Google, Nvidia split top marks in MLPerf AI training benchmark

MLCommons director David Kanter made the point that improvements in both hardware architectures and deep learning software have led to performance improvements on AI that are ten times what would be expected from traditional chip scaling improvements alone.
Google and Nvidia split the top scores for the twice-yearly benchmark test of artificial intelligence program training, according to data released Wednesday by the MLCommons, the industry consortium that oversees a popular test of machine learning performance, MLPerf.
The version 2.0 round of MLPerf training results showed Google taking the top scores in terms of lowest amount of time to train a neural network on four tasks for commercially available systems: image recognition, object detection, one test for small and one for large images, and the BERT natural language processing model.
Nvidia took the top honors for the other four of the eight tests, for its commercially available systems: image segmentation, speech recognition, recommendation systems, and solving the reinforcement learning task of playing Go on the "mini Go" dataset.
Also: Benchmark test of AI's performance, MLPerf, continues to gain adherents
Both companies had high scores for multiple benchmark tests, however, Google did not report results for commercially available systems for the other four tests, only for those four it won. Nvidia reported results for all eight of the tests.
The benchmark tests report how many minutes it takes to tune the neural "weights," or parameters, until the computer program achieves a required minimum accuracy on a given tasks, a process referred to as "training" a neural network.
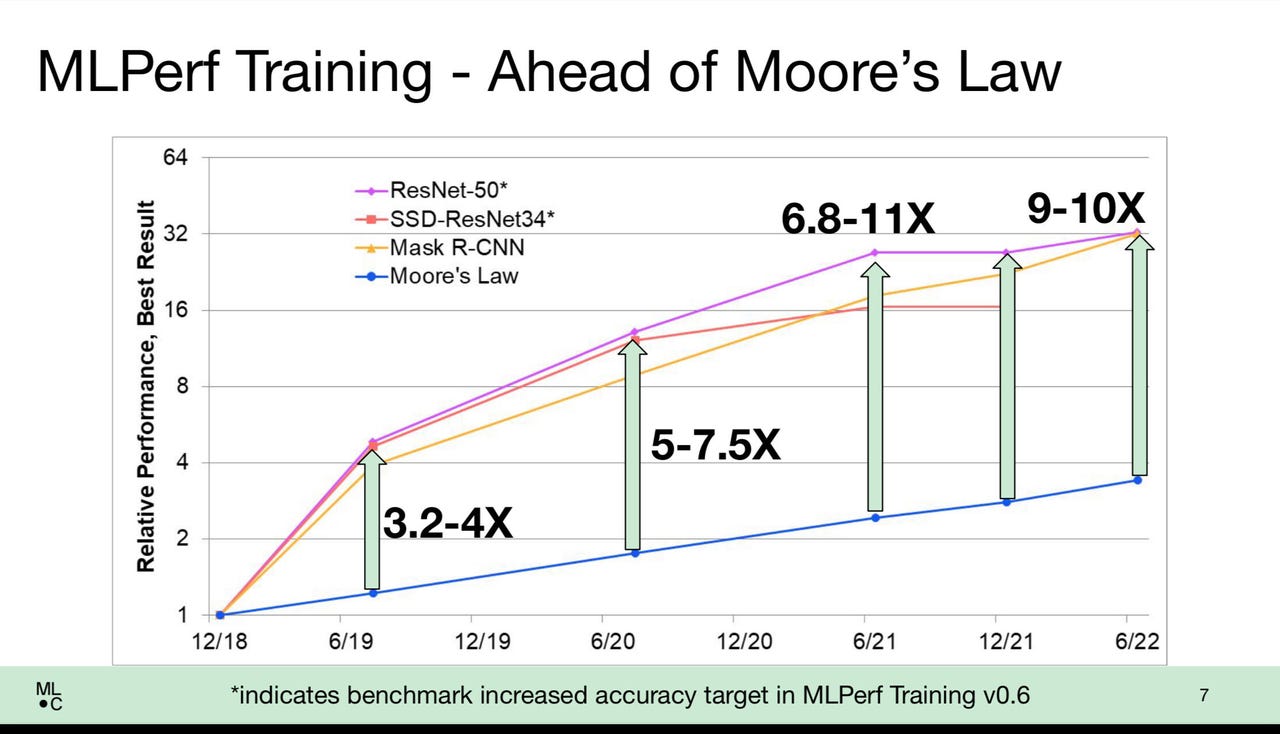
Across all vendors, training times showed significant improvements thanks to both greater horsepower and smarter software approaches. In a media briefing, the MLCommons's executive director, David Kanter explained that in broad strokes, the results show that training has increased in performance better than Moore's Law, the traditional rule of thumb that says a chip's doubling in transistors every 18 to 24 months speeds up computer performance.
Also: Google uses MLPerf competition to showcase performance on gigantic version of BERT language model
Scores on the venerable ImageNet task, for example, where a neural network is trained to assign a classifier label to millions of images, is 9 to 10 times faster today than simple chip improvements would imply, said Kanter.
"We've done a lot better than Moore's Law," said Kanter. "You would expect to get about three and a half times better performance, assuming that transistors linearly relate to performance; as it turns out, we're getting 10x Moore's Law."
The benefits trickle down to "the common man or woman," said Kanter, "the researcher with a single workstation" containing just 8 chips, he said.
Nvidia, which dominates sales of the GPU chips that make up the majority of AI computing in the world, routinely submits results for most or all of the tests. Those single workstations are seeing improvements or 4 to 8 times simple transistor scaling, he noted. "We're putting a lot more capabilities into the hands of researchers, which allows us to run more experiments and, hopefully, make more discoveries."
Also: MLCommons unveils a new way to evaluate the world's fastest supercomputers
Google, whose TPU is one of the main competitors to Nvidia chips, has a much less consistent track record with MLPerf. In December's benchmark report, the company only submitted one test number, for an experimental use of its TPU on the BERT test.
Google said in prepared remarks, "Google's TPU v4 [version 4] ML supercomputers set performance records on five benchmarks, with an average speedup of 1.42x over the next fastest non-Google submission, and 1.5x vs our MLPerf 1.0 submission."
Google's reference to five benchmarks includes a reported best score on recommendation systems for a research system that is not commercially available.
Asked by ZDNet why Google chose to compete with commercial systems in the four categories and not the other four, the company said in an email response, "Our intent with submissions is to focus primarily on workloads that maximize benefits beyond MLPerf for us.
Also: AI industry, obsessed with speed, is loathe to consider the energy cost in latest MLPerf benchmark
"We make a decision on which models to submit based on their resemblance to ML models used within Google and by customers of Google Cloud. Submitting and tuning benchmarks is a significant amount of work so we focus our efforts to maximize benefits beyond MLPerf for us.
"Given this, we focused our efforts on four benchmarks for the Cloud available category - BERT, ResNet, RetinaNet, MaskRCNN."
Nvidia emphasized the comprehensive scope of submissions by itself and by partners including Dell and Lenovo. Computers using Nvidia chips of one kind or another were responsible for 105 systems and 235 reported test results out of the total 264 reported results.
"NVIDIA and its partners continued to provide the best overall AI training performance and the most submissions across all benchmarks with 90% of all entries coming from the ecosystem, according to MLPerf benchmarks released today," Nvidia executive Shar Narasimhan said in prepared remarks.
Also: Graphcore brings new competition to Nvidia in latest MLPerf AI benchmarks
"The NVIDIA AI platform covered all eight benchmarks in the MLPerf Training 2.0 round, highlighting its leading versatility."
In one slide, Narasimhan showed what he said was a "normalized" measurement that tried to achieve a per-accelerator performance, given that the different machine submissions use different numbers of accelerator chips. This measure, said Narasimhan, showed Nvidia being tops in performance on 6 of the 8 tests.
"We believe that this particular methodology of showing the highest performance normalized to 1.0 X and then showing all of the remaining accelerators at similar scale in comparison is the fairest way to compare everybody," said Narasimhan.
Among other developments, the MLPerf test continued to gain adherents and garnered more test results than in past. A total of 21 organizations reported the 264 test results, up from 14 organizations and 181 reported submissions in the December version 1.1 report.
The new entrants included Asustek; the Chinese Academy of Sciences, or CASIA; computer maker H3C; HazyResearch, the name submitted by a single grad student; Krai, which has participated in the other MLPerf competition, inference, but never before in training; and startup MosaicML.
Among top-five commercial systems, Nvidia and Google were trailed by a handful of submitters that managed to achieve third, fourth or fifth place.
Also: To measure ultra-low power AI, MLPerf gets a TinyML benchmark
Microsoft's Azure cloud unit took second place in the image segmentation competition, fourth place in the object detection competition with high-resolution images, and third place in the speech recognition competition, all using systems with AMD EPYC processors and Nvidia GPUs.
Computer maker H3C took fifth place in four of the tests, the image segmentation competition, the object detection competition with high-resolution images, the recommendations engine, and Go game playing, and was able to also make it to fourth place in speech recognition. All of those systems used Intel XEON processors and Nvidia GPUs.
Dell Technologies held the fourth place in object detection with the lower-resolution images, and fifth place in the BERT natural-language test, both with systems using AMD processors and Nvidia GPUs.
Computer maker Inspur took fifth place in speech recognition with a system using AMD EPYC processors and Nvidia GPUs, and held the third and fourth-place results in recommendation systems, with XEON-based and EPYC-based systems, respectively.
Graphcore, the Bristol, England-based startup building computers with an alternative chip and software approach, took fifth place in ImageNet. IT solutions provider Nettrix took fourth place in the image segmentation competition and fourth place in the Go reinforcement learning challenge.
The top five submitters in each of the eight benchmark tests, with number of minutes it took them to train the neural nets listed for the tasks listed. A smaller number means less time to train, which is better.
In a briefing for journalists, Graphcore emphasized its ability to provide competitive scores versus Nvidia at lower prices for its BowPOD machines with varying numbers of its IPU accelerator chips. The company touted its BowPOD256, for example, which had the fifth-place score in ResNet image recognition, being ten times faster than an 8-way Nvidia DGX system, while costing less money.
"The most important thing is definitely the economics," said Graphcore's head of software, Matt Fyles, in a media briefing. "We have had a trend in past of machines getting faster but more expensive, but we have drawn a line in the sand, we won't make it more expensive."
Although some smaller Graphcore machines trail the best scores or Nvidia and Graphcore by a coupe of minutes of training time, "None of our customers care about a couple of minutes, what they care about is whether you're competitive and you can then solve the problem that they care about," he said.
Added Fyles, "There are a lots of projects with thousands of chips, but now industry is going to expand what else you can do with the platform rather than just, We've got to win this benchmark competition — that's the race to the bottom."
As in past reports, Advanced Micro Devices had bragging rights over Intel. AMD's EPYC or ROME server processors were used in 79 of 130 systems entered, a greater proportion than Intel XEON chips. Moreover, 33 of the top 40 results across the eight benchmark tests were AMD-based systems.
As in past, Intel, in addition to having its XEON processor in partner systems, also made its own entries with its Habana Labs unit, using the XEON coupled with the Habana Gaudi accelerator chip instead of Nvidia GPUs. Intel focused the effort only on the BERT natural language test but failed to crack the top five.
Also: Nvidia makes a clean sweep of MLPerf predictions benchmark for artificial intelligence
Seven of the the eight benchmark tests were all the same as the December competition. The one new entry was a replacement for one of the object detection tasks, where a computer has to outline an object in a picture and attached a label to the outline identifying the object.
In this new version, the widely used COCO data set and SSD neural network were replaced with a new data set, OpenImages, and a new neural network, RetinaNet.
OpenImages uses image files that are higher than 1,200 by 1,600 pixels. The other object detection task still uses COCO, which uses lower-resolution, 640 by 480-pixel images.
In the media briefing, the MLCommons's Kanter explained that the OpenImages data set is combined with a new benchmark neural net for submitters to use. The prior network was based on the classic ResNet neural net for image recognition and image segmentation.
Also: Nvidia and Google claim bragging rights in MLPerf benchmarks as AI computers get bigger and bigger
The alternative used in the new test, called RetinaNet, improves accuracy via multiple enhancements to the ResNet structure. For example, it adds what's called a "feature pyramid," which looks at all the looks at the context around an object, in all layers of the network, simultaneously, rather than just one layer of a network, which adds context to enable better classification.
"Feature pyramids are a technique from classic computer vision, so this is in some ways a riff on that classic approach applied in the domain of neural networks," said Kanter.
Also: Google, Nvidia tout advances in AI training with MLPerf benchmark results
In addition to the feature pyramid, the underlying architecture of RetinaNet, called ResNeXt, handles convolutions with a new innovation on ResNet. Classic ResNet uses what are called "dense convolutions" to filter pixels by the height and width of an image as well as the RGB channels. The ResNeXt breaks the RGB filters into separate filters that are known as "grouped convolutions." Those groups, operating in parallel, learn to specialize in aspects of the color channels. That also contributes to greater accuracy.
Also: MLPerf benchmark results showcase Nvidia's top AI training times