Hug or high-five? MIT algorithm studies "The Office" to predict social interactions

Knowing when someone will greet you with a hug, kiss or handshake can be hard enough for humans -- but it's getting a little easier for computers.
A group of researchers at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) has developed a vision algorithm to predict human interactions like hugs and high-fives. Using deep-learning techniques to assess patterns, the algorithm was trained on more than 600 hours of YouTube videos and television shows like "The Office" and "Deparate Housewives" to anticipate one of four actions during a greeting: a handshake, hug, high-five or kiss.
"Humans automatically learn to anticipate actions through experience, which is what made us interested in trying to imbue computers with the same sort of common sense," CSAIL PhD student Carl Vondrick said in a statement. "We wanted to show that just by watching large amounts of video, computers can gain enough knowledge to consistently make predictions about their surroundings."
Vondrick is the first author on a related paper that he is presenting this week at the International Conference on Computer Vision and Pattern Recognition.
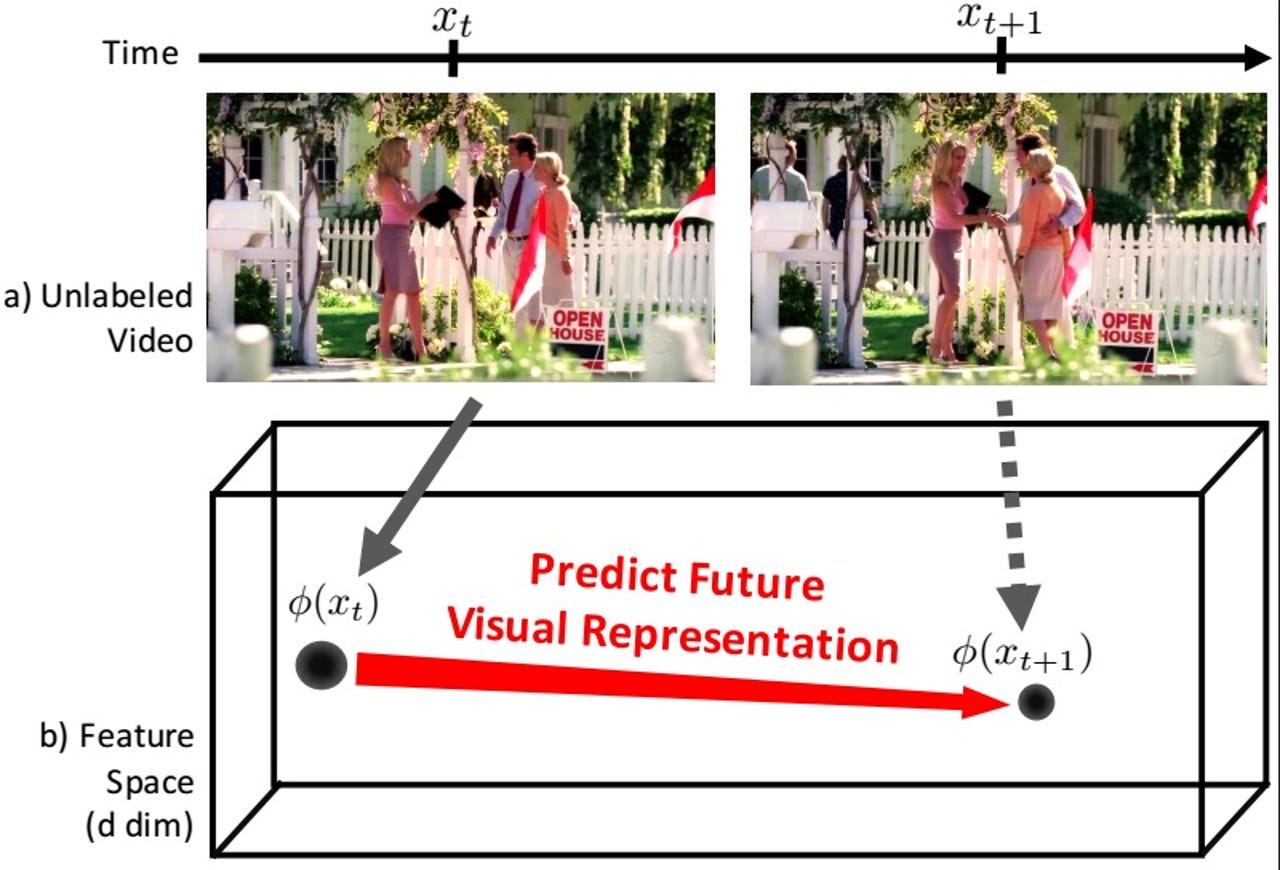
After its 600 hours of training, the algorithm accurately predicted one of four greetings more than 43 percent of the time -- better than the 36 percent accuracy rate of previous algorithms. The research team produced better results by building an algorithm that predicts "visual representations" -- in other words, a complete scene. Other versions of predictive computer vision either study individual pixels in an image to create a photorealistic "future" image, or they rely on humans to label scenes in advance -- an impractical solution for large scale applications.
The MIT team conducted a second study in which an algorithm predicted what object is likely to appear in a video five seconds later -- for instance, what object a person might take out of a microwave. While its precision rate in that study was just 11 percent, it was 30 percent more accurate than baseline measures.
While the algorithms aren't yet accurate enough for practical applications, the researchers anticipate they could be used for more than just building polite robots. A better vision algorithm could be used, for instance, build emergency response systems that predict injuries, or any other scenario that requires navigating human environments.
"There's a lot of subtlety to understanding and forecasting human interactions," Vondrick said. "We hope to be able to work off of this example to be able to soon predict even more complex tasks."