Teradata open sources Kylo data lake management software

Teradata said it is going to open source its Kylo data lake management platform via its Think Big Analytics unit.
Kylo (code on GitHub) has been based on experience working on 150 data lake projects for Fortune 1000 companies, said Teradata. Kylo emerged from code delivered by Think Big Analytics, which was acquired by Teradata in 2014. Teradata plans to offer services, training and support built on Kylo.
Teradata's Think Big unit is releasing Kylo, which enables data lakes on Hadoop, NiFi, and Spark, in a bid to create a more turnkey approach. Data lakes are large storage repositories that hold information in its native format until needed.
More big data: Streaming data juggernaut Confluent announces $50M in Series C funding | Making the Business Case For Big Data | How to Implement AI and Machine Learning | Digital Transformation: A CXO's Guide | TechRepublic: How big data analytics help hotels gain customers' loyalty | IBM Watson: The smart person's guide
According to Teradata, Kylo has allowed customers to build out data lakes in a production environment in as little as nine weeks. Typically, that build cycle was six months to a year because enterprises struggle with expertise.
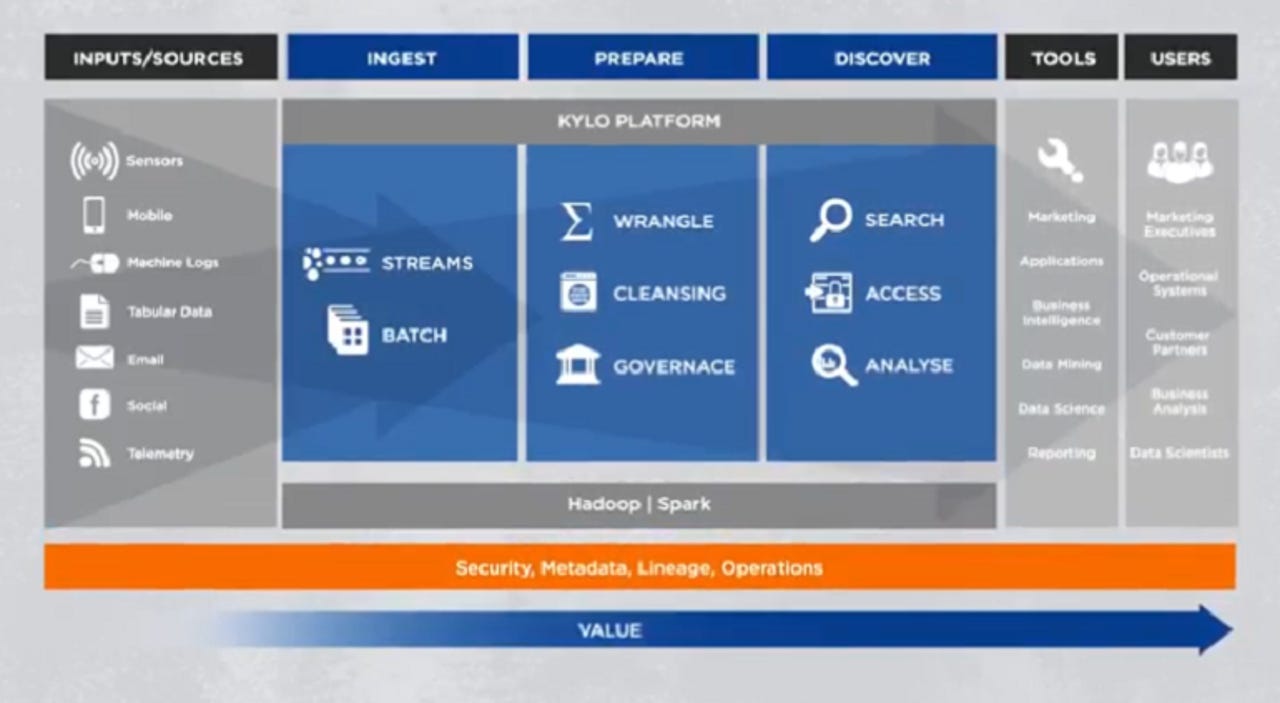
Kylo's key features include a user interface for self-service data ingestion and wrangling without coding. The self-service approach allows enterprises to deploy engineers and data scientists on more business data.
Teradata also argues that Kylo is more secure relative to custom approaches. Kylo's security approach revolves around governance and securing data at rest.
Videos on big data: