Nvidia sweeps AI benchmarks, but Intel brings meaningful competition

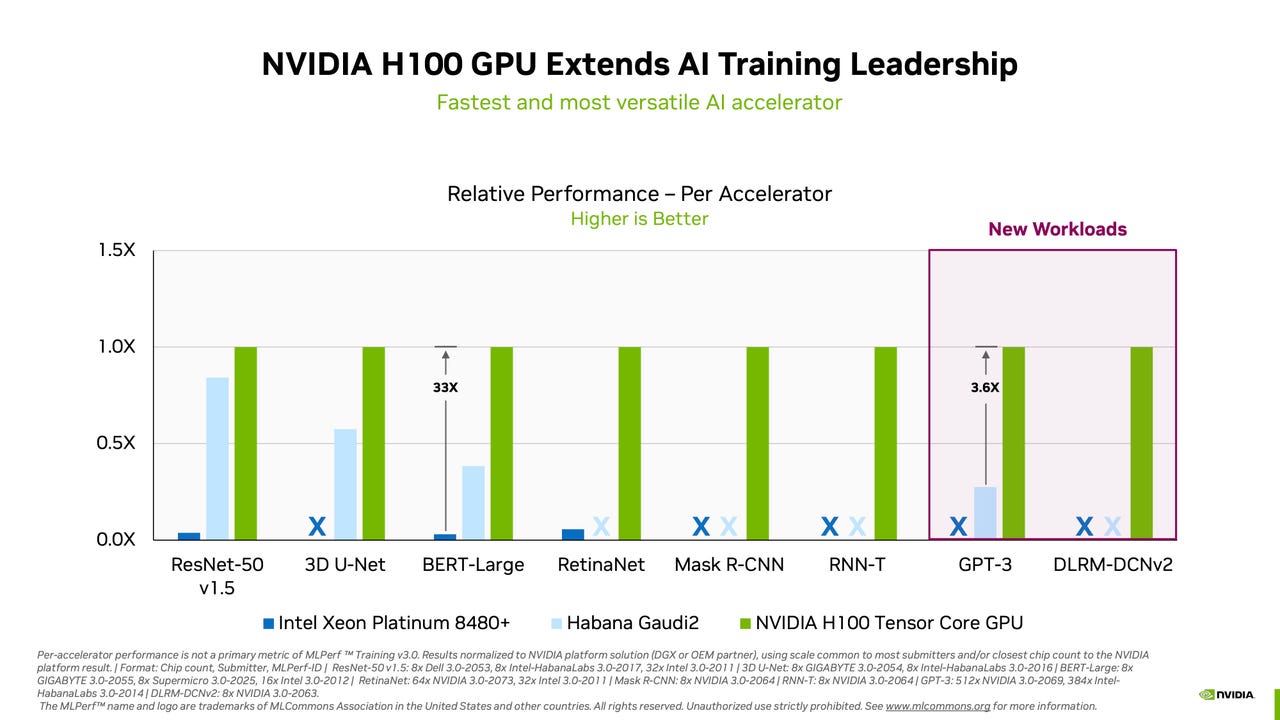
The latest benchmark tests of chip speed in training neural networks was released on Tuesday by the MLCommons, an industry consortium. As in past years, Nvidia scored top marks across the board in the MLPerf tests.
With competitors Google, Graphcore and Advanced Micro Devices not submitting entries this time around, Nvidia's dominance across all eight tests was complete.
Also: AI will change software development in massive ways
However, Intel's Habana business brought meaningful competition with its Guadi2 chip, and the company pledges to beat Nvidia's top-of-the-line H100 GPU by this fall.
The benchmark test, Training version 3.0, reports how many minutes it takes to tune the neural "weights", or parameters, until the computer program achieves a required minimum accuracy on a given task, a process referred to as "training" a neural network.
The main Training 3.0 test, which totals eight separate tasks, records the time to tune a neural network by having its settings refined in multiple experiments. It is one half of neural network performance, the other half being so-called inference, where the finished neural network makes predictions as it receives new data. Inference is covered in separate releases from MLCommons.
Along with training on server computers, MLCommons Tuesday released a companion benchmark test, MLPerf Tiny version 1.1, which measures performance when making predictions on very-low-powered devices.
Also: Nvidia, Dell, and Qualcomm speed up AI results in latest benchmark tests
Nvidia took the top spot in all eight tests, with the lowest time to train. Two new tasks were added. One is testing the GPT-3 large language model (LLM) made by OpenAI. Generative AI using LLMS has become a craze due to the popularity of OpenAI's ChatGPT program, which is built upon the same LLM. In the GPT-3 task, Nvidia took the top spot with a system it assembled with the help of partner CoreWeave, which rents cloud-based instances of Nvidia GPUs.
The Nvidia-CoreWeave system took just under eleven minutes to train using a data set called the Colossal Cleaned Common Crawl. That system made use of 896 Intel Xeon processors and 3,584 Nvidia H100 GPUs. The system carried out the tasks using Nvidia's NeMO framework for generative AI.
The training happens on a portion of the full GPT-3 training, using the "large" version of GPT-3, with 175 billon parameters. MLCommons restricts the test to 0.4% of the full GPT-3 training in order to keep the runtime reasonable for submitters.
Also new this time around was an expanded version of the recommender engines that are popular for things such as product search and social media recommendations. MLCommons replaced the training data set that had been used, which was a one-terabyte data set, with a four-terabyte data set called the Criteo 4TB multi-hot. MLCommons decided to make the upgrade because the smaller data set was becoming obsolete.
"Production recommendation models are increasing in scale -- in size, compute, and memory operations," noted the organization.
The only vendor of AI chips to compete against Nvidia was Intel's Habana, which submitted five entries with its Gaudi2 accelerator chip, plus one entry submitted by computer maker SuperMicro using Habana's chip. Those systems collectively submitted in four of the eight tasks. In every case, the Habana systems came in far below the top Nvidia systems. For example, in the test to train Google's BERT neural network on Wikipedia data to answer questions, Habana came in fifth place, taking two minutes to complete the training versus eight seconds for a 3,072-GPU Nvidia-CoreWeave machine.
However, Intel's Jordan Plawner, head of AI products, noted in an interview with ZDNET that for comparable systems, the difference in time between Habana and Nvidia is close enough it may be negligible to many companies.
For example, on the BERT Wikipedia test, an 8-part Habana system, with two companion Intel Xeon processors, came in at just over 14 minutes to train. That result was better than two dozen other submissions, many with double the number of Nvidia A100 GPUs.
Also: To measure ultra-low power AI, MLPerf gets a TinyML benchmark
"We invite everyone to look at the 8-device machines," said Plawner. "We have a considerable price advantage with Gaudi2, where we are priced similar to a similarly spec'd A100, giving you more training per dollar."
Plawner noted that not only is the Gaudi2 able to beat some similar configurations of Nvidia A100, but the Gaudi2 runs with a slight handicap. Nvidia submitted their MLPerf entries using a data format to train called "FP-8," for floating point, 8-bit, whereas Habana used an alternate approach called BF-16, for B-float, 16-bit. The higher arithmetic precision of the BF-16 hampers the training somewhat in terms of time to complete.
Later this year, said Plawner, Gaudi2 will be using FP-8, which he said will allow for greater performance. It will even allow Habana to beat Nvidia's newer H100 system on performance, he predicted.
"The industry needs an alternative" to Nvidia, said Plawner. Customers, while traditionally reluctant to switch from the trusted brand, are now being pushed by a sudden tightness in the supply of Nvidia's parts. CEO Jensen Huang said last month that Nvidia is having a hard time filling demand for H100 GPUs.
"Now they're motivated," Plawner told ZDNET of customers frustrated by lack of Nvidia supply.
"This is what we are hearing from them, that they have things they want to do tomorrow, that the CEO is mandating, and they cannot do it because they cannot get GPUs, period."
"Trust me, they're making far more than they're spending [on generative AI]. If they can put 50 people on a Gaudi project to literally get the same time to train, if the answer is, I have no GPUs, and I'm waiting, or, I have Guadi2, and I can launch my new service tomorrow, they will go buy Gaudi2s to launch their new service."
Intel is the world's second-largest factory for chips, or, "fab", after Taiwan Semiconductor, noted Plawner, which gives the company an ability to control its own supply.
Also: These mushroom-based chips could power your devices
Although Nvidia builds multi-thousand-GPU systems to take the top score, Habana is capable of the same, said Plawner. "Intel is building a multi-thousand Guadi2 cluster internally," he said, with the implicit suggestion that such a machine could be an entry in a future MLPerf round.
Tuesday's results are the second quarter in a row for the training test in which not a single alternative chip maker showed a top score against Nvidia.
A year ago, Google split the top score with Nvidia thanks to its TPU chip. But Google didn't show up in November of last year, and was again absent this time. And startup Graphcore has also dropped out of the running, focusing on its business rather than showing off test results.
In a phone conversation, MLCommons director David Kanter, asked by ZDNET about the no-show by competitors, remarked, "The more parties that participate, the better."
Google did not reply to an inquiry from ZDNET at press time asking why the company did not participate this time around. Advanced Micro Devices, which competes with Nvidia on GPUs, also did not reply to a request for comment.
Also: These are my 5 favorite AI tools for work
AMD did, however, have its CPU chips represented in systems that competed. However, in a surprising turn of events, every single winning Nvidia system used Intel Xeon CPUs as the host processor. In the year-earlier results, all eight winning entries, whether from Nvidia or Google, were systems using AMD's EPYC server processors. The switch shows that Intel has managed to recoup some lost ground in server processors with this year's release of Sapphire Rapids.
Despite the absence of Google and Graphcore, the test continues to attract new system makers making submissions. This time around, first-time submitters included CoreWeave, but also IEI and Quanta Cloud Technology.