Google’s AI surfs the “gamescape” to conquer game theory

The miracle of AI in the realm of playing games is encapsulated in the AlphaGo Zero program, which in 2017 was able to beat all human players of the ancient strategy game strictly by what's called "self-play," exploring different possible moves without any human tips. A revised version, AlphaZero, gained such general knowledge that it can now excel at not only Go but also chess and the game Shogi, Japan's version of chess.
Hence, neural nets can generalize across many games just by self-play.
But not all games, it turns out. There are some games that don't lend themselves to the AlphaZero approach, games known technically as being "intransitive."
For these games, Google's DeepMind AI researchers have figured out a new trick, a way of constructing a kind of super athlete by seeking diversity of moves and styles of play. The primary example, AlphaStar, recently won a match against the best human player of the strategy video game StarCraft II, as ZDNet chronicled last week.
Also: Google's StarCraft II victory shows AI improves via diversity, invention, not reflexes
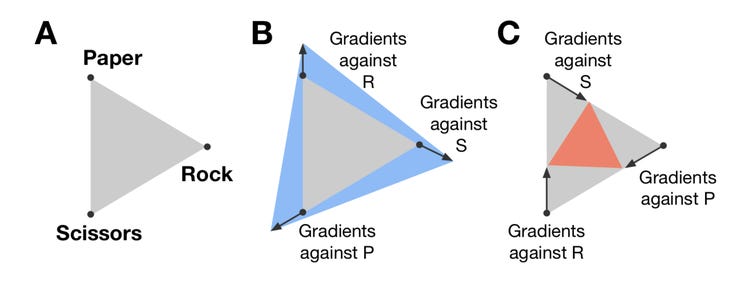
Even a relatively simple game like rocks, paper, scissors can be played as a problem of expanding the gamescape to find underlying strategies through diverse approaches.
While the research paper for that work is forthcoming, we have a bit of a teaser in a paper out Friday, "Open-ended Learning in Symmetric Zero-sum Games," posted on the arXiv pre-print server, authored by David Balduzzi and colleagues at DeepMind, whose previous work contributed in an important way to the StarCraft effort.
The problem being confronted with StarCraft II is that unlike chess and Go, it is not a game of perfect information, as they say, where all the opponent's moves can be seen. With perfect information, the effort to solve a game boils down to a search across possible actions given any state in the game by comparing moves of two players. A single "value function" of the right moves at the right times can be formulated just by comparing those two players.
In 2015, when AlphaGo first notched up wins against other Go programs, researcher Chris J. Maddison and colleagues at Google used as one of their critical tools the ability to tell the neural network about the ranking of the human players whose moves were the basis for the training. That provided "a dynamic bias to the network that depends on rank." That signal helped the neural net play to play better by "imitating" a better player of Go.
Also: China's AI scientists teach a neural net to train itself
With Starcraft II, such simple imitation doesn't work. There isn't full information, as in Go, and so there are things an opponent is doing that are unseen by the other player. As a result, games of hidden information are not "transitive" as with chess and Go, write Balduzzi and colleagues in the latest report. They do not boil down to a comparison of the winner and loser. In fact, "There is not necessarily a best agent," they write, and with multiple rounds of combat in any game, the computer may win some rounds against itself and lose others, "simultaneously improving against one opponent and worsening against another."
To solve that problem, the authors went in search of a way to analyze "populations" of game players. Their solution is something called a "gamescape," an extraction of knowledge about strategy from moves by different kinds of players.
Google DeepMind's researchers show visually how their algorithm, based on the so-called Nash equilibrium, fills out a "polytope" of strategies in games. The blue figure on the left-hand side best "fits" the polytope of solutions compared to the competing approaches, including standard "self-play."
The new work builds on work called "Nash averaging," introduced last year by Balduzzi and colleagues.
As they describe things in the new paper, they approach the problem of strategy not by "trying to find a single dominant agent which may not exist," but rather, "seek to find all the atomic components in strategy space of a zero-sum game.
"That is, we aim to discover the underlying strategic dimensions of the game, and the best ways of executing them."
Also: MIT lets AI "synthesize" computer programs to aid data scientists
In this light, all the moves of all the players yield bits and pieces about possible strategies that can expand the store of useful knowledge. This is represented as a "polytope," a Euclidean geometric figure off N dimensions, of which two-dimensional polygons and three-dimensional polyhedrons are the familiar examples. The polytope represents "all the ways agents [...] are-actually-observed-to interact." Put another way, the polytope of the gamescape is able to "geometrically represent the latent objectives in games."
They built algorithms that expand the knowledge base by forming a weighted mixture of players, using a statistical approach called a "Nash equilibrium," which finds strategies that beat or tie that mixture of players. "The idea is to encourage agents to 'amplify their strengths and ignore their weaknesses'."
All the choices of individual moves can still happen by the same neural network approaches used in AlphaGo, such as reinforcement learning and other things that use gradient descent, a stock optimization approach of machine learning.
The important part is that of "expanding the gamescape," finding more and more winning strategies. It turns out, they're often "niche" approaches, particular strategies that win in one point of the game but maybe not another. The algorithm "will grow the gamescape by finding these exploits, generating a large population of highly specialized agents."
The authors sum up their approach as "uncovering strategic diversity" in solutions. The principle is broadly applicable, it seems. Even a relatively simple game like rocks, paper, scissors is non-transitive, and can be played as a problem of expanding the gamescape to find underlying strategies through diverse approaches.
Must read
- 'AI is very, very stupid,' says Google's AI leader (CNET)
- Baidu creates Kunlun silicon for AI
- Unified Google AI division a clear signal of AI's future (TechRepublic)
The authors tested their new Nash-driven approach against a classic game theory example, Colonel Blotto, a game of military strategy, invented in 1921, which is non-transitive like StarCraft II. The approach "outperforms the other approaches," including traditional self-play of the form used in AlphaZero, "across a wide range of allowed compute budgets," they report.
This kind of "open-ended learning," as Balduzzi and colleagues term it, surpasses mere test-taking of the typical machine learning variant. Balduzzi & Co. believe their approach can "unify modern gradient and reinforcement-based learning with the adaptive objectives derived from game-theoretic considerations."
With Nash in hand, the authors pledge to take on "more complex games" in future, without tipping their hand as to what those may be.
Scary smart tech: 9 real times AI has given us the creeps
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.