Microsoft BUILDs its cloud Big Data story

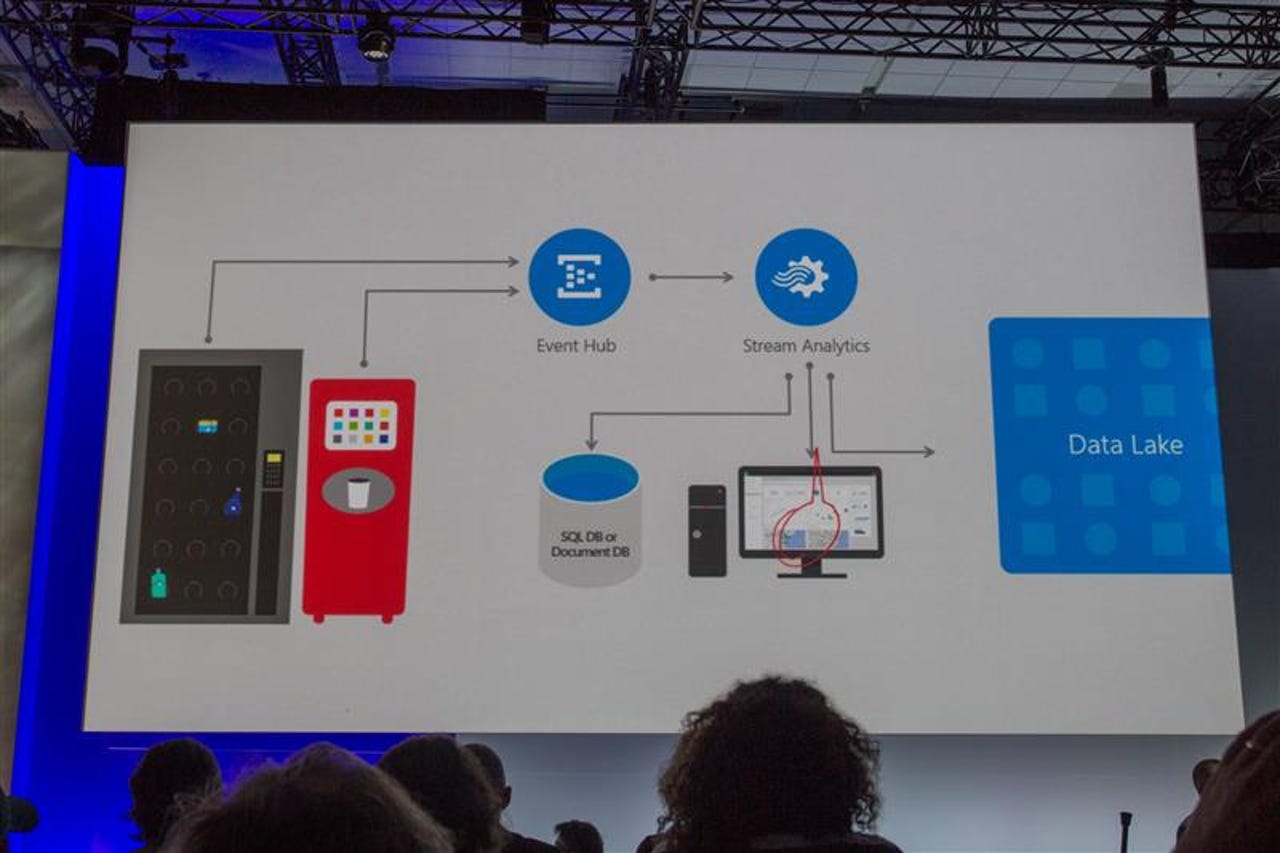
Along with that reveal came news of two complementary services: Azure Data Lake and Elastic Databases for Azure SQL Database (the cloud flavor of SQL Server, Microsoft's flagship relational database). While it may seem that these two announcements have merely come along for the ride, there is in fact synergy and harmony between all three offerings.
Scaling out, with nuance
First things first, though. Azure Data Warehouse is not just a counter to Redshift; it's a challenge to its economic model. With Redshift, the unit of scaling is the number of nodes in a cluster. In other words, you can scale your data warehouse, but you must do so such that compute and storage increase in lockstep. Azure Data Warehouse (ADW) decouples compute and storage, allowing them to be scaled individually.
That is a very different model economically and will likely save customers money. Because beyond merely eliminating the provisioning of excess compute when you need more storage (or vice versa), the ADW model allows compute to be paused when not in use and resumed on-demand when it is. That, in turn, allows utility billing for compute, which contrasts starkly with the Redshift model, where you're billed on a 24/7 basis for all the virtual machines (VMs) that make up the nodes in your cluster.
ADW achieves this storage independence by using Azure Storage Blobs (i.e. its cloud storage service, akin to Amazon S3) instead of the local drives on the VMs. That could make for a big difference in performance, and not in Azure Data Warehouse's favor. But when I was briefed on the service earlier this week by Data Platform Corporate Vice President T.K. Ranga Rengarajan and Database Systems Group General Manager Shawn Bice, they assured me that the performance was excellent. My benchmark-prone friends will have to help me with due diligence there.
What about Hadoop?
ADW is a petabyte-scale service -- but if we're talking about that league of data volume, shouldn't Hadoop be part of the conversation? Never fear; it is. First off, because ADW is built with the same technology Microsoft uses in its Analytics Platform System (APS -- formerly SQL Server Parallel Data Warehouse), it includes a technology called PolyBase which I've written about before.
PolyBase allows APS and ADW to query data in a Hadoop cluster, either directly or by delegating some of the work to Hadoop itself. The Hadoop data is made to look as if it were local to the data warehouse, so that developers and database administrators can use existing skill sets to query it. PolyBase can integrate Hadoop in this manner regardless of whether it does so with a Microsoft HDInsight cluster in the cloud, or Hortonworks or Cloudera clusters running on Azure VMs or on premises.
And now, the plot thickens
Along with ADW, Microsoft announced a new flavor of Azure Storage, called Azure Data Lake. The latter can handle streaming data (low latency, high volume, short updates), is geo-distributed, data-locality aware and allows individual files to be sized at petabyte scale.
Azure Data Lake can be addressed with Azure Storage APIs, of course, but it's also compatible with the Hadoop Distributed File System (HDFS). That means the same range of Hadoop clusters can use it as ADW/PolyBase can use in reverse.
Meanwhile, back at the OLTP ranch
Date warehouses and Hadoop clusters are great, but let's not forget about the production applications and databases that generate the transactional data those analytic tools will need for reference. In Microsoft's cloud, that takes us to Azure SQL Database (whose version 12 technology, by the way, also underlies ADW).
What's new in SQL DB land? A new option for provisioning capacity, that's what. Just as coupling storage and compute introduces inefficiencies in the data warehouse arena, coupling scale with specific databases or shards (partitions) can introduce inefficiencies for OLTP. The reason: the units of database capacity may grow or shrink relative to each other in a fairly volatile manner, and so provisioning capacity in the aggregate can be much more appealing.
Azure SQL DB Elastic Databases allow for this aggregate-oriented provisioning of capacity, offering yet another economic model challenge to Amazon's Relational Database Service (RDS) which, to my knowledge, does not (yet) have a comparable option.
Customers win
Competition is good. Arguably, Microsoft would not have gotten of its duff and offered ADW had Amazon not disrupted Redmond in the first place, with Redshift. And the new billing paradigms were likely catalyzed, at least in part, by the spot instance model that AWS offers. Now Microsoft is responding, not just in terms of achieving parity, but by going a few important steps further.
How will Amazon respond? It's already come up with a Machine Learning offering to counter Azure's. I suspect it will react on the data warehouse, storage and OLTP axes as well. And let's not forget that Google is in this game too, with Hadoop, BigQuery and its own cloud storage.
Customers benefit from this innovation dividend, as long as they keep track of what's on offer. The cloud vendors will need to help there by explaining their new offerings, carefully and clearly.