Streaming data, simplified: Kafka Streams reaches GA

Wouldn't it be great if working with streaming data were just as simple as working with data at rest? And imagine if the two could be modeled, processed and coded against similarly; that would let organizations working with analytics broaden the scope of their work to do real-time streaming analytics too.
We're not quite there yet, but Kafka Streams, a lightweight Java library that works with the Apache Kafka stream data platform, gets us closer, by empowering mainstream Java developers. And today, with the release of Confluent Data Platform 3.0, Kafka Streams has reached general availability (it had been released in preview form in Confluent Data Platform 2.0).
How it works; where it's useful
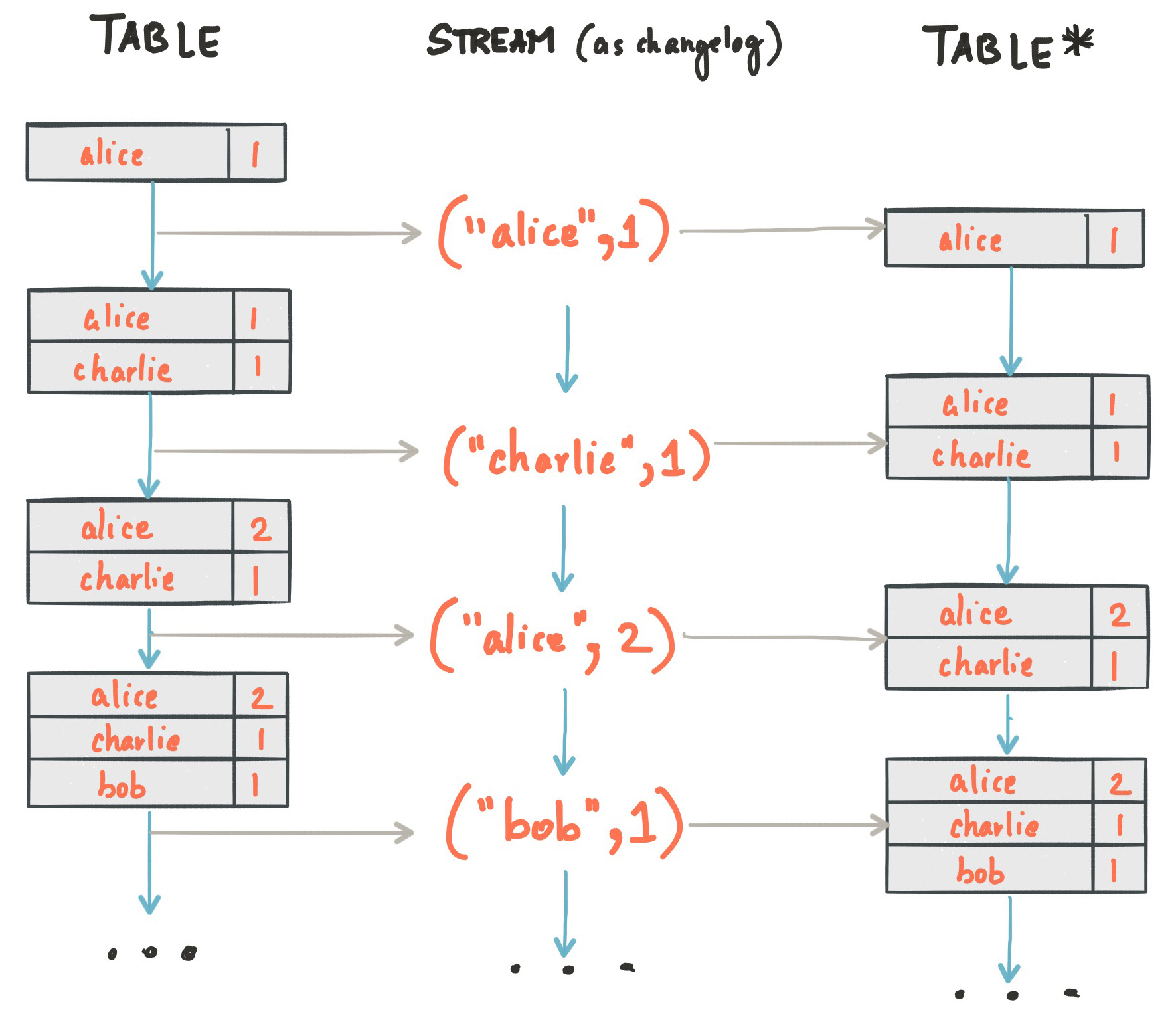
At the risk of oversimplifying things, Kafka Streams makes streaming data look like a conventional table, of keys and value pairs (the data structure is called a KTable). The genius is that, as new data streams in, new rows are added to the table that supersede older rows containing the same key. This way everything looks tabular, but new rows are appended, and old rows don't need to be updated or dropped.
Kafka Streams is geared to letting developers writing operational/transactional applications process streaming data. Even if they're not analytics-focused, developers can embed Kafka Streams, then handle alerting and IoT (Internet of Things) tasks in their applications. If these developers happen to have analytics skill sets and work with Apache Flink, and/or Spark Streaming, so much the better; Confluent says Kafka Streams complements both.
Control, don't freak
Confluent is the company started by Kafka's creators. Confluent Platform is their open source Kafka distribution. Confluent Enterprise is the commercial, enterprise counterpart to that distribution, and it now includes Confluent's first commercially licensed component: Confluent Control Center.
Confluent Control Center aims to add Enterprise manageability to Kafka. It allows administrators to monitor "how many 9s," (i.e. how much uptime and reliability) their Kafka clusters are delivering and how much latency is being encountered. Generally speaking, as Confluent CTO Neha Narkhede explained to me, Confluent Control Center lets customers track the "health of the data vs. health of the machine."
Quo vadis?
Could streaming data get easier still? Sure. Give us a tabular metaphor that goes beyond key/value pairs, and which filters out superseded rows. Then give us a SQL interface and ODBC and JDBC drivers, as well as mechanism for the client to see a frequently refreshed view of the result set. That would let even more developers in on the game, and a number of BI tools -- and their users -- as well.
No, that's not what we have yet. But, yes, we are nearing the final approach.