Microsoft, MapR announce new Apache Spark-based releases

With Spark Summit getting under way this week in San Francisco, a number of players in the Big Data game will be making announcements around Apache Spark, the open source in-memory-oriented Big Data platform.
MapR and Microsoft are first up, each announcing its own new Spark distribution. Significantly, both distros are in fact Hadoop-based, rather than being based on standalone Spark clusters. But both lead with Spark as their headlines and have built the distributions to be Spark-centric.
Spark-lit Redmond
In Microsoft's case, the distro had been available in preview format already, and goes to general availability today. While the initial preview, announced almost a year ago, was based around HDInsight (Microsoft's cloud-based Hadoop distro) for Windows, the company pivoted and redesigned the distro to be Linux-based. Packaged with the Jupyter notebook environment, along with underlying kernels that can process code written in Python and Scala, Microsoft makes it very easy for anyone with an Azure account to provision a cluster, click a link, go through a bunch of tutorial notebooks, and start working with Spark right away.
Microsoft is also announcing Spark integration with Power BI (including integration of Spark Streaming) and its R Server for HDInsight and R Server for Hadoop on premises products.
Also read: Microsoft expands its commitment to Apache Spark big-data framework
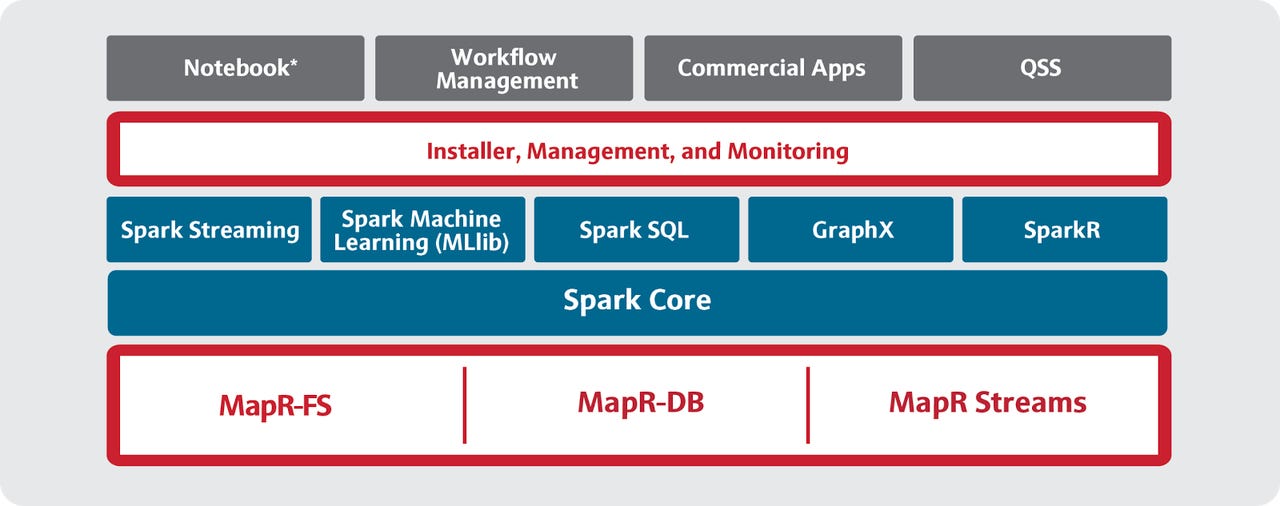
MapR goes Spark-first
MapR, while using open source Apache Spark bits, has carefully integrated Spark to work with its own Hadoop distribution and its unique closed source components, including the HDFS-compatible Map-FS, the HBase-compatible MapR-DB, and the Apache Kafka API-compatible MapR Streams.
Go directly to Spark (do not pass MapReduce)
MapR's Jack Norris told me that many customers availing themselves of the company's training materials are starting with Spark, rather than learning the basics of Hadoop first. One Microsoft employee explained to me that Hadoop-native MapReduce is basically dead (my words, not his) and so Spark is in many ways the new default.
This Spark-first paradigm is relatively prevalent in the Big Data space at this point. I'm not certain it's correct, especially since Apache Tez provides a very capable post-MapReduce platform that continues to support existing Hadoop ecosystem components, like Hive and Tez. There comes a point, though, when enough customers are demanding a Spark-centric distribution, that that's what vendors need to provide.
Assimilation, not substitution
In any case, it's noteworthy that in offering these new distributions, both MapR and Microsoft are also endorsing an increasingly common configuration: Spark running on top of Hadoop (i.e. YARN, HDFS), often along with Kafka. And both make the rest of the Hadoop stack (Hive, Pig, HBase) available for those who want it.
That setup is becoming a de facto standard. And while some other engine will likely come along and steal Spark's thunder at some point in the future, the pattern of the Big Data stack evolving in a cumulative fashion (where new components complement old ones), rather than a fully displacing fashion (where the whole stack is ripped-and-replaced), is looking like the way forward.
Note: this post was updated to specify that Jupyter notebooks on Microsoft HDInsight can be programmed in Python and Scala. The post originally stated they could be programmed in Scala and R.