SAP unveils its Data Hub

The Strata Data conference kicks off tomorrow at New York City's Javits Convention Center. And at SAP's still-new Manhattan office, located just a block east and 4 blocks south of Javits, the company introduced the world to a new offering in its formidable data stack today: SAP Data Hub.
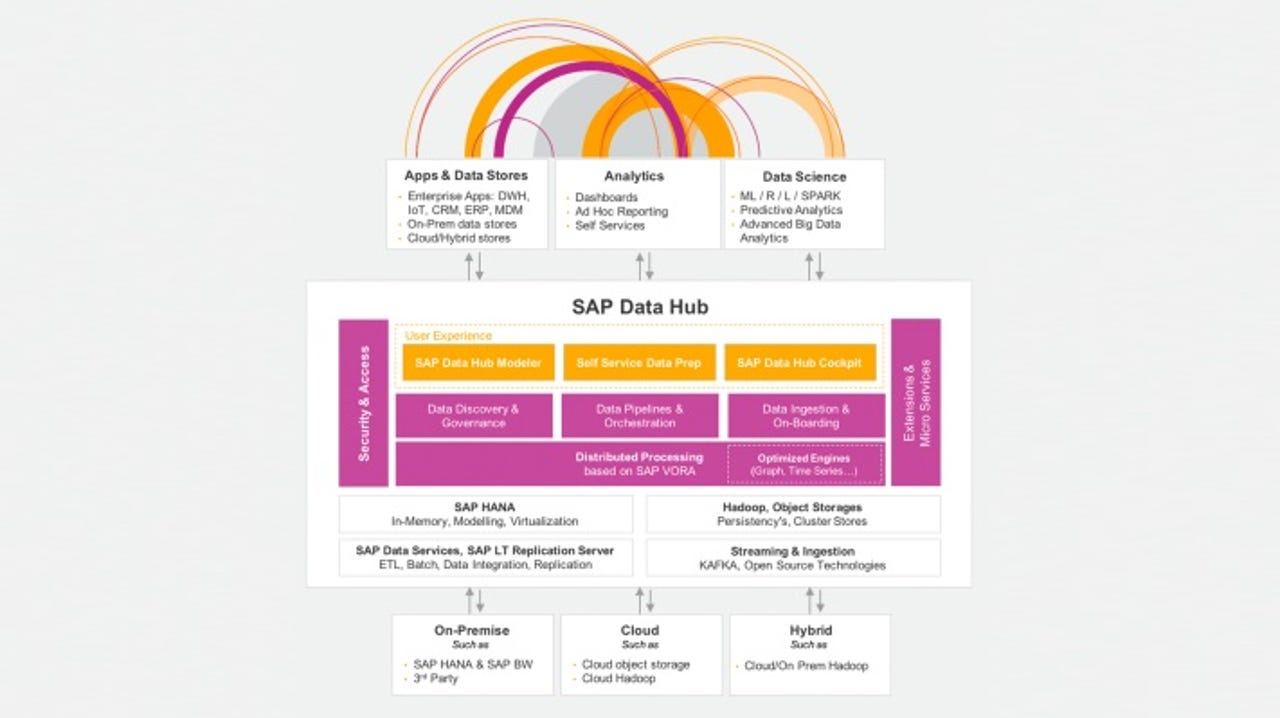
SAP Data Hub "marketecture" diagram
The problem in my attendance at that presentation was that I was on-site with a client in Jersey City, NJ today. And while that client's office is at the water's edge on the Hudson River, with lower Manhattan in a close, clear line of sight, getting to the event wasn't easy.
Can you get there from here?
To do it, I had to take two different transit systems: the PATH, which connects Manhattan to a few small cities in New Jersey, and then the New York City subway. There's an indoor connection, under the World Trade Center, between the two systems, but it's still a bit of a hike, and you have to pay a second time when you enter the NYC Subway System.
Well, after listening to SAP's presentation for a while, it struck me that traveling across state lines, and over two different rapid transit systems, is not dissimilar to integrating databases from two different vendors. It should be pretty seamless, but it can be quite complex, and expensive.
If you've done it before, then you know the tricks and workarounds, and you'll likely have budgeted for the extra expense. You can make it work, but it's arduous. That's as true for crossing the Hudson River, and traveling up Manhattan's West Side, by public transportation, as it is for moving data from a Hadoop data lake to your data warehouse.
While the NYC Regional Plan Association fails to solve the problem on the transit side, SAP Data Hub is designed to alleviate this kind of integration difficulty on the data side. It does so by providing a platform where numerous data sources can be connected through pipelines, built with a graphical designer. With such integration in place, a data catalog is built in the background, enabling governance of that data and sharing of the data sets cataloged. SAP even offers a cockpit view of all that data harmony, to make it feel more within reach.
SAP Data Hub Cockpit View
Like a transit hub designed to connect different transportation systems, and facilitate end-to-end trips across them, SAP Data Hub is designed to connect numerous data sources, both SAP and non-SAP, on-premises and in the cloud, and provide a way for data to get to its destination. SAP says Data Hub uses an open architecture, allowing customers to plug in their own connectors and Web APIs, to create Data Hub "operators" for use in pipelines.
In my commute from Jersey City, as I walked through the World Trade Center's Oculus, designed as a transit hub, to transfer from PATH to Subway, I also noticed that the passageway, ostensibly offered as public service, was really there to get me to spend money at the high-end shops in the complex. Likewise, the SAP team at the event was pretty candid that the configuring the pipeline data destination to be SAP HANA, so that the aggregated data could live there, would be a common scenario.
Also read: SAP HANA does Big Data...with ERP, CRM and BI savvy
Heard it through the pipeline
How easy are these pipelines to design? SAP actually demoed the product at the event and showed a pipeline already built. The designer uses the same UI metaphor seen in products like Microsoft's SQL Server Integration Services and Alteryx Designer. A toolbox of sources, operators, and destinations on the left and a canvas in the middle, with lots of boxes and connecting lines. If other products like this exist, why is SAP offering another one?
The company says Data Hub is different for a number of reasons. Number one, pipeline processing is done on SAP Vora, SAP's data processing platform based on Apache Spark. And, as we've pointed out already, the option to store the processed data in HANA is available. For SAP shops, each of these SAP-centric architectural choices might make a great deal of sense.
Also read: SAP Introduces Spark-based HANA Vora
Let my data stay
But SAP pointed out that it's not all about them. The company spokespeople mentioned that a good 90% of the data that Data Hub will process will come from non-SAP systems, and that Data Hub is designed to leave that source data in place (even if the aggregated data goes into HANA). Leaving data where it is, is important. Data movement is time-consuming and expensive. It creates superfluous copies of the data, which can be a compliance nightmare.
Data Hub will use "push down" processing where possible, coaxing the source systems to process the data in place as much as possible before pushing results to Data Hub. I can identify with this: instead of commuting to the SAP event in Manhattan, I might have stayed in my client's air-conditioned, Jersey City offices and watched the presentation over a live stream. Moving me was expensive and time-consuming. Some push-down processing would have been welcome.
Data integration: simple it ain't
But I digress. Once the overall rubric of SAP Data Hub is understood, the world seems a little simpler, and vast data landscapes seem less insurmountable. In keeping with this serenity and calm, during the product demo, the audience saw a pipeline like the one pictured below.
A Data Hub Pipeline
That orchestration makes something complex look pretty simple: moving data from Apache Kafka to HDFS (the Hadoop Distributed File System) and then on through some JavaScript code and into to SAP HANA, seems straightforward. Actually, it reminded me of the "strip map" displayed in PATH train cars.
PATH System Map
The thing is, PATH s a tiny system, meant mostly to link bigger ones and most end-to-end trips aren't so neatly illustrated. Most data integrations aren't so simple or linear. They have more branches, twists and turns. Kind of like the NYC Subway map, just a tiny piece of which is shown below.
NYC Subway map, showing Midtown Manhattan
You'll note the Javits Center is highlighted at the lower left. That's fitting, because at least one other company exhibiting at Strata Data this week will show a data integration product of its own: Hortonworks, which announced its Hortonworks Dataplane Service on Monday.
Also read: Hortonworks DPS reaches out to the virtual data lake
You messed it up, you clean it up
And it won't just be SAP and Hortonworks. The problem of data sprawl has been acute for decades. The advent of data lakes and NoSQL databases has made it geometrically worse. Companies in the data space have, to be honest, created a mess. And now companies in the data space are providing tools to help clean the messes up...or at least document them and make them navigable.
One day, maybe the same fare card will work across NYC's subways and buses, its new ferry lines, the PATH system and all commuter railroads. And maybe data integration will be easier too. Until then, we'll need products to make it easier and experts who know the tips and tricks required to make it work well. Step in, and watch the closing doors.