Finding Web 2.0

First, a parable: At the heart of the Web from the very beginning was the concept of sharing information with others. Originally this vision encompassed the notion of information stored in "pages" accessible from the network and connected together by links. These links let readers effortlessly travel to related information somewhere else on the Internet, forming a sort of fabric. This conceptual fabric was of a relatively flat "Web" of servers and pages with hyperlinks gluing everything together. And though creating Web pages could be done by anybody, in practice it was done by a relative few. But early on, everyone liked what they saw and built on top of it.
Soon, real software behind to sit behind Web pages, at first just scripts and and some small programs but increasingly entire databases were connected to the Web through Web pages. Software on the Web then emerged that could carry out truly important and useful tasks, like conducting online commerce or letting people collaborate en masse. Still, most of the information was produced by the people creating Web sites and little was done to explicitly embrace the power intrinsic to the Web model; in other words, most of the opportunities to implicitly or explicitly capture knowledge from the Web's users was lost.
A few companies, including one which would ultimately dominate the Web, began to learn that by embracing the implicit nature of the Web, harnessing its information and audience, the nearly infinite knowledge of the Web's users in all their forms could then be leveraged into some of the most valuable products and services in the world (Amazon, eBay, Google).
Not longer after the early proliferation of big, sophisticated Web sites the Dot-com boom got well under way and everyone began moving more and more software and services to the Web. Things had their ups and downs for a few years but most Web sites remained powered by the software and content created by their owners, even though they were increasingly shrinking percentage of the Web. Blogs eventually became popular and to a lesser extent editable Web pages (wikis), just like the online forums and communites which had flourished a generation before and which remained well-used. But all was not perfect; most of the Web's output and potential value still remained untapped.
However, just like the coalescing of stars out of the early remnants of the Big Bang (here the Dot-com boom and bust), things cooled enough after the enormous initial growth burst to let this new vast audience condense around new sites that seemed to provide more value and useful content. And it was here that a new set of sites began to emerge fairly consistently, with oft surprising rapidity, and appeared to be powered almost purely by their audience. They actively exploited the potential of large networks to grow quickly and organically when well-designed feedback loops are present.
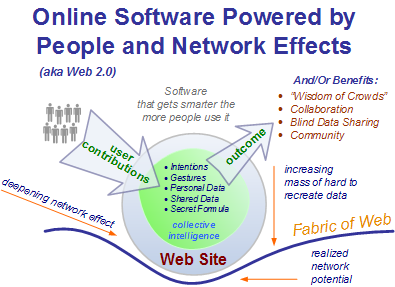
In this way, it began to be noted more and more that sites optimized specifically to embrace the Web's full potential to aggregate and grow larger audiences out existing (but interactive) audiences were unusually successful. Very similar in fact to a gravitational effect. These optimizations seemed to consist of activating the potential mass participation of millions of users, capturing it, and then actively harnessing it (attention, tacit contributions, implicit intentions, etc) directly back into vastly richer applications and sites that were generally much better, bigger, and more engaging than the sites of old. The early result was a series of very large (or important) -- and often volatile concentrations -- of content and users on the Web. Examples of these sites include -- but are in no way limited to -- BitTorrent, SourceForge, Wikipedia, Friendster, MySpace, YouTube, and even the blogosphere itself.
Sometimes dubbed "Web 2.0", this new, more refined model for creating online software reflected an improved understanding in the way that large networks can provide their full value. Specifically it reflected how to make use of them when a lot of users can actively contribute to them, directly or indirectly. This left the linear concept of Web traffic behind forever, with Reed's law cited on every corner. To be sure, ongoing changes in the audience of the Web also helped make the trend more pronounced and noticeable.
Furthermore, it is also believed now by some that these effects, now more isolated and understood, can also be applied "in the small" on more self-contained networks other than the Web (aka Enterprise 2.0 and Enterprise Web 2.0). The core elements of this new understanding of online software appears to be
- The Web model itself (HTTP, resources, and hyperlinks)
- Enabling emergence in virtually all its forms
- Network effects (exploit #1)
- Explicitly tapping into the potentially vast latent activity on the edge of our networks
Conclusion: The world's understanding of the Web was never quite the same again. Unfortunately no one could ever agree what to call this improved perception of the way the Web seems to work best. Regardless of this, the Web -- and the world -- continued on.
Why Do We Need a Term for What's Happening on the Web?
Phil Wainewright's post on Defining Web 2.0 earlier this week provoked me to write the above parable which, agree with it or not, I believe lays out the basis for the premise of Web 2.0. Though Phil's definition seems to put some possible end results of Web 2.0 as a definition, it's worth noting that while communities and collaboration are possible outcomes of Web 2.0, it's actually limiting to look at it that way.
In fact, great Web 2.0 software, like Google's search service, may not be social at all or have an explicit community behind it. Google's genius is thinking big and harnessing virtually all of the contributions on the entire Web to generate a uniquely valuable index of all the Web's content. This is what is meant by harnessing collective intelligence and this can mean everything from smart data defaults anonymous showing new users what more experienced users did, to all public, no private sharing of user contributions.
Sure, there are a dozen attendent concepts in the O'Reilly definition of Web 2.0that either fall out of the core principle of collective intelligence or that seem at first largely orthogonal, including rich Internet applications. But they all tie in somewhere. The problem is that our understanding of how to make the best of the Web still continues to evolve. Even our vocabulary and explanations need work as our understanding of what is happening improves. Thus, I think it's still too hard for most of us to explain yet what it all means in simple, layperson terms, or even to get folks to mutually agree to what's happening fundamentally. The great Web 2.0 definition debates will continue. In a few years, hopefully the evolution of the Web today will be a lot clearer and our software, our enterprises, and our lives will be the better for it.
Tired of Web 2.0 debate? I don't think we've seen the end of it. What's your definition of Web 2.0? Yes, really. :-)