Microsoft fleshes out its Azure Data Lake plans; readies public preview

While Microsoft announced plans for its Azure Data Lake service in April at its Build conference, it wasn't until today that company officials made clear what would power its coming enterprise-wide cloud data repository.
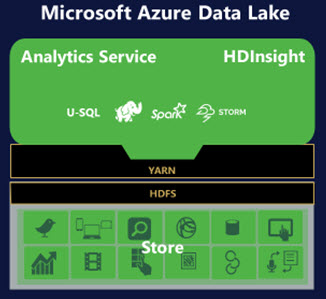
We've known since April that Azure Data Lake -- Microsoft's self-described "hyperscale repository for big data analytic workloads in the cloud" -- would be compatible with the Hortonworks Hadoop Distributed File System (HDFS). At that time, Microsoft advised those interested to sign up for notification for the upcoming preview of the Azure Data Lake store.
Earlier this year, I heard from some of my contacts that Microsoft was testing privately what turned out to be the main components of Azure Data Lake. There was an analysis-engine piece codenamed "Kona"; a storage-engine piece codenamed "Cabo"; and a new SQL-friendly language, known as SQL-IP. Today, Microsoft took the wraps off those same pieces (with new, official names): Azure Data Lake Analytics; Azure Data Lake Store; and U-SQL.
Microsoft officials said today that the analytics engine and store will be available in public preview later this year.
Azure Data Lake will work with HDInsight, Microsoft's Hadoop-on-Azure service for Windows and Linux. (The Linux version of HDInsight, which works on Ubuntu, is generally available as of today; the Windows version has been available since 2013.)
Microsoft's overarching goal for Azure Data Lake is to allow customers "to extract the maximum insight from all data, anywhere," said T.K. "Ranga" Rengarajan, Microsoft's Data Platform Corporate Vice President.
While my tipsters have been saying for a while that Microsoft had planned to turn its own Cosmos service into something that those outside Microsoft could use as a paid service, Microsoft isn't simply taking its Cosmos infrastructure and making it commercially available on Azure.
Cosmos is Microsoft's massively parallel storage and computation service that handles data from Azure, Bing, AdCenter, MSN, Skype and Windows Live. According to a recent Microsoft job posting, there are 5,000 developers and "thousands" of users inside Microsoft using Cosmos.
Cosmos was built using Microsoft's Dryad distributed-processing technology. Microsoft uses Cosmos internally to process telemetry data; to perform analysis and reporting on large datasets, such as those created via Bing and Office 365; and to curate and perform back-end processing on many kinds of data. A lot of the data used for these various purposes is shared. Queries on this data can run on anywhere from one to 40,000 machines in parallel.
Instead, Microsoft has built for Azure customers a variation of Cosmos that doesn't use Dryad. The analytics piece is built on Apache YARN and the store is HDFS compatible. U-SQL, which Microsoft describes as "a new query language that unifies the ease of use of SQL with the expressive power of C#," takes its cues from Microsoft's internally used and developed SCOPE language for parallel query execution.,
"This (Azure Data Lake) is more ambitious than Cosmos," said Rengarajan. "It's also inspired by Apache Spark, data warehousing, and more. We've been thinking about this problem for years."
While Microsoft's internal usage of Cosmos has taught the company a lot about parallel computation, "Cosmos ws built in a different way and in a different age," Rengarajan said. These days, users are looking for solutions as to how to debug something running on thousands of machines in a few hours or how to execute a query across thousands of machines, but still have it look very familiar, he said.