Kyligence launches revamped cloud-native OLAP-on-big-data platform

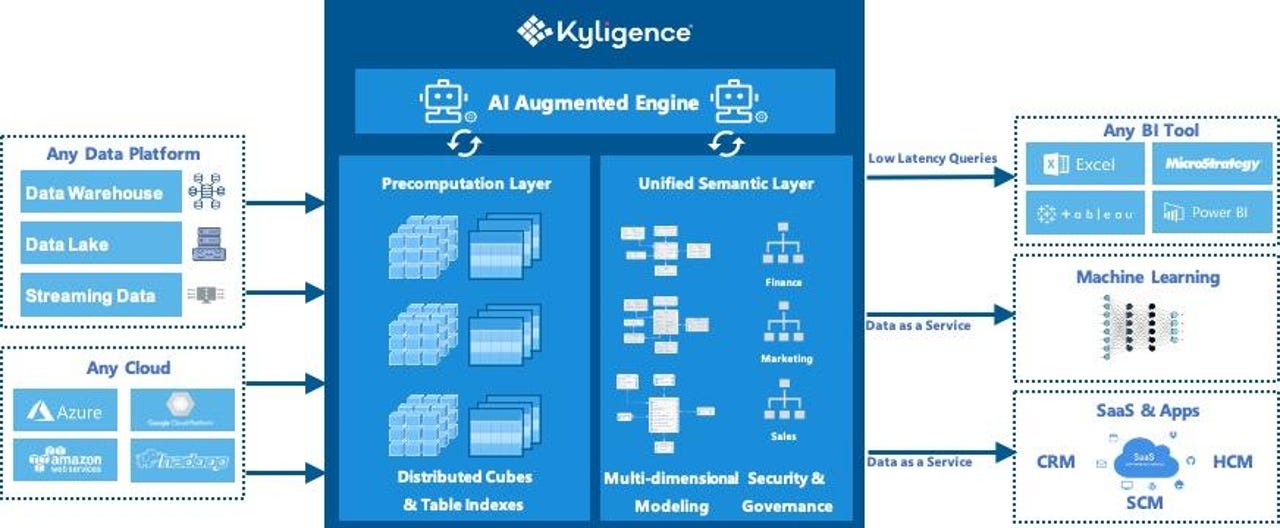
Kyligence architecture diagram
Before the era of big data, there was the era of business intelligence (BI). It was based on many of the same tenets, but focused more on formal data models and analysis of data at a summarized level. Ever since the dawn of big data, which did away with many of these modeling formalities, a question has remained: can the BI approach be made compatible with the volume and accompanying extreme granularity of big data?
OLAP redux
One company that believes the answer is yes is Kyligence, whose base open source OLAP- (OnLine Analytical Processing) on-big-data platform, Apache Kylin, does indeed blend the two approaches. Originally, Kylin and Kyligence were based on Hadoop and Hive (similar to the early versions of OLAP on big data player AtScale), but Hadoop's MapReduce foundation created challenges in providing performance that was able to support truly interactive analysis.
Also read: AtScale expands COVID-19 data semantic model
But today, Kyligence is announcing Kyligence Cloud 4, completely rearchitected for the modern big data stack (including Apache Spark and Parquet), and the cloud. It's available on Microsoft's cloud-based Azure Marketplace; it can also run on Amazon Web Services and will soon be available on that cloud's marketplace as well. The platform is optimized for Azure Data Lake Storage-, and Amazon S3-based data lakes, and can also query cloud data warehouses and other data sources. Storage and compute are scaled separately, and the service's billing model is based on data volume.
Hybrid of modern and classic
To achieve optimized performance, Kyligence combines the columnar storage format of Apache Parquet with distributed aggregate indexes. The latter are essentially pre-calculated aggregations, which are OLAP's hallmark. Kyligence also utilizes what the company calls "smart query routing," where the back-end data source is queried directly, when detail-level data is needed. This is the right approach for big data-based BI: pre-calculate where you can to minimize query times, and go to the source repository for detail-level data and/or to push down the query effort to the back-end platform when appropriate.
Because of this approach, Kyligence says its aggregation layer "delivers sub-second query response times against datasets of hundred of terabytes to petabytes." And unlike "old school" OLAP, which requires such aggregations to be specified when the cube is designed, Kyligence uses a machine learning-assisted approach that observes queries issued against the back-end data and creates aggregations automatically, on-the-fly.
Clearly, then, Kyligence's idea is to bring back the performance gains OLAP can bring, without imposing the modeling burden that analysts and users might normally associate with the OLAP approach. On the other hand, formal design and modeling is an option as well, with support for what the company calls its Unified Semantic Layer (a term familiar to BI practitioners). Kyligence says that one customer has already migrated over 100TB of data to a single Kyligence cube and that another ported some 1200 IBM Cognos cubes onto just two Kyligence cubes.
BI technologies in effect
Kyligence can be queried using SQL, MDX, or a RESTful API, thus allowing standard BI tools to query it. The company makes optimized connectors available for major BI platforms. Those connectors use a direct-connect approach, thus allowing queries to flow-through to Kyligence, and avoiding the building of materialized tool-side BI models on top of the one Kyligence already provides.
Kyligence Cloud 4 is immediately available on AWS and Azure, including through the Azure Marketplace.