Azure Data Factory v2: Hands-on overview

The second major version of Azure Data Factory, Microsoft's cloud service for ETL (Extract, Transform and Load), data prep and data movement, was released to general availability (GA) about two months ago. Cloud GAs come so fast and furious these days that it's easy to be jaded. But data integration is too important to overlook, and I wanted to examine the product more closely.
Azure Data Factory v2 allows visual construction of data pipelines
Roughly thirteen years after its initial release, SQL Server Integration Services (SSIS) is still Microsoft's on-premises state of the art in ETL. It's old, and it's got tranches of incremental improvements in it that sometimes feel like layers of paint in a rental apartment. But it gets the job done, and reliably so.
In the cloud, meanwhile, Microsoft's first release of Azure Data Factory (ADF) was, to put it charitably, a minimal viable product (MVP) release. Geared mostly to Azure data services and heavily reliant on a JSON-based, handed-coded approach that only a Microsoft Program Manager could love, ADF was hardly a worthy successor to the SSIS legacy.
Clean slate
But ADF v2 is a whole new product:
- It's visual (the JSON-encoded assets are still there, but that's largely hidden from the user)
- It has broad connectivity across data sources and destinations, of both Microsoft and non-Microsoft pedigrees
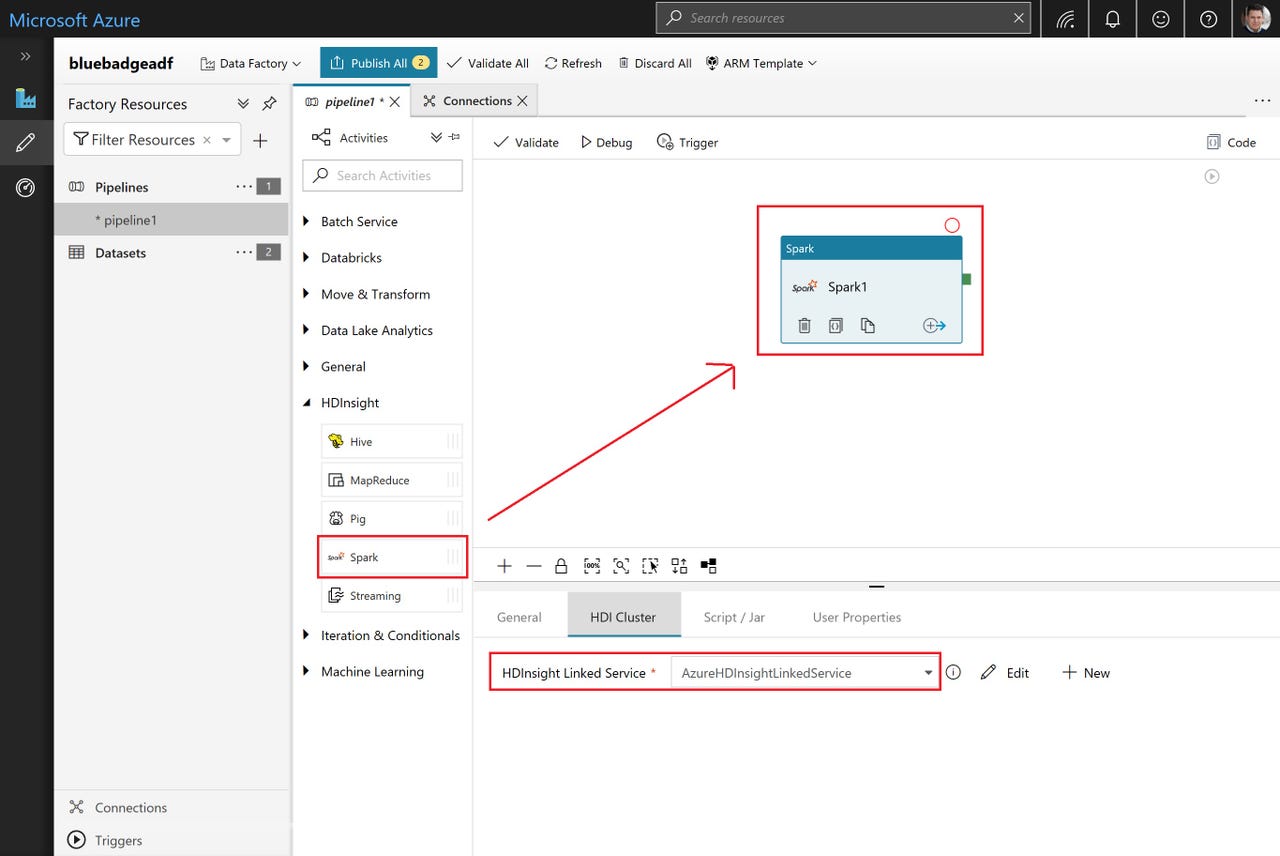
- It's modern, able to use Hadoop (including MapReduce, Pig and Hive) and Spark to process the data or use its own simple activity construct to copy data
- It doesn't cut ties with the past; in fact, it serves as a cloud-based environment for running packages designed in with the on-premises SSIS
The four points above tell the high-level story fairly well, but let's drill down a bit to make those points a bit more concrete.
Connectivity galore
First off, data sources. Microsoft of course supports its own products and services. Whether it's Microsoft's on-premises flagship SQL Server, PC thorn-in-the-side Access, or in-cloud options like Azure SQL Database, SQL Data Warehouse, Cosmos DB, Blob, file and table storage or Data Lake Store (v1 or v2), ADF can connect to it. And while a connector for Excel files is conspicuously absent, saving a CSV file from Excel allows its data to be processed in ADF using the File System connector.
But there's lots more, including Oracle, DB2, Sybase and Postgres in the RDBMS world; Teradata, Greenplum, Vertica and Netezza data warehouse platforms; MongoDB, Cassandra and Couchbase from the NoSQL scene; HDFS, Hive, Impala, HBase, Drill, Presto and Spark from the open source realm; SAP BW and SAP HANA in the BI/analytics world; Dynamics, Salesforce, Marketo, Service Now and Zoho from the SaaS world and even Amazon Redshift, Amazon S3, Amazon Marketplace Web Service and Google BigQuery on the competitive cloud side.
ADF v2 connects to an array of data stores, both from the Microsoft and competitive worlds
For processing the data, ADF v2 can use Azure Batch, Data Lake Analytics (U-SQL), HDInsight, Databricks or Machine Learning Services. And while all of these are Azure services, they deliver a variety of open source technologies within them.
Structured activities
The core unit of work in ADF is a pipeline, made up of a visual flow of individual activities. Activities are little building blocks, providing flow and data processing functionality. What's unusual and impressive here is the degree of logical and control of flow capabilities, as well as the blend of conventional technologies (like SSIS packages and stored procedures) and big data technologies (like Apache Hive Jobs, Python Scripts and Databricks notebooks).
A broad range of activities are on offer. Some of the more interesting ones are highlighted here
The pipelines are constructed visually, and even dragging a single activity onto the canvas allows a great deal of work to be done. In the figure at the beginning of this post, you can see that a single activity allows an entire Python script to be executed on Apache Spark, optionally creating the necessary HDInsight cluster on which the script will be run.
DataOps on board
ADF v2 also allows for precise monitoring of both pipelines and the individual activities that make them up, and offers accompanying alerts and metrics (which are managed and rendered elsewhere, in the Azure portal).
And as as good as the visual interface in v2 versus that of v1 is, ADF offers a range of developer interfaces to the service as well. These include Azure Resource Manager templates, a REST API interface, a Python option, and support for both PowerShell scripts and .NET code.
Behind the scenes
There are also elements to ADF v2 "under the covers" that are worth mentioning. For example, ADF v2 doesn't just support disparate data sources, but moves data between them at great scale when it uses its Azure Integration Runtime. (Microsoft says that ADF can move 1 TB of data from Amazon S3 to Azure SQL Data Warehouse in under 15 minutes.) Scale-out management of this facility is handled for the user by ADF itself. It's managed on a per-job basis and completely serverless, from the user's point of view.
ADF v2 also leverages the innate capabilities of the data stores to which it connects, pushing down to them as much of the heavy work as possible. In fact, the Azure Integration Runtime is less of a data transformation engine itself and more of a job orchestrator and data movement service. As you work with the individual activities, you find that much of the transformation work takes place in the data stores' native environments, using the programming languages and constructs they support.
Quo vadis
Compared to other data pipeline products, ADF v2 is both more evolved and less rich. Its innate capabilities are more limited, but its ability to connect, orchestrate, delegate and manage, using a combination of legacy and modern environments, is robust. It will provide Microsoft and Azure customers with an excellent data transformation and movement foundation for some time to come, and its accommodation of SSIS package lift-and-shift to the cloud makes it Enterprise-ready and -relevant right now.