Cloudera aims to bring real-time queries to Hadoop, big data

Cloudera is opening its Impala open source real-time query project to public beta and adding its second subscription offering---Cloudera Enterprise RTQ---in a bid to speed up Hadoop data crunching.
In an interview, Cloudera CEO Mike Olson outlined the company's plans. Hadoop started as a batch system in many respects, but it hasn't been strong enough for real-time data queries. As a result, companies had been moving information into relational databases just to have more instantaneous discovery.
Cloudera's Impala project is designed to offer the company's similar frame work, but execute quires much faster. Impala is open sourced under an Apache license and has been in private beta since May, said Olson.
"Hadoop just hasn't been fast enough," said Olson, who added that its first uses revolved around batch analysis. "Hadoop has taken a beating for being complex to program and batch mode in operation. Batch is an accident of those first workloads."
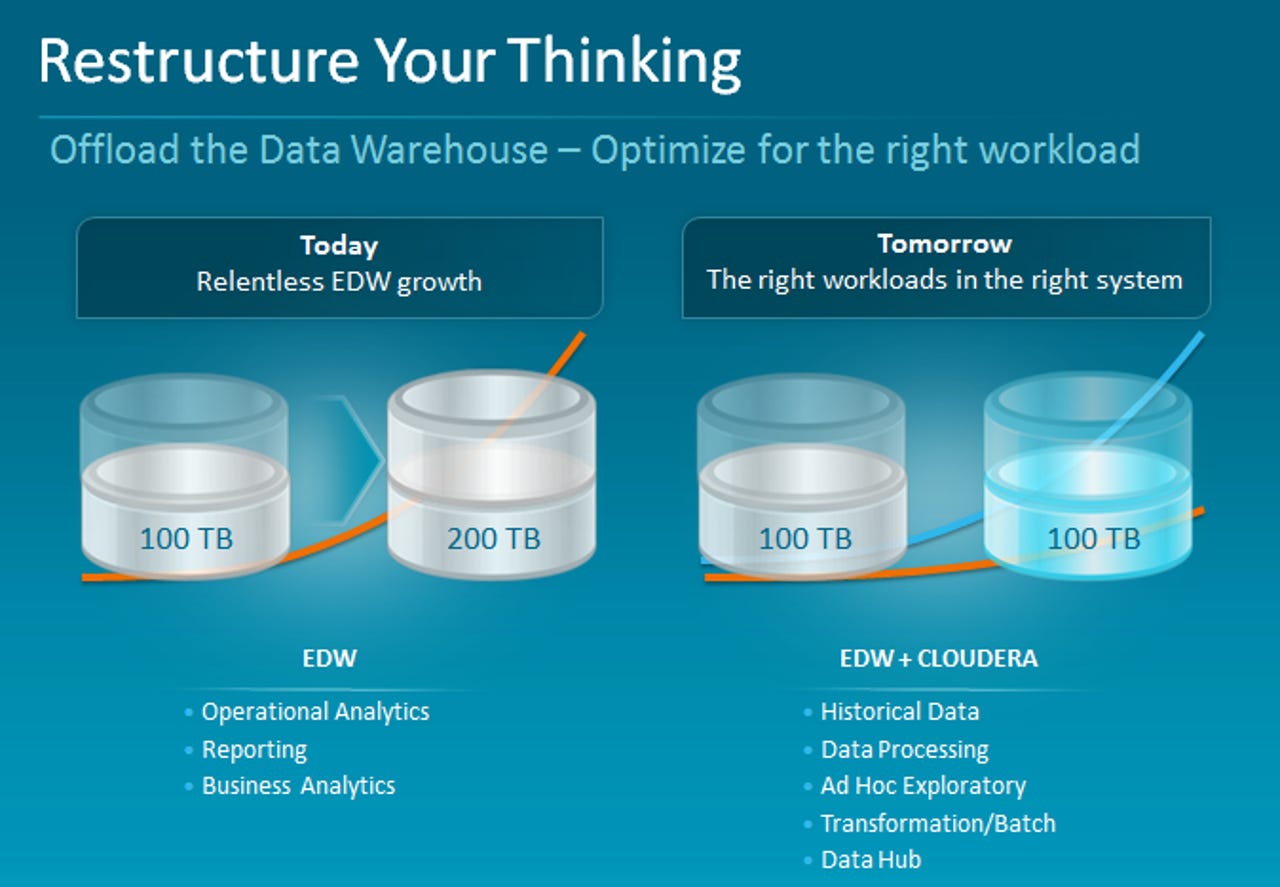
Cloudera's message is that enterprises can keep their existing data warehouses for what they are good for: Operational analysis, business analytics and reporting. Big data workloads can be handled much more cheaply by storing information in a speedier Hadoop framework. Impala operates like Hive, another piece of big data plumbing that connects to Hadoop, but runs faster.
"The aim is to get data at the speed of thought with an analyst in front of the user interface," said Olson. Cloudera is hoping that Hadoop becomes the data repository that sits in the middle of the data warehouse. He also added that some customers are going to Hadoop with their data and cutting tape backups.
If successful, Impala will allow Cloudera to move up the analytics stack. Today, Cloudera has a bevy of enterprise partnerships with the likes of IBM, Wipro, Accenture, Cisco, Dell, HP and Oracle, but most customers are in pilot stages. "I'm highly confident in the opportunities for 2013," said Olson. "Impala increases that opportunity."