Supercharging your image: Machine learning for photography applications

A picture is worth a thousands words. Whether this cliché should always be taken at face value may be debatable, but the fact is that images are a key component of telling stories and getting attention.
While applications such as full text search have been helping users efficiently find the documents they need for a while now, similar applications for images have been lagging.
Documents can be indexed, summarized and compared with relative ease, which means document applications can be built with similar ease. Images on the other hand are harder to describe, and require much more storage and compute power to process.
Progress in storage and compute has resulted not only in increased ability to store images, but it has also unlocked previously unavailable capabilities. Pioneered by tech juggernauts such as Google and Microsoft, image applications powered by machine learning are finding their way to photography professionals.
Let's take a brief ride in the illustrious world of illustration, check out what are the options for building custom image applications, and how Shutterstock, one of the world 's iconic photography companies, is using them to supercharge its user experience and grow its business.
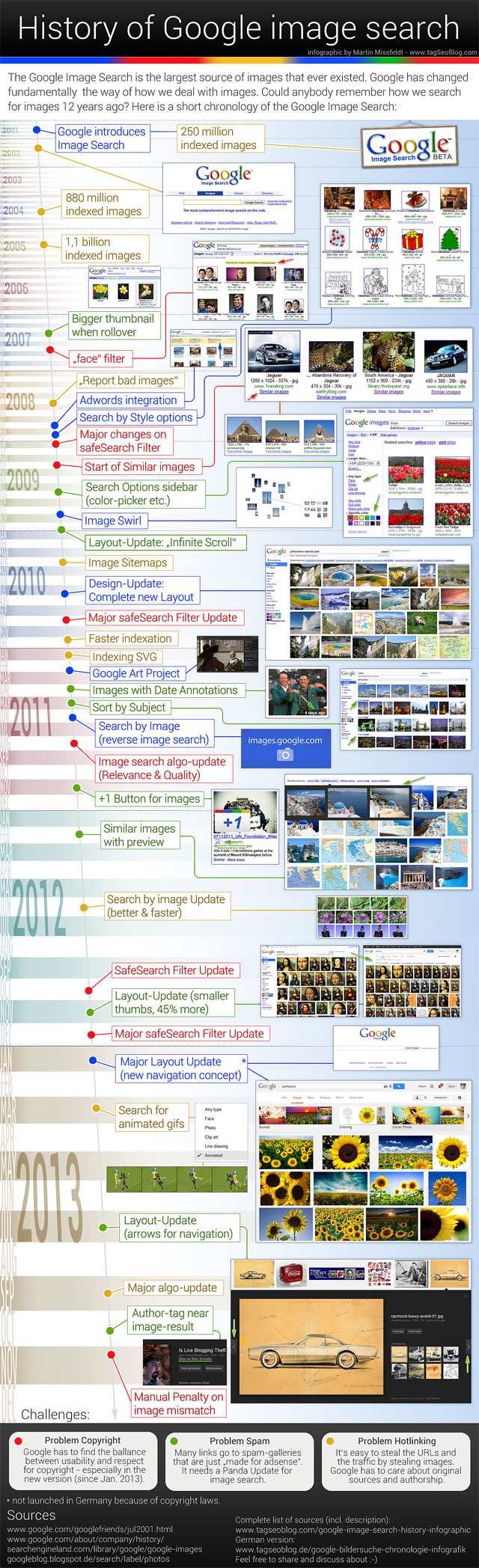
Google has paved the way in image search. Image: Martin Missfeldt / tagSeoBlog
Public image search is easy, when done by experts
So, you want to find the right image for that post of yours. Where do you begin? If you're just looking to share something privately, search engines such as Google or Bing are an obvious choice.
Both have incorporated image search long ago. Initially image search followed similar principles to text search, and was also performed utilizing text. Users would provide keywords as input, and search engines would utilize their indexes of text found in and around images (in image metadata and containing documents) to find matches.
That works, but is not perfect. Results depend on how well images are annotated and what kind of documents they are contained in. This means the image you are looking for may be out there, but if there is a mismatch between your query and the text available to search engines..tough luck.
This is why Google pioneered the image search space by introducing reverse image search in 2011. Using reverse image search means users can search for any image as long as they can point to a similar one, regardless of textual descriptions.
This powerful feature was made possible courtesy of machine learning, as finding similarity among items in massive datasets is something ML excels at. Microsoft has followed suite with Bing, and both search engines have been evolving their image capabilities.
That's all fine and well if you are a casual image seeker, but things change if you want to search for images to use in a professional context. Whether it's images in your own repositories, or images traded by photography professionals, things are not that easy.
Going pro is hard, regardless of your expertise
While neither text-based image retrieval nor reverse image lookup are perfect in their own right, their combination can cover many use cases. The problem is however that both are hard to implement.
Text-based image retrieval requires quality annotation to work, and that is a hard and expensive task. Reverse image lookup requires ML expertise and substantial resources for implementing and training the right models, which is not something all organizations have.
This is why the tech juggernauts have rushed in to fill in that void by providing expertise and resources distilled in the form of APIs. Google, Microsoft, Amazon and IBM, as well as startups like Clarif.ai and Cloudsight among others, offer image recognition APIs that promise to make years of research and engineering available to anyone willing and able to pay the price.
This is a solution that many organizations will be happy to adopt. Who wants to go into the trouble these trailbalers went into to build something that will probably be subpar in comparison?
That makes lots of sense, unless of course images happen to be your core business. In that case, advanced image functionality is not a nice-to-have, it's something your business depends on.
Shutterstock is one of the world's biggest photography companies. In the past, Shutterstock's search algorithm was only powered by keywords provided by its contributors. Kevin Lester, Shutterstock VP of Engineering - Search, shares the story of Shutterstock's evolution.
Lester emphasizes that annotation and metadata are very important to Shutterstock's business, as it enables image retrieval and lets customers learn more about the images in front of them.
For Shutterstock annotation is not an issue, as its contributors provide this information when they submit content. Lester however says they noticed that entering keywords, while helpful, can sometimes be a barrier for more creative-minded users as it's difficult to put the image they have in mind precisely into words.
That's why Shutterstock wanted to provide alternative ways for people to find what they need faster. Shutterstock decided to invest time and resources in tools that enhance their user experience, and Lester says it was only natural for them to introduce reverse image search:
"If you have inspiration you spotted on social media or from an image you took yourself, we can guide you to a similar, licenseable, high-quality image in our collection. This tool is instrumental in bringing efficiency and accuracy to the customer experience".
Reverse image search and image similarity work leveraging progress in deep learning algorithms. Image: Shutterstock
Lester notes that it was breakthroughs in deep learning a few years ago that enabled them to solve much more complex problems than was previously possible. They spun up a new tech team with the explicit goal of leveraging these breakthroughs to further their understanding of media, and to enable new cutting-edge discovery experiences:
"Initially, it required heavy research and experimentation on gaming rigs with GPUs to learn the new technology. As the team started to produce results, we worked with our data center team to procure production-ready GPU hardware that we eventually pushed toward production.
Tool availability was limited too. We relied primarily on Caffe because we found it to be the best tool available at the time. Since then, we have seen many new tools introduced to the field, as well as the maturing of other tools including Torch, Tensorflow, Theano, Cuda-convent, PyTorch, and more.
As new versions of each tool are released we evaluate each one for their strengths and weaknesses. We have switched DL frameworks twice so far thanks to the advances we've seen in the tooling".
Mind your training data and storage, reap the benefits
The good thing for Shutterstock is that it has some of the best image training data in the world: "Each of the 125+ million images available in our collection is already human annotated and keyworded. Similarly, as customers search and download images, we get a clear picture of which keywords are best for the image.
That information is essential for training image data. Because of this data at our disposal, we were able to use our existing customer behavior data to train our models".
But a large training set is a double edged sword, as DL libraries need rapid access to it to leverage it efficiently. Lester says this was somewhat unappreciated when they started: "We had to work with our storage team and also tweak some of the hardware components in our training machines to get the bits to the GPU as quickly as possible.
Training was slow at first, since the tools were also not mature enough to support multiple GPUs in an efficient way; training would take weeks to complete. Today, it varies. As GPUs have gotten faster, our models have also gotten more complex so it can still take time to fully train some of our bigger models".
It sure has not been easy, which is why this was only released in 2016. Was it worth it? Lester says there is a data scientist who sits within the computer vision team, studies what's happening and makes suggestions based on the findings.
Shutterstock has found that people who used reverse image search for searches wind up making more downloads per search than typically expected from users utilizing text-based search. And those who choose reverse-image search for searching are more likely to make a purchase after they have performed their search.
Plus, with a growing community of over 225,000 global contributors, and customers in more than 150 countries, language and translation can be a challenge. Shutterstock has found reverse image search especially useful in breaking down language barriers.
Lester says this new direction was met with pure enthusiasm by CXOs, and they've been racing since the first day to identify new solutions. Shutterstock is also using ML technology in Webdam, a Shutterstock division, to recommend relevant keywords for users to select from.
Keyword suggestions works based on image recognition. Image: Shutterstock
Lester notes using ML to automate a process that was often haphazard and required hours of time is a tremendous improvement: "I can imagine a future where keywording is no longer necessary. As our models evolve and get better at identifying with high accuracy aspects like location, I think we can start to reduce our reliance on keywords.
Ideally, it would be a seamless experience where customers can take amazing photos and instantly get them into our marketplace". Lester mentions their technology is also used in the Shutterstock mobile app, as mobile phones have become a center a gravity for photography.
The future of photography
It all seems to make sense, and Shutterstock is not alone in realizing this. Although Lester says he considers this to be "the strongest offering of its kind in the industry", others will surely beg to differ.
Getty, a traditional Shutterstock competitor, does not seem to have something akin to reverse image search. They do however leverage ML for an application that keeps track of image-related activity on the web and social media, and they also seem to be building up their team and offering.
EyeEm, a new entry in the photography business, seems to be focusing its value proposition on ML-powered features and a community approach. EyeEm claims to have the best image search around, and has also introduced mobile app features such as helping users choose their best shots.
So is the future of photography all about automation? Lester says he does not think of computer vision as automation: "success really depends on a combination of man and machine. Not only is the machine mastering our collection over time, but we're also studying what it's learning and how we can tweak it to make it even smarter.
There will always be a need for people to monitor and manage sophisticated algorithms. A healthy balance of man-made tools and machine-learning features is the right strategy and direction for us".