How Facebook deals with the fact AI is a mess on smartphones

AI on mobile devices is a bit of a mess, and it's a headache for Facebook, which gets 90% of its advertising revenue off of people using its service on mobile.
Those are some takeaways of a recent research paper from Facebook's AI folks, who detail how they've had to come up with all manner of tricks to get around the hardware shortcomings of mobile.
That includes things like tweaking how many "threads" in an application to use to reach a common denominator across a plethora of different chip designs and capabilities. That means they can't generally "optimize" their code for a given device.
Despite all Facebook's enormous resources, there's a lot the whole industry needs to do, they write.
Also: AI on Android mobile phones still a work-in-progress
The paper, "Machine Learning at Facebook: Understanding Inference at the Edge," is posted on the publications page at Facebook's research site, and is authored by Carole-Jean Wu and 25 colleagues. It has been submitted to the IEEE International Symposium on High-Performance Computer Architecture, taking place next February in Washington, D.C.
The authors outline the two-pronged problem: More and more, there's a need to perform AI on mobiles. But the landscape of chips and software in the devices is a "Wild West," a mess of different parts, different software APIs, and generally poor performance.
There's a need for apps on "edge" devices, including smartphones but also Oculus Rift headsets and other devices, to perform "inference," the part of machine learning where the computer uses its trained neural network to answer questions.
Also: Facebook fakes the blur with AI to make VR more real
The authors cite things such as performing inference in real time on images that are going to be uploaded to Instagram as the kind of task that needs local processing to avoid the latency of going to the cloud to do inference.
But Facebook is up against frankly crummy hardware when considering the vast array of smartphones in the wild.
The company's "neural network engine is deployed on over one billion mobile devices," they point out, comprising "over two thousand unique SOCs [system on a chip, a semiconductor composed of not just a microprocessor but other compute blocks]." That's across ten thousand different models of phones and tablets.
The CPUs in these phones are not so great, on average: "The Nearly all mobile inference run on CPUs and most deployed mobile CPU cores are old and low-end." Specifically, this year, only one quarter of all smartphones they looked at are running a CPU that was designed in 2013 or later.
Also: Chip startup Efinix hopes to bootstrap AI efforts in IoT
And it's not just because there's a lot of old phones out there: "A major portion of these smartphones are sold in the recent one to two years."
Moreover, "there is no standard mobile SoC to optimize for," they lament, with the most-common chip having less than 4% market share. "The data are clear: there is no 'typical' smartphone or mobile SOC." There is an "exceptionally long tail" of chips.
Having an on-board "accelerator," such as a GPU, helps, but there aren't that many powerful ones out there.
"Less than 20% of mobile SoCs have a GPU 3× more powerful than CPUs." Most AI functions on mobiles "aren't even using the GPU," they write.
Also: AI startup Flex Logix touts vastly higher performance than Nvidia
DSPs, or digital signal processors, have the same shortcomings, they relate, and all these accelerators have little access to high-bandwidth memory. And there's very little support for the crucial vector structures at the heart of machine learning, and it will take years for most to gain that capability.
The other part of the mess is software: it's hard to program these chips for AI. There's one broad API that's useful on mobile, "OpenCL," but is "not officially part of the Android system," and isn't up to the same standards as other APIs. Other APIs, including "OpenGL ES," an adaptation of the desktop API for graphics, and "Vulkan," are promising, but only thinly deployed.
Also: AI Startup Cornami reveals details of neural net chip
Apple, they write, stands out: its "Metal" API for iOS runs on a consistent chip platform and the GPUs in those chips are higher-performance, on average, "making Metal on iOS devices with GPUs an attractive target for efficient neural network inference." Even then, however, the results of a "rigorous" examination of the speed of inference across six generations of Apple's "A" series chips shows that within each generation of chip there is still "wide performance variability."
"Programmability is a primary roadblock to using mobile co-processors/accelerators," they write.
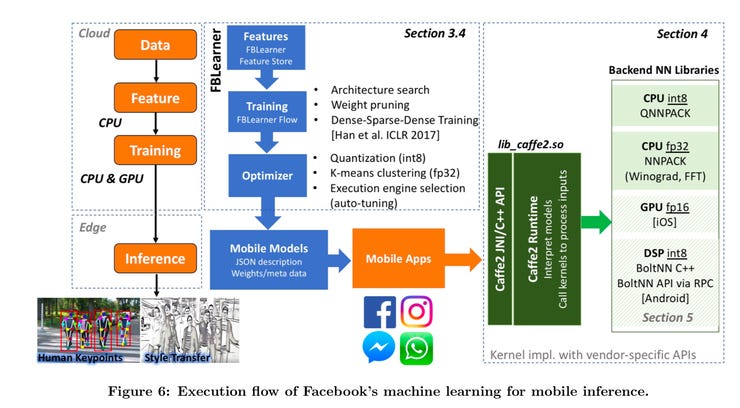
A system of different tools is used internally by Facebook's engineers to optimize neural networks for running on mobile devices. Despite all those resources, they find the mix of chips and software out there makes it difficult to create an optimal experience.
To deal with all this, the company makes the most of its in-house tools. For example, its "Caffe2" framework is "deployed to over one billion devices, of which approximately 75% are Android based, with the remainder running iOS" and is "optimized for production scale and broad platform support."
The newest version of Facebook's "PyTorch" framework, unveiled this year at the company's developer conference, is designed to "accelerate AI innovation by streamlining the process of transitioning models developed through research exploration into production scale with little transition overhead." It also supports the "Open Neural Network Exchange," or ONNX, specification backed by Microsoft and others.
Also: Facebook open-source AI framework PyTorch 1.0 released
Facebook has a whole "workflow" system internally that figures out how to optimize neural network models for the edge. It uses tricks such as "quantization, k-means clustering, execution engine selection" to improve performance on the targeted mobile device. Quantization, for example, turns values that are 32-bit floating point numbers into 8-bit integers, which run faster, but at the cost of lower accuracy.
The Caffe2 interpreter, which runs the model on the phone, does a whole bunch of other things, such as computing reducing the processing time of "middle layers" in a neural network via "spatial resolution tuning." Caffe2 also calls in two separate "back-end" systems that further optimize the running of convolutional neural networks, the workhorse of deep learning.
Also: The AI chip unicorn that's about to revolutionize everything has computational Graph at its Core
Even after all that, the authors relate that machine learning performance varies quite a bit across different "tiers" of hardware. Some low-end models of phone actually do better than the mid-tier models nominally more powerful. Benchmarking all this for the real world is not realistic because "it would require a fleet of devices." So they can't fully anticipate the performance hit of things such as aging batteries in mobiles.
Must read
- 'AI is very, very stupid,' says Google's AI leader (CNET)
- Baidu creates Kunlun silicon for AI
- Unified Google AI division a clear signal of AI's future (TechRepublic)
The authors conclude with several suggestions. Data scientists will need to spend a lot more time figuring out ways to produce neural networks that can be more efficient. That means there's a big role for "architecture search" approaches such as "BayesOpt" and "AutoML," they write.
On the chip side, "more research and engineering effort" needs to go into "making existing mobile GPU and DSP hardware more amenable to processing DNN inference."
While more specialized hardware promises to help, if it doesn't provide a 50x performance boost, they write, "it is unlikely most of these accelerators will actually be utilized when found on mobile devices."
They also end with a tantalizing thought: just optimizing any one thing is not going to do it. "Maybe this is a sign that computer architecture is shifting more towards computer system organization."
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.