Kafka 0.9 and MapR Streams put streaming data in the spotlight

As the Internet of Things (IoT) heats up as a topic, and as big data continues along on its path to maturity, streaming data technology, which fits perfectly in the intersection of the two, is having its shining moment.
How appropriate, then, that today comes big news from a streaming data pure play and a major Hadoop distributor. Specifically, Confluent, the commercial entity behind (and founded by the creators of) Apache Kafka, and Hadoop distribution vendor MapR, are each announcing new releases. Confluent is announcing the 2.0 release of its Confluent Platform, based on the 0.9 release of Apache Kafka, released two weeks ago. MapR, meanwhile is announcing the addition of its own streaming technology, dubbed MapR Streams, right into the core of its distribution.
Again, the keys here are IoT and maturity. In the case of Kafka, the new 0.9 release adds important new features in the realm of multi-tenancy and security. In MapR's case, the addition of its own streaming technology is rooted in the recognition of the multiple workloads that Hadoop clusters serve, and the desire by customers to handle streaming data in-place, on the very same cluster where those multiple workloads are handled.
Kafka's Confluence...
Kafka 0.9 offers the ability to assign quotas to specific queues, such that reads and writes on that queue will be throttled down if the volume reaches its quota. It also offers new authentication, authorization and encryption features. A new component, called Kafka Connect, provides a platform for building data connectors much more easily than was possible previously. In fact, Kafka Connect handles multi-process concurrency and failover operations transparently, so that connector developers don't have to handle that plumbing work themselves.
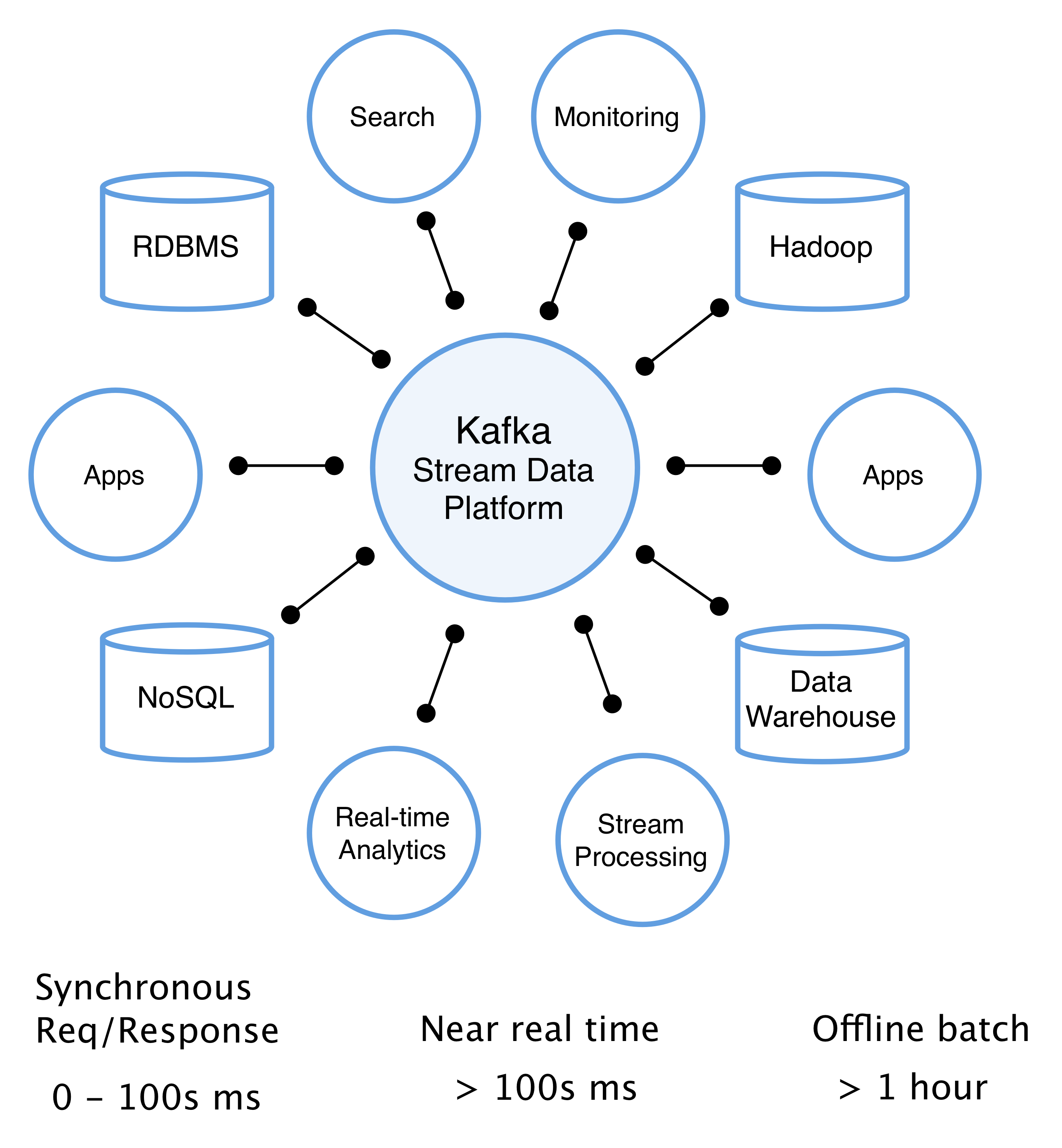
The Kafka Stream Data Platform
Applications don't have to use connectors though; they can in fact connect to Kafka directly. In order to make this kind of development work easier, a new client for Java is available as are both a client and a producer for the C programming language. The Java bridge existed before but was more rudimentary than the one shipping today. The C language client and producer are brand new and, one would imagine, offer connectivity across a great number of platforms, including even embedded systems, where C code lives on.
...And MapR's convergence
Like Kafka, MapR Streams provides publish/subscribe ("pub/sub") message handling middleware; in fact, MapR Streams supports the Kafka API. As such, it is compatible with various open source software that can be used with Kafka, including Apache Storm, Spark Streaming, Flink and Apex. MapR Streams can also work in a multi-cluster federated model, with synchronization built-in. It's sort of a geo-distributed eventual consistency model. And, like Kafka 0.9/Confluent Platform 2.0, it offers multi-tenancy features. In MapR's case, these include tenant-owned streams, topic isolation and, as with Kafka 0.9, quotas.
The MapR Converged Data Platform
MapR's take on things is that by offering Kafka-like functionality and API compatibility right in the distro, it enables a "converged" architecture, essentially bringing batch and streaming data together. Add in MapR's other areas of focus to date, including MapR-FS' use of a read/write Network File System in place of vanilla HDFS; an HBase- and JSON-compatible operational database in the form of MapR-DB; and SQL-based data discovery across data sources with Apache Drill, and the company feels strongly that it has built the ultimate enterprise Hadoop stack out there.
Lambda functions
MapR's notion of a converged architecture alludes, at least in part, to the so-called Lambda architecture, which aims to unite batch and stream processing into a single platform. Cloudera is pursuing the same goal, but is doing so by working hard to make Spark work well with projects across the Hadoop ecosystem. Hortonworks aims to bring about the batch-streaming union through the teaming of its Hortonworks Data Platform (HDP) and its newer cousin, Hortonworks DataFlow (HDF), based on Apache NiFi.
The market wants Lambda, or at least the vendors think it does. Ultimately, though, what customers really want is a way to do self-service analysis on all their data, in near real-time, without needing to think through the distinctions between batch and streaming, or muck with queues, topics and messages.
We're not there yet, even with these important releases. But they definitely provide momentum in the right direction. And with so many vendors scrambling to get this data unification thing right, we may be there before very long.