MapR gets container religion with Platform for Docker

If virtual machines are what made the cloud possible, then containers are what will make the cloud elegant. Think about it this way: as a computing entity, an entire virtual machine is a pretty coarse, hefty resource if what you're really looking to do is distribute a single application.
Containers, on the other hand, let you deploy an application, its dependencies and its environment in an efficient vessel that fits pretty tightly around them and can be pushed into both cloud and on-premises environments very efficiently.
Hadoop without the hoopla
This notion of easily deployed applications is pretty meaningful to Hadoop ecosystem vendor MapR. That's because its "Converged Data Platform," beyond go-to-market rhetoric, focuses on the use of clusters running MapR-FS (an HDFS-compatible File System), MapR-DB (an HBase-compatible NoSQL database) and MapR Streams (a Kafka-compatible streaming data engine) as distributed application platforms.
In other words, instead of setting up a cluster running a full Hadoop/Spark distribution, with all of its companion projects and tools, MapR targets a scenario where just the file system, database and streaming data infrastructure are in place, serving as the core runtime for mission-critical applications (MapR calls them "converged apps") that run right on top.
Open the container
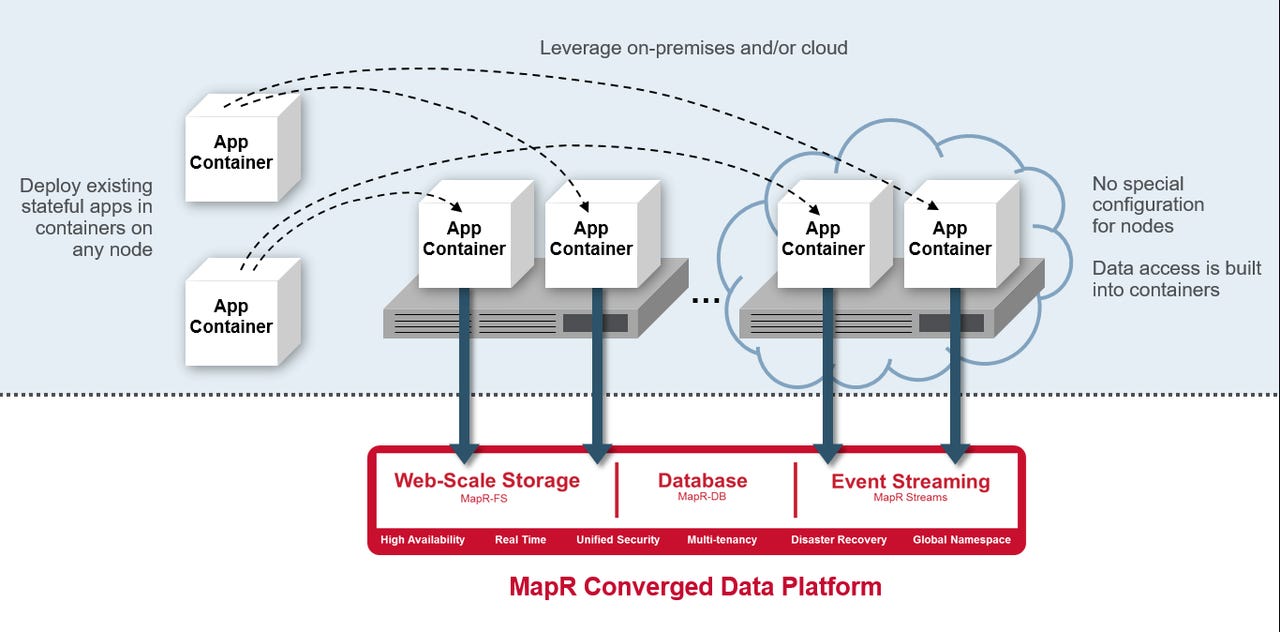
Apps running on these clusters sure sound like they'd be perfect for containerized operation, don't they? Yes, but there's a catch. To make the persistent resources of a Hadoop cluster be visible to apps running in containers, you need some hooks, from the latter to the former. And so MapR has attacked that very problem.
With the Converged Data Platform for Docker, which MapR is announcing this morning, running containerized apps on MapR clusters can apparently work quite well. The combination of a POSIX client for containers and the new MapR Persistent Application Client Container (PACC) allow converged apps in Docker containers to see running MapR clusters, just as if the apps were deployed directly to a virtual machine or physical server.
The MapR-Docker Persistent Application Client Container
Containerized converged apps can run on-premises or in the cloud. And the MapR clusters they target can run in either environment as well. You can even mix and match, for hybrid environments (for example, having the container running on-premises against a cloud-based MapR cluster, or vice-versa.
Not your father's Hadoop distro
With this release, MapR is making clear that its model is very different from Cloudera and Hortonworks. Rather than selling a mere customized Hadoop distribution, the company instead sees itself as selling an enterprise application platform for data-centric computing. Yes, that platform happens to be based on Hadoop and YARN and, yes, it mixes in proprietary technology.
But whereas at one time, it seemed like that cocktail of open source and home-grown Hadoop technology was the story, now that approach really seems like a means to an end. The real goal for MapR is to be an Enterprise data company. Big Data, small data, streaming data, the cloud -- and now containers -- are pieces of that puzzle. But MapR isn't selling the pieces, it's integrating them, and aims to help its customers do likewise.