Pitfalls to Avoid when Interpreting Machine Learning Models

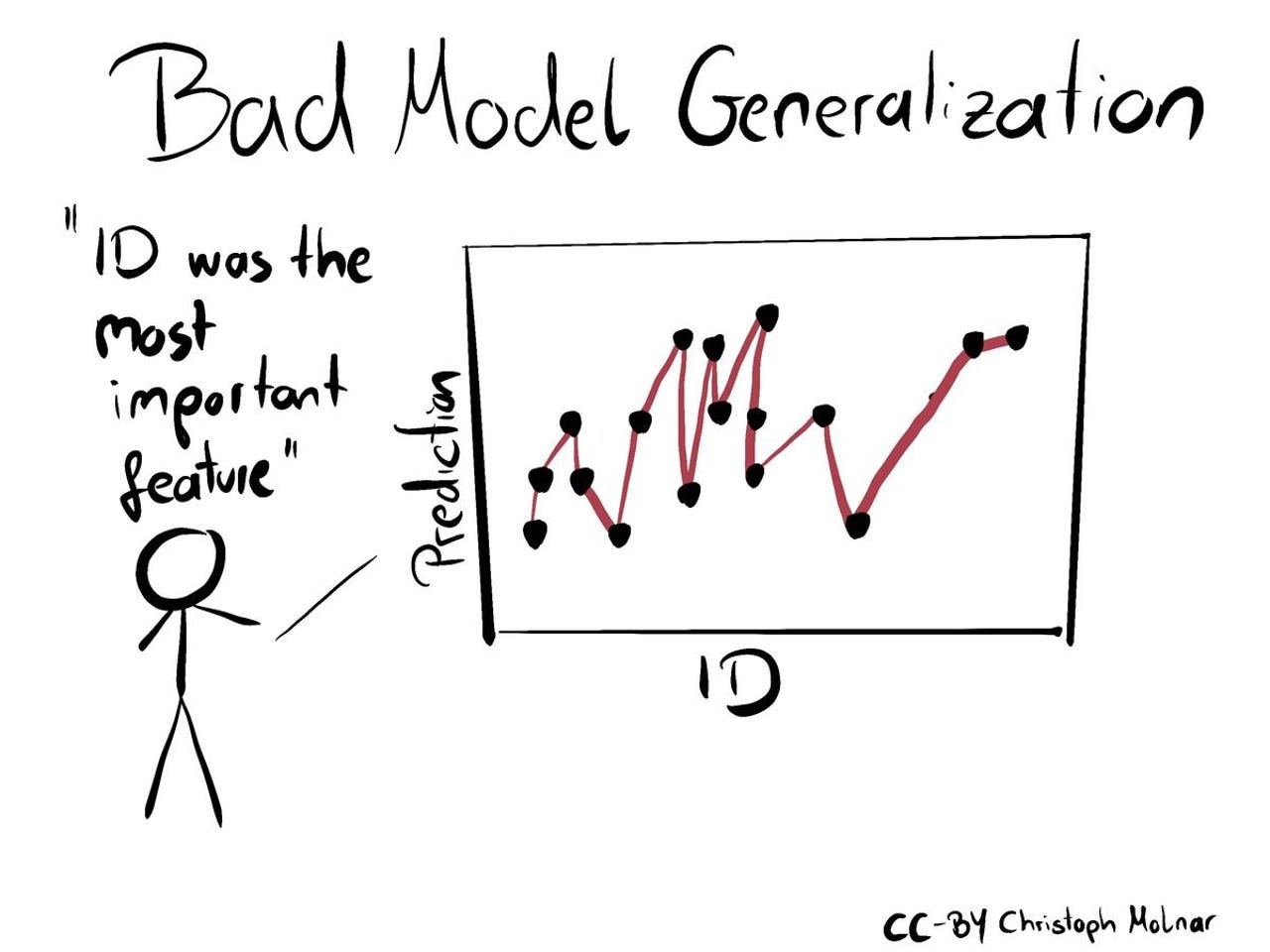
1-bad-model-generalization
Any interpretation of relationships in the data is only as good as the model it is based on. Both under- and overfitting can lead to bad models with a misleading interpretation.
=> Use proper resampling techniques to assess model performance.
2-unnecessary-use-of-ml
Don't use a complex ML model when a simple model has the same (or better) performance or when the gain in performance would be irrelevant.
=> Check the performance of simple models first, gradually increase complexity.
3-1-ignoring-feature-dependence
When features depend on each other (as they usually do) interpretation becomes tricky, since effects can't be separated easily.
=> Analyze feature dependence. Be careful with the interpretation of dependent features. Use appropriate methods.
3-2-confusing-dependence-with-correlation
Correlation is a special case of dependence. The data can be dependent in much more complex ways.
=> In addition to correlation, analyze data with alternative association measures such as HSIC.
4-misleading-effects-due-to-interaction
Interactions between features can "mask" feature effects.
=> Analyze interactions with e.g. 2D-PDP and the interactions measures.
5-ignoring-estimation-uncertainty
There are many sources of uncertainty: model bias, model variance, estimation variance of the interpretation method.
=> In addition to point estimates of (e.g., feature importance) quantify the variance. Be aware of what is treated as 'fixed.'
6-ignoring-multiple-comparisons
If you have many features and don't adjust for multiple comparisons, many features will be falsely discovered as relevant for your model.
=> Use p-value correction methods.
7-unjustified-causal-interpretation
Per default, the relationship modeled by your ML model may not be interpreted as causal effects.
=> Check whether assumption can be made for a causal interpretation.