Want to discover the knowledge graphs in your enterprise data? Siren just secured $10 Million to help do that

Graph databases are amazing, but the knowledge graph is in your data already. That's the key message Siren has been advocating, and today it raised $10 million in Series A financing led by Atlantic Bridge to help amplify the message and develop the technology. The investment also includes DVI Equity Partners, Frontline Ventures and Enterprise Ireland.
Siren, which dubs itself the investigative intelligence platform, developed as a spinout from big data and knowledge representation research by founders Giovanni Tummarello and Renaud Delbru. As part of DVI Equity Partners investment Siren is adding industry veteran Bob Griffin in its Board of Directors.
The Siren platform provides a combination of search, business intelligence, big data, link analysis and knowledge representation which it says advances the way organizations address some of the world's most important data driven problems.
Unifying Search and Knowledge Graphs for the win
Tummarello and Delbru got started with search and knowledge graphs back in 2007 as researchers. Knowledge graphs were not yet a buzzword, although the underlying technology (Semantic Web, or Linked Data, or Web of Data) was enjoying its own hype.
Web pages were annotated with bits of metadata: machine readable information like "author" or "price". This was embedded in HTML in formats such as microformats or RDF, which were then adopted by Google in Schema.org. Tummarello and Delbru set out to index them and make them discoverable in a search engine for the Web of Data called Sindice.
Sindice's contributions made their way through open source Apache Foundation projects and search engines Lucene and Solr before folding. Although being able to index and search a 30 billion edge knowledge graph is no small feat, commercialization did not quite work out.
But that only served to launch Tummarello and Delbru to their next endeavor: Siren, the Semantic Information Retrieval Engine. In 2014 Siren's founders set off to combine Knowledge Graphs and indexing to bring value to the enterprise. Knowledge Graphs excel in integrating various data sources, and index-based search is the easiest way to access that data.
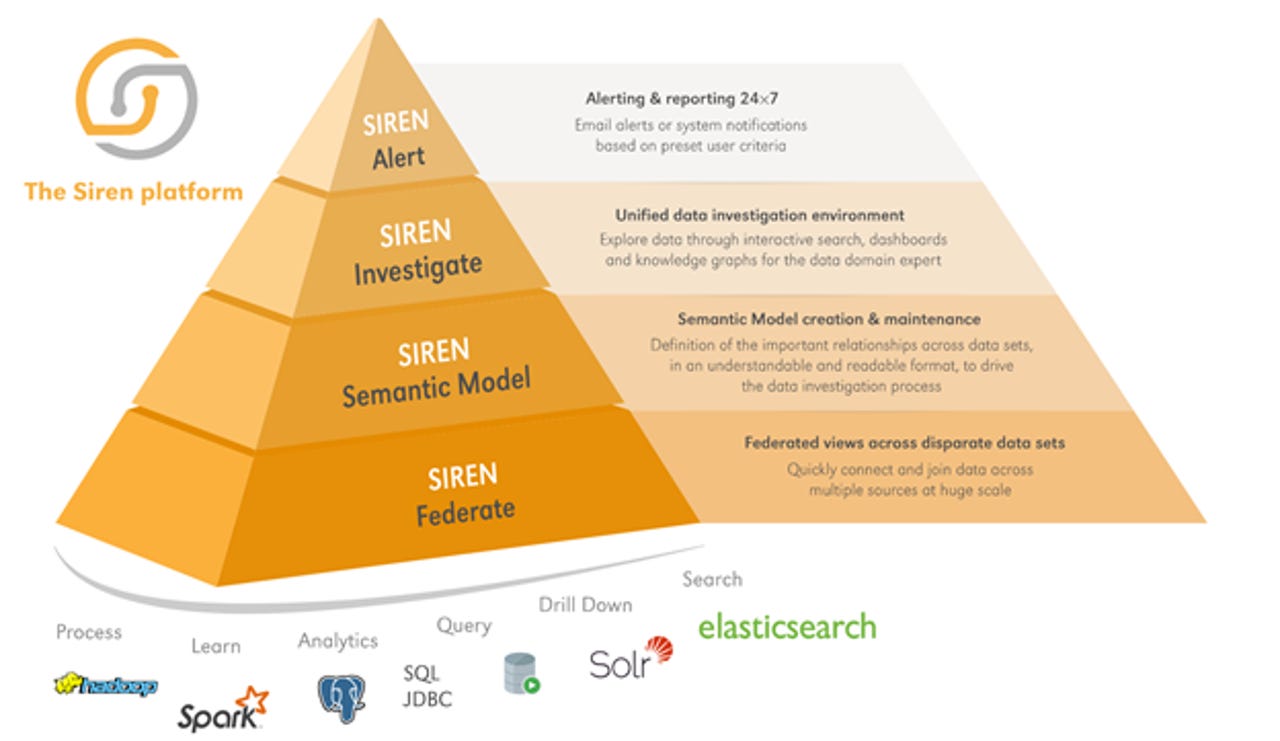
Siren has a layered architecture, helping get the best of knowledge graphs, search, and visualization
By that time, open source platform Elasticsearch with its Kibana visualization layer and rich plugin ecosystem was a big hit in the developer community, and it was used in many Enterprises. Siren decided to capitalize on Elasticsearch, by offering a layered approach to getting the best of both worlds.
Siren's core is indexing remote data sources. In its Federate plugin for Elasticsearch, standard Elasticsearch capabilities are further enhanced by data federation. Remote JDBC datasources are virtualized and exposed as if they were local indexes, with joins pushed down to the native sources.
This is the strategy Siren takes for other datasources too. Siren says the distributed technology enables scenarios where one can drill down on queries expressing complex relations across data from various sources, including logs.
This is what enables Siren to address what it calls investigative use cases, that benefit from exploring connections. For example, scanning hundreds of millions of daily call data records to find answers to questions such as "Which phones made calls on Mondays 10am to 11am within 10km of this location and were within 5km of this other location at 2pm?"
Building on Elasticsearch
Knowledge graphs without the ETL (Extract-Transform-Load) process sounds like an attractive proposition. Especially when coupled with visualization. Siren follows a similar approach for its front-end, too. It builds on Kibana, Elasticsearch's native UI, adding what it calls "Investigative Intelligence" advanced capabilities.
Siren adds the ability to do things such as relational data navigation and correlation and link analysis, working with data from any kind of source. Officially supported sources include PosgreSQL, MySQL, SQL Server, Oracle, Sybase, Presto, Spark, Dremio and Impala. Tummarello noted Siren can also work with any source that supports SQL via JDBC, and is in the process of adding support for graph databases like Neo4j.
As should be apparent, Siren largely relies on Elasticsearch infrastructure. This begs the question what is the exact nature of their relationship, and whether Siren competes with Elasticsearch on some level. For one thing, Siren also announced filing some patents for Extensions of the Elasticsearch engine.
As Tummarello clarified, these are 2 different products, and each one comes with its own licensing.Siren has a free community edition, and 2 edition with different capabilities called It and Business. Siren only focuses on extensions for high end data scenarios, and is in fact in discussions with Elastic on how to best collaborate, as they believe this will be of huge benefits to our customers, Tummarello went on to add.
Link analysis in Siren, connecting to Neo4j
Although core Siren is not open source, Tummarello also said Siren has been contributing historically to Elasticsearch year over year, with pull requests typically about bug fixes or sharp edges. Siren people also hope to release components which are compatible with the latest versions of the Kibana stack for increased ease of interaction between Siren and the Elastic native tools in the near future.
This is all fine and well, of course, but there is an obvious implication. If you want to install Siren on top of a commercial Elasticsearch licence, which Tummarello said is the best option as Siren can then leverage a lot of the functionalities only available in there, you have to purchase that license, too.
That also means that Siren is in a way dependent on Elasticsearch, so no wonder Siren is considering some way of working with Elasticsearch. That would actually be a good thing for Elasticsearch, too: it would enable it to reach clients with investigative use cases in industries such as Finance, Life Sciences, Law, Telcos, and Cybersecurity, which are the industries Siren lists as typical clients.
Dealing with complexity
The other thing to wonder about Siren's approach is how fast and full-featured it is, compared to a graph database. Tummarello said Siren leverages graph databases, and that's the beauty of it. He pointed out for example how Siren can be used with Neo4j for shostest path or suspect patterns analysis, sending queries directly to the graph database:
"What we're saying here is: for an enterprise knowledge graph approach you don't need to copy everything into a graph database. It may make sense in some cases, so you get things like shortest path graph algorithms, for others you can just leave data where it is, for example if you simply want to navigate".
Big Data
The other thing we noted, based on what we've seen, is that this looks complex. Wondering on how do people onboard themselves and whether they find it easy to use Siren, Tummarello noted that analytics per se is not terribly easy. He cited Tableau as one of the most intuitive and widely used BI tools, and said using that, or even pivot tables in Excel, comes with complexity.
Siren combines Tableau style analytics with link analysis and a graph visualization UI and enables users to ask deep questions, and that comes with some complexity too, Tummarello said. He pointed out that for people familiar with Elasticsearch, Siren is easy to grasp, and there is a community edition and community help, documentation, tutorials, and formal training in the works.
Machine learning is one way to help dealing with complexity. Siren has recently added ML features.
Siren has also gotten on board with machine learning powered features. Siren 10.3 introduced Siren Machine Learning (Siren ML). Designed to leverage modern open-source machine-learning frameworks such as TensorFlow and running in cloud-compatible Docker environment, Siren ML aims to provide data investigators with a way to reap the benefits of using state-of-the-art "auto" machine-learning methods on their data.
That's a lot to digest. Tummarello said Siren has been developing so fast that it's guaranteed to have rough edges here and there. He went on to add, however, that they are looking forward to working with people who want to understand their knowledge graphs, and to improving.
In 2018, Siren raised $4 million in seed funding which has enabled it to expand its offering and target new markets. This $10 million round can help Siren improve in more ways, and results should be visible soon.
DISCLOSURE: As a knowledge graph expert, the author has a business relationship with many companies active in the domain, including Siren. The author does not have a stake in Siren.