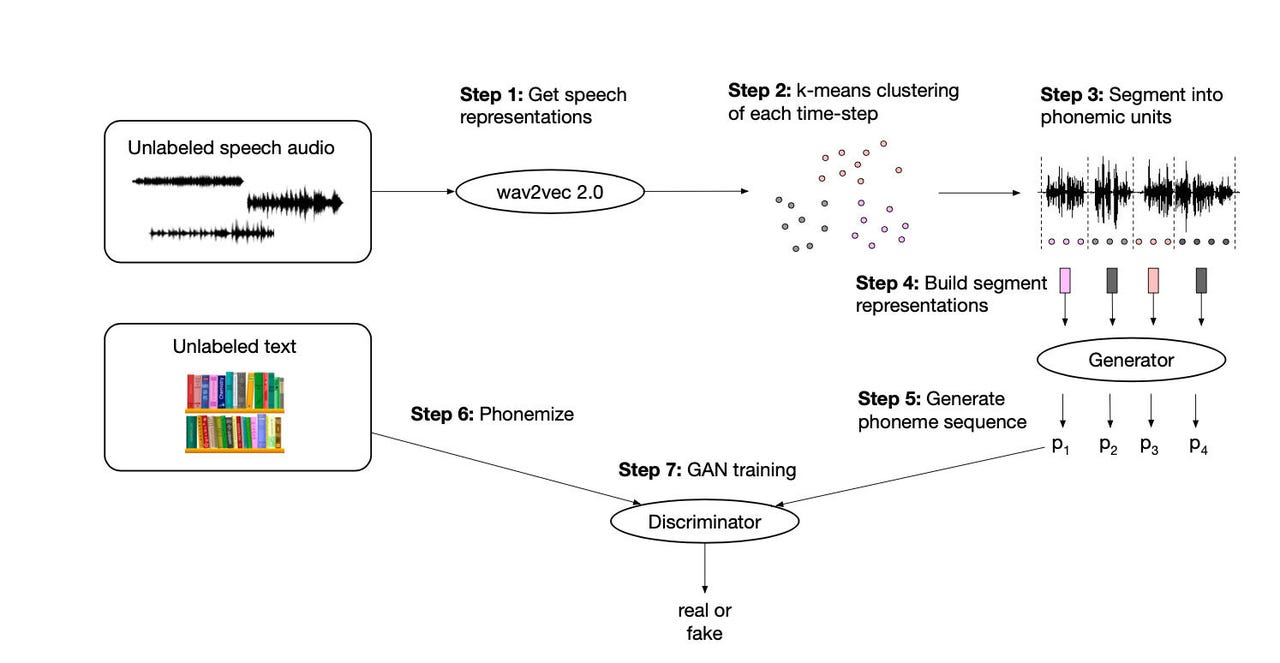
The program, wav2vec-u, is a combination of neural network functions. It uses a convolutional neural network to turn raw audio into vectors that can be manipulated inside of an attent-based Transformer that finds probability distributions of segments of speech. That probability distribution of segments of speech is then transformed into a probabilty distribution of phonemes by a genator, one half of a generative adversarial network, or GAN. The other half, the descriminator, compares inputs from valid, pre-formatted phoneme text, and the generator, and assigns them likeliness scores. Through repeated evaluations of the descriminator, the generator gets better and better at its generated probabilty distributions.
Speech recognition, meaning, programs that are able to detect spoken phonemes, is a fairly well established discipline in computer science that has been greatly advanced in the past twenty years by artificial intelligence.
The field has depended heavily on libraries of samples of speakers with each phoneme explicitly indicated, or "labeled." That has constrained some of the work to languages, such as English, where samples are readily available.
Facebook's artificial intelligence researchers on Friday announced they were able to get around that limitation by dramatically improving the error rate for what's called unsupervised speech recognition, where phonemes are detected without any prior examples.
Their work, called "wav2vec Unsupervised," or "wav2vec-U," is described in a paper, "Unsupervised Speech Recognition," by lead author Alexei Baevski and colleagues. There is also a companion blog post.
On the popular TIMIT benchmark, a collection of five hours of recorded speech, where a neural network must match the gold standard for parsing an audio file into its constituent phonemes, the authors cut the average error rate from 26.1 to 11.3, in terms of the percentage of phonemes that are guessed right. That's better than the best supervised programs, where the program was given cues by having samples of audio wave forms explicitly labeled with the exact phoneme.
Also: AI in sixty seconds
On a larger benchmark test, Librispeech, which has 960 hours of speech, the program did far better in terms of word error rate in its predictions than many supervised models, though not nearly as good as the best supervised models.
There's a big payoff for some languages that don't have specially prepared, labeled training data. The authors compare wav2vec-u on four non-European languages, Amharic, Swahili, Kyrgyz, Tatar, all of which are "low resource." Using the unlabeled audio samples from the four languages, their results show in some cases that they can do even better than the benchmark supervised-learning programs that used what little labeled data is available.
The present work builds upon several years now of published research by Baevski and colleagues at Facebook's AI unit. Baevski and team in 2019 introduced a way to predict the next sequence in an audio wave form of a spoken utterance, a program they called "wav2vec," a play on a previous breakthrough in natural language text processing from Google, called "word2vec." In both cases, the task is to turn some signal, either discrete, as in text, or continuous, as in audio, into a vector that's manipulable.
In the 2019 work, Baevski and colleagues showed how to turn an audio wave form into a prediction model for the next likely audio wave form in time. The trick was to apply the attention model made wildly popular by Google's Transformer and its descendants such as BERT. An audio wave form that has been put into a vector via a convolutional neural network can then be compared to other wave forms in a key-value system to arrive at the probability distribution of wave forms, and thereby predict sequences of wave forms. It's like outputting likely text with a Transformer.
The next stage, on tests such as TIMIT, is to transform the audio wave form into a probability over phonemes. It's really converting one probability distribution into another, is the way to think of it. In the previous work, the authors took their wav2vec and trained it to solve TIMIT by using readily available phoneme labels that annotate the hours of audio.
Also: Ethics of AI: Benefits and risks of artificial intelligence
In the present work, the authors use wav2vec without the labels. The key is that they add a generative adversarial network, a GAN, the program that has been used for things such as deep fake speech and image and video.
The wav2vec's audio probability disruption for a given audio snippet is transformed into a probability distribution over phonemes in the part of the program called the generator. The companion discriminator program assesses how likely that output from the generator is by comparing it to a whole bunch of real text that has been broken into phonemes. The back and forth, the adversarial challenge, improves the generator's probability calculations as the generator seeks to maximize the score given by the descriminator.
Keep in mind, the semi-supervised version of wav2sec, from last year, called wav2sec 2.0, still holds the top spot on TIMIT. Having explicit labeling still provides an advantage with a pre-trained attention model like wav2sec. But the point is pre-training programs like wav2vec are always something to build upon. The Facebook team appears to have created an impressive foundation, and so the wav2vec-u results can be expected to improve as the adversarial component is further melded with the pre-training part, or as other approaches are added to wav2vec.