Google's distributed computing for dummies trains ResNet-50 in under half an hour

Is it better to be as accurate as possible in machine learning, however long it takes, or pretty darned accurate in a really short amount of time?
For DeepMind researchers Peter Buchlovsky and colleagues, the choice was to go for speed of learning over theoretical accuracy.
Revealing this week a new bit of technology, called "TF-Replicator," the researchers said they were able to reach the accuracy of the top benchmark results on the familiar ImageNet competition in under half an hour, using 32 of Google's Tensor Processing Unit chips operating in parallel. The debut of Replicator comes as Google this week previewed the 2.0 version of TensorFlow.
The results from using TF-Replicator, the authors claim, approached the best results from some other projects that used many more GPUs, including prior work that employed 1,024 of Nvidia's "Tesla P100" GPUs.
The implication of the TF-Replicator project is that such epic engineering of GPUs can now be achieved with a few lines of Python code that haven't been specially tuned for any particular hardware configuration.
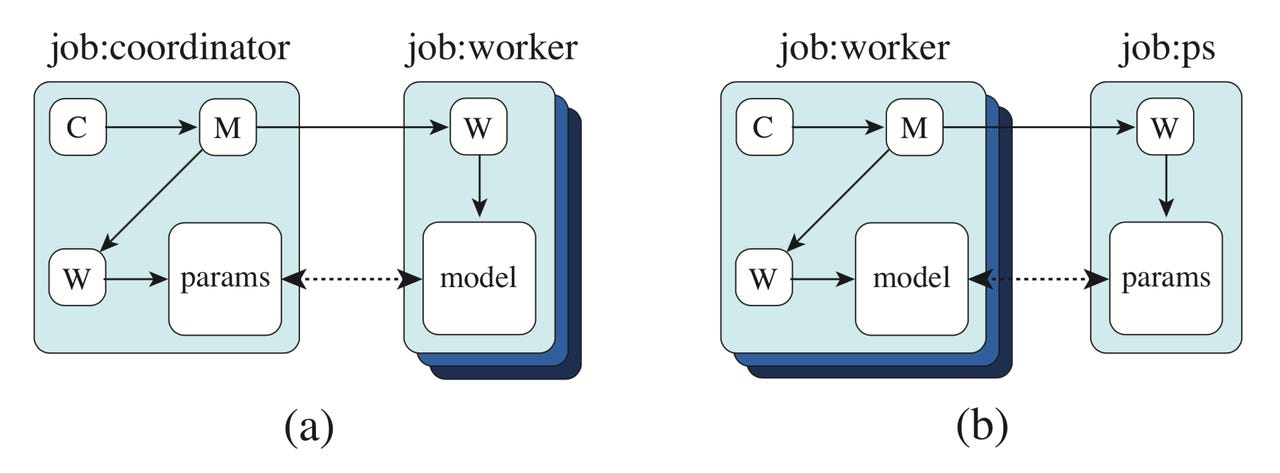
TF-Replicator can make multiple "workers" that either share a compute graph, as on the left, or have separate compute graphs of their own, as on the right.
The trick is basically to make Parallel Distributed Computing for Dummies, if you will. A set of new functions have been added to Google's TensorFlow framework that, DeepMind claims, "trivializes the process of building distributed machine learning systems" by letting researchers "naturally define their model and run loop as per the single-machine setting."
Also: Google launches TensorFlow 2.0 Alpha
The system is more flexible than a previous TensorFlow approach, called an "estimator," which imposed restrictions on the ways models are built. While that system was predisposed to production environments, the Google approach is for the R&D lab, for making new kinds of networks, so it's designed to be more flexible.
It's also meant to be much simpler to program than previous attempts at parallelism, such as "Mesh-TensorFlow," introduced last year by Google's Brain unit as a separate language to specify distributed computing.
The research, "TF-Replicator: Distributed Machine Learning For Researchers," is posted on the arXiv pre-print server, and there's also a blog post by DeepMind.
The working assumption in the paper is that they want to get to state-of-the-art results fast rather than to try and push the limit in terms of accuracy. As the authors point out, "Instead of attempting to improve classification accuracy, many recent papers have focused on reducing the time taken to achieve some performance threshold (typically ∼75% Top-1 accuracy)," using ImageNet benchmarks, and, in most cases, training the common "ResNet-50" neural network.
Also: Google says 'exponential' growth of AI is changing nature of compute
This rush to get to good results is known as "weak scaling," where the network is trained "in fewer steps with very large batches," grouping the data in sets of multiple thousands of examples.
Hence, the need to parallelize models to be able to work on those batches simultaneously across multiple cores and multiple GPUs or TPUs.
The authors set out to build a distributed computing system that would handle tasks ranging from classification to making fake images via generative adversarial networks (GANs) to reinforcement learning, while reaching the threshold of competent performance faster.
The authors write that a researcher doesn't need to know anything about distributed computing. The researcher specifies their neural net as a "replica," a thing that is designed to run on a single computer. That replica can be automatically multiplied to separate instances running in parallel on multiple computers provided that the author includes two Python functions to their TensorFlow code, called "input_fn" and "step_fn." The first one calls a dataset to populate each "step" of a neural network. That makes it possible to parallelize the work on data across different machines. The other function specifies the computation to be performed, and can be used to parallelize the neural network operations across many machines.
how TF-Replicator builds the compute graph on multiple machines, leaving the "placeholder" functions in the graph where communications will need to be filled in later, here represented by the dotted lines.
The authors note they had to overcome some interesting limitations. For example, communications between computing nodes can be important for things such as gathering up all the gradient descent computations happening across multiple machines.
That can be challenging to engineer. If a single "graph" of a neural network is distributed across many computers, what's known as "in-graph replication," then problems can arise because parts of the compute graph may not yet be constructed, which frustrates dependencies between the computers. "One replica's step_fn can call a primitive mid graph construction," they write, referring to the communications primitives. "This requires referring to data coming from another replica that itself is yet to be built."
Their solution is to put "placeholder" code in the compute graph of each machine, which "can be re-written once all replica subgraphs are finalized."
Results of various configurations of TF-Replicator for the ImageNet tasks on different configurations of hardware.
Must read
- 'AI is very, very stupid,' says Google's AI leader (CNET)
- How to get all of Google Assistant's new voices right now (CNET)
- Unified Google AI division a clear signal of AI's future (TechRepublic)
- Top 5: Things to know about AI (TechRepublic)
The authors describe results across various benchmark tests. In the case of the ResNet-50 ImageNet task, "we are able to match the published 75.3% Top-1 accuracy in less than 30 minutes of training," they write, adding that "these results are obtained using the standard TF-Replicator implementation, without any systems optimization specific to ImageNet classification."
On a GAN task, producing images, "We leverage TF-Replicator to train on much larger batches than can fit on a single GPU, and find that this leads to sizable gains in sample quality."
In the realm of reinforcement learning, they trained a simulated "agent" of movable joints to navigate various tasks. "A single TPUv2 device (8 cores across 4 chips) provides competitive performance compared to 8 NVLink- connected Tesla V100 GPUs," they write.
There are some interesting implications for future design of neural networks from this kind of distributed computing. For instance, in the case of reinforcement learning, rather than constructing higher-level representations of the robot's joints and their "velocities," they write, "the scalability of TF-Replicator allows us to quickly solve these tasks purely from pixel observations."
"Massive scalability," write the authors, with hundreds and thousands of layers in a neural network, is going to be more and more important in deep learning. TF-Replicator is Google's answer to the question of how researchers can more rapidly develop and iterate those big networks, starting from their workbench laptop, and spreading to distributed systems, with the least hassle.
Best of MWC 2019: Cool tech you can buy or pre-order this year
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.