Neo4j 4.0 adds enterprise Fabric to its graph database

We've been keeping track of graph database evolution regularly in this column. When we got note from Neo4j about its upcoming release, dubbed "the most significant product release in the graph technology market to date", our interest was piqued. Although the outline we first received was laconic, discussing with CEO Emil Eifrem and digging a bit deeper did not disappoint.
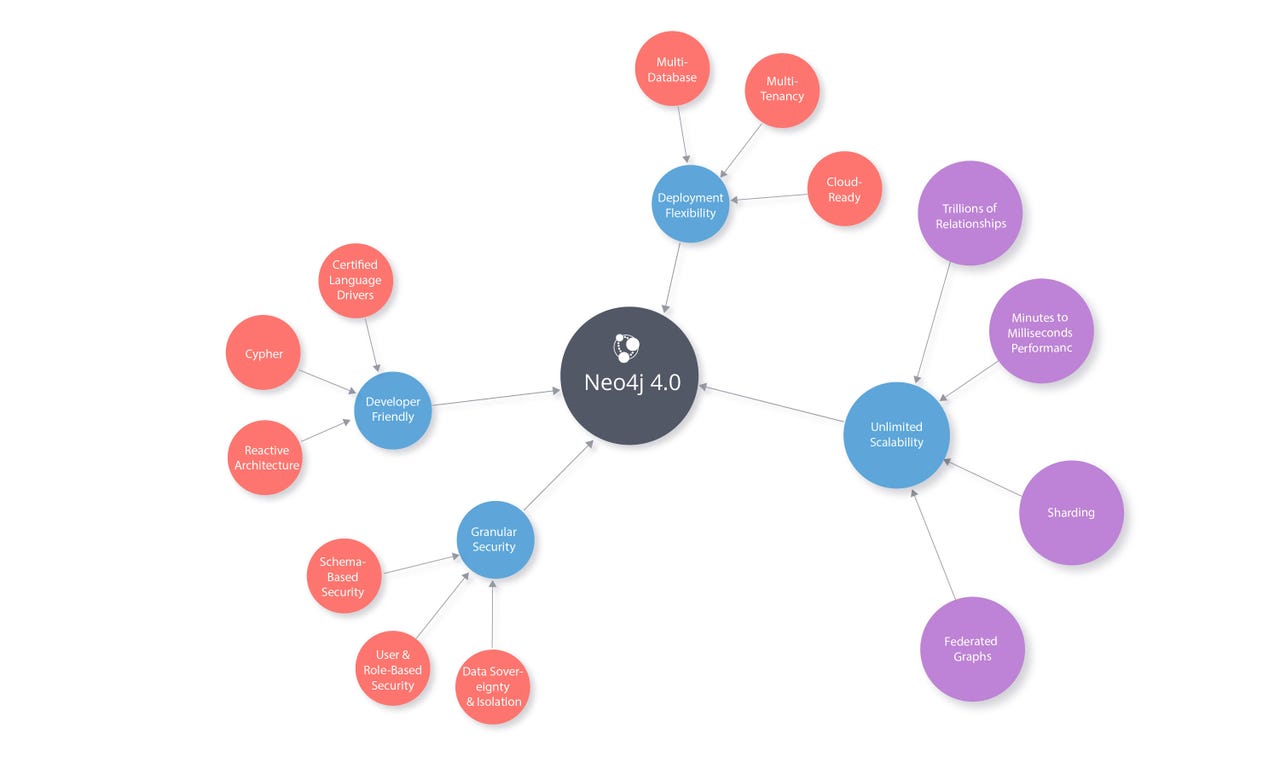
Conventional wisdom says a product version labeled 4.0 is a major release. Going over Neo4j 4.0 makes it clear why Neo4j's people feel this way about this release. Addressing scalability, security, management and architectural pain points all in one release is no small feat. These are all features users have been asking for. Let's unpack them one by one.
Horizontal scalability: a Fabric for Sharding and Federation
Let's not beat around the bush: horizontal scalability is hard, and it's been a pain point for Neo4j for a while. One that its users were aware of, and making a point of. As long as the entire graph could fit in one machine, it was all good. As soon as the graph started growing beyond that, things started getting ugly. The answer, Neo4j 4.0 promises, lies in the Fabric.
Fabric is the codename for Neo4j's new sharding and federation capabilities. Sharding refers to splitting one graph over many servers. Federation refers to being able to "join" many different graphs across many servers. Eifrem said they have been thinking about how to do this right for a long time, and we are certain it's true.
This is anything but simple, as anyone who has had a go at designing and operating distributed systems can attest. Choosing a sharding strategy that works means splitting the entirety of your data in a way that mirrors the capabilities of the servers used as close as possible, while avoiding hopping from one server to the other as much as possible.
Federation also refers to distribution, but is somewhat different. In sharding, servers are essentially cooperating to distribute the load of serving data shared among them. In federation, each server is acting independently. The data different servers host may or may not overlap or complement each other. Federating capabilities enable servers to serve parts of the data they host upon request.
Neo4j 4.o comes with an array of new features, implemented in a "very graphy way"
Both scenarios, however, have some things in common. First, adding those capabilities to servers is not enough. There needs to be some way for users to access this. In other words, the query language has to change to accommodate sharing and federation. Eifrem confirmed this: indeed, Cypher, Neo4j's query language, has been extended.
This, however, is necessary, but not sufficient to use sharding and federation. With great power comes great responsibility. To use those features, users should not just learn a new syntax, but also configure the servers in a way that makes sense for their needs. Using a sharded or federated Neo4j database means being aware of, and consistent with, its configuration.
Eifrem said there will be lots of explainer material coming up, on all new features. At this time, a blog post by Neo4j engineer Adam Cowley is what we have to go by with. One thing to take note of is that Fabric capabilities are only part of Neo4j Enterprise, not the open source version.
Eifrem mentioned Fabric enables operating on a scale above what was previously possible. He cited albelli, one of the largest European photo book suppliers with over a million users as an early adopter. Eifrem also noted Neo4j has been experimenting with sharding benchmark datasets to develop this feature.
Fine grained security built on multiple database capability, and a reactive architecture
Security is not exactly a head-turning feature, but it is a requirement for any enterprise platfom. Eifrem noted that as Neo4j adoption is spreading, in order for the platform to be used across organizational boundaries, fine-grained security is a must.
For example, in a scenario involving healthcare data, relevant regulation such as HIPAA would apply. This imposes certain requirements to data access, which translate on the technical level to things such as being able to turn on and off access to certain edges or properties for certain groups of users.
This, Eifrem said, is now possible, and it has been done in a "very graphy" way. What this means is that the security model for a Neo4j database is itself modeled as graph and stored in Neo4j. This makes sense, and it's something other databases do as well.
In relational databases, for example, in addition to user-defined schemas, there is a system meta-schema, which includes information about other schemas. Neo4j's new security capabilities work in a similar way. This, in turn, points towards another significant addition to Neo4j 4.0: the ability to host multiple databases within a single instance.
The ability to host multiple databases in a single instance is a chronic pain point Neo4j is addressing with version 4.0
Until now, this was not possible. If users wanted to create a new database, it meant having to spin up another instance. Needless to say, this was not the most efficient way to do this. With Neo4j 4.0, that's no longer necessary. Users can now create and host many databases within a single instance.
Last but not least, Neo4j has made some internal architecture changes, in order to keep with the times. In what Eifrem described as a nod to the developer community, Neo4j has adopted the Reactive Manifesto, and it has been refactored accordingly. The idea behind systems built as Reactive Systems is to be more flexible, loosely-coupled and scalable.
Reactive systems are meant to be easier to be more tolerant of failure and highly responsive, giving users effective interactive feedback. Responsive, resilient, elastic, and message driven are the key properties of reactive systems. Eifrem said Neo4j has adopted them, but has not changed existing APIs. Instead, new APIs have been added to expose those capabilites.
100 engineers, a little bit of deja vu, and MySQL-like ease of use
What to make of all of this? First off, it looks like it must have taken significant engineering vigor to implement those features. Eifrem's opener to the conversation was "this is what our 100 engineers have been working on". Apparently Neo4j's recent funding is being put to good use. Neo4j is hoping to get a return on its investment by boosting enterprise adoption.
The other thing to note: it looks like in order to address some of its own chronic pain points, Neo4j has borrowed pages from (graph) database history and best practices. And that makes sense. For example, we noted that sharding and federated querying capabilities for Cypher resemble those of SPARQL. SPARQL is the main query language for RDF graph databases.
Despite the fact that Fabric is only part of Neo4j Enterprise, Cypher also has an open source version, called openCypher. Other vendors have implemented Cypher, too. So we wondered whether there is a chance of seeing sharding and federated Cypher queries across heterogeneous nodes. That would, to some extent, duplicate RDF interoperability in property graphs.
Neo4j's team commented that the new sharding capability leverages features that have been actively worked inside of the GQL forum, alongside other graph vendors. They went on to add that the features have been in Cypher for some time as Cypher 10 (i.e. implemented in Neo4j's Cypher for Apache Spark project).
Fabric is the codename for Neo4j's new sharding and federation capabilities that enable it to scale.
From a language perspective, they concluded, this specifically means being able to write a query that spans multiple databases as graphs and returns a single result set. Our interpretation: if you have a set of nodes, some of which run Neo4j 4.0 Enterprise, and some of which run other implementations of Cypher 10, distributed querying should be possible.
To us, that is a little bit of deja vu, opening possibilities for data integration and interoperability. It will be interesting to see how this evolves, and whether it borrows things such as URIs from the RDF world. That would help uniquely identify data across nodes. Wrapping up, we asked Eifrem what those 100 engineers will be working on next. His tongue-in-cheek-answer was RDF.
Eifrem, however, was fast to point out further improvements to ease of use as the next frontier. Neo4j is already considered easy to use among graph databases, but Eifrem mentioned MySQL as a yardstick to measure this against. Ease of use may be largely intangible, but it also takes lots of effort to get right.
We certainly see why this is a priority for Neo4j. Joking aside though, the more Neo4j expands towards federated querying and data integration scenarios, the more it will come across challenges and opportunities the RDF world has been facing for years. The more the 2 worlds get exposed to each other, the better for users.