I got 99 data stores and integrating them ain't fun

No fun
You know the story: corporation grows bigger and bigger through acquisitions, organograms go off the board, IT assets skyrocket, everyone is holding on to theirs trying to secure their roles, complexity multiplies, chaos reigns and the effort to deliver value via IT becomes painstaking. This may help explain why a lead enterprise architect in one of Europe's biggest financial services organizations is looking for solutions in unusual places.
Let's call our guy Werner and his organization WXYZ. Names changed to protect the innocent, but our fireside chat in Semantics conference last week was real and indicative of data integration pains and remedies. WXYZ's course over the years has resulted in tens of different data stores that need to be integrated to offer operational and strategic analytic insights. A number of initiatives with a number of consultancies and vendors have failed to deliver, budgets are shrinking and personnel is diminishing.
Granted, a big part of this has nothing to do with technology per se, but more with organizational politics and vendor attitude. But when grandiose plans fail, the ensuing stalemate means that in order to move forward a quick-win is needed, one that will ideally require as little time and infrastructure as possible to work, can be deployed incrementally and scale as required eventually. A combination of well-known concepts and under the radar software may offer a solution.
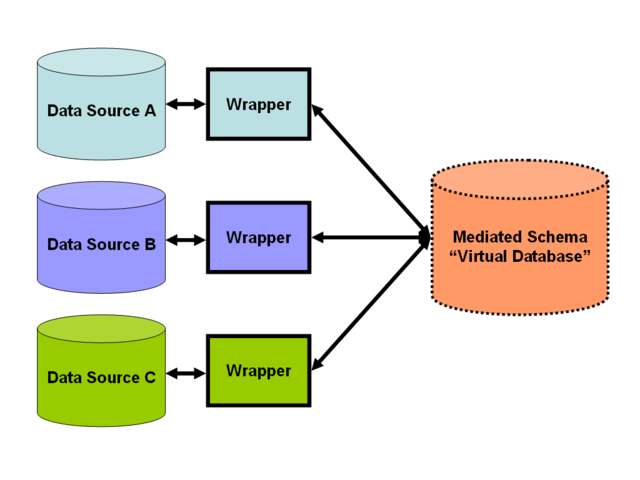
Data integration leverages a mediated schema against which users can run queries, wrapper code and mappings.
Other people's schemata
What do you do then, when you cannot afford to build and populate a data lake, or yet-another-data-warehouse? Federated querying to the rescue. This means that data stay where they are, queries are sent over the network to different data sources and overall answers are compiled by combining results. The concept has been around for a while and is used by solutions like Oracle Big Data. Its biggest issues revolve around having to develop and/or rely on custom solutions for communication and data modeling, making it hard to scale beyond point-to-point integration,
Could these issues be addressed? Data integration relies on mappings between a mediated schema and schemata of original sources, and transforming queries to match original sources schema. Mediated schemata don't have to be developed from scratch -- they can be readily reused from a pool of curated Linked Data vocabularies. Vocabularies can be mixed/matched and extended/modified to suit custom needs, balancing reuse and adaptability.
Mappings from local data store schemata to global data models still have to be developed, and this is where things get interesting. Initially it was D2RQ that popularized a language to map relational schemata to Linked Data vocabularies, along with the software to expose relational data stores as SPARQL endpoints returning RDF. Then W3C standardized such mappings in R2RML, making mappings interchangeable and promoting adoption.
Truly RESTful or not, would you turn down an API that comes for free? This is what you get with data sources accessed via SPARQL
API for nothing, HATEOAS for free
Using SPARQL may not sound very attractive, as it typically means having to learn another query language. However SPARQL should be relatively straightforward for people familiar with SQL, and there are certain perks that come with it as well. SPARQL can do pretty much everything SQL can and then some. As it works with a graph underlying model, it offers capabilities for traversing graphs and even constructing virtual ones on demand.
But SPARQL is more than a query language: it doubles as an HTTP-based transport protocol. What this means is that any SPARQL endpoint can be accessed via a standardized transport layer, which coupled with readily accessible data models and documentation make for an out-of-the box API mechanism for sophisticated CRUD operations. RDF results can be returned in JSON, XML, or CSV/TSV, and RDF entity identifiers are URIs.
So we have hypermedia-driven nodes providing information to navigate their interfaces dynamically by including hypermedia links with the responses ... looks like a RESTful, HATEOAS API! You could argue that the HTTP verbs are eclipsed by SPARQL constructs here, but does it matter that much when you get it for free?
Minting data with URIs provides more advantages, as it allows data to be unambiguously referenced across applications. Additional application specific APIs can be developed and refer to that data (as well as external data) using JSON-LD. Additional non-relational data sources can be integrated via XML2RDF and CSVW tooling.
What about tooling support for this lightweight data integration scenario then? D2RQ works, and in terms of commercial offerings we have the likes of Cambridge Semantics, Capsenta, FluidOps, SWC and OpenLink Software. Given the benefits Linked Data integration has to offer, it may be an option worth considering for vendors and users alike.
Internet of Things
Revelytix, now acquired by Teradata, also had an offering called Spyder in this space. Spyder has been open sourced, but unfortunately we were not able to locate it online.