Spell introduces MLOps for deep learning

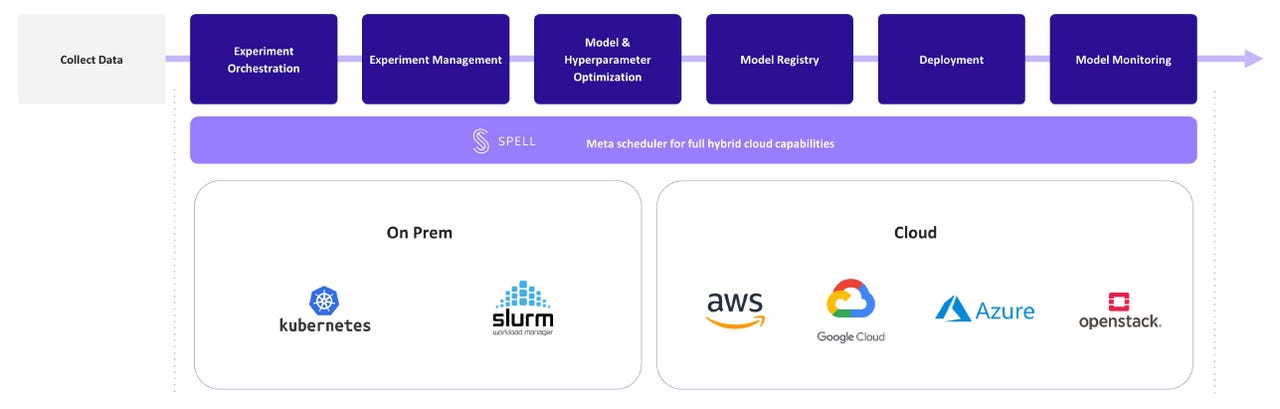
Spell DLOps high-level architecture
The machine learning operations (MLOps) product category has been moving quickly, especially in the last year, and several platforms have emerged to take it on. Cloud providers including AWS and Microsoft, analytics players including Databricks and Cloudera, MLOps pure plays like Algorithmia, and even open source projects like MLflow, offer integrated platforms to manage machine learning model experimentation, deployment, monitoring and explainability. Now Spell, a New York City-based MLOps startup, is providing an MLOps platform specifically geared to deep learning. As such, Spell refers to its platform, announced last week, as facilitating "DLOps."
Also read:
- Databricks ups AI ante with new AutoML engine and feature store
- Cloudera's MLOps platform brings governance and management to data science pipelines
- Cloudera Machine Learning MLOps suite generally available as it aims to manage models, analytics
ZDNet spoke with Spell's head of marketing, Tim Negris as well as its CEO and co-founder, Serkan Piantino (who previously served as Director of Engineering at Facebook AI Research, and who opened Facebook's New York City office). The duo explained that most of today's prominent MLOps platforms cater to conventional machine learning (classification, regression, clustering and the like) and not to deep learning, which builds models by layering multiple neural network structures in an ensemble. That gap in the market is the motivation behind Spell's DLOps platform.
Special requirements
Why does Spell see DLOps as a distinct category? Piantini and Negris explained that deep learning applies especially well to scenarios involving natural language processing (NLP), computer vision and speech recognition. Deep learning models are typically more complex than their conventional ML model counterparts and aren't likely to be trained on a data scientist's laptop. Instead, deep learning model training benefits from additional -- and more powerful -- cloud-based hardware, including CPU-based compute but especially GPU-based compute, as well. The latter can be quite expensive when it comes to deep learning model experimentation and training, so an MLOps platform capable of wrangling and cost-managing such hardware in the cloud is critical.
Piantino and Negris described the Spell platform and pointed out how carefully it manages availability and costing of CPU- and GPU-based cluster nodes. An especially interesting capability of the Spell platform is that it can create pools of cloud spot instances and make them available to users on an on-demand basis. Spell Virtual On-Demand Instances, therefore, provide on-demand usage at spot instance pricing, which represents significant savings for customers, especially in the case of GPU resources for training complex deep learning models.
Since spot instances can and often are often interrupted, the Spell platform is designed to be resilient around that very scenario, allowing long-running training jobs to be conducted, even in the case of preemption, without user intervention. Spell does this through its ability to reconstitute a deep learning environment on a new instance, carefully tracking the full genesis and lineage of such environments. This approach also aids in model reproducibility, and retraining models under the same configurations as those of their initial training environments.
DLOps vs. MLOps
The Spell folks didn't just discuss their platform, they demoed it, too. As they did so, it became clear that many of the accoutrements of standard MLOps (and even AutoML) -- including experiment management, a model repository, lineage, monitoring and explainability -- are present in Spell's DLOps platform as well. As such, it sure looks like DLOps is a superset of conventional MLOps, and I asked Piantino and Negris if that was the case. The two agreed that, technically speaking, my conjecture was correct, but explained that Spell is nonetheless targeting deep learning use cases specifically. Spell sees the deep learning segment of AI as the one with the most momentum and action.
Negris and Piantino explained that conventional MLOps platforms are eventually adopted once organizations mature to a certain scale and volume of machine learning work. But most customers doing deep learning, the pair explained, really need an ops platform from Day 1. This explains why Spell is really focused on this market -- since it has urgent requirements and needn't be educated to understand why it will eventually have a pain point to remedy. Instead, deep learning customers feel the pinch immediately.
With this in mind, it looks as if MLOps and DLOps aren't so different, but that deep learning stress tests an MLOps platform more strenuously than traditional machine learning does. In essence, the DLOps requirements of today may become the conventional MLOps requirements of tomorrow. Whether the two subcategories will therefore someday merge is unclear; what is clear is that Spell is casting its platform over a legitimate and demonstrated need, to optimize and operationalize deep learning into the enterprise mainstream.