Azure HDInsight click-by-click guide: Get cloud-based Hadoop up and running today

Click by click
In this gallery, we'll show you how to provision, log in, work at the command line, use some basic tools, and then connect to data in your HDInsight cluster from Excel and Power BI.
Get started
The first few clicks in setting up HDInisght are easy: first click the "New" button (rendered as a "+" sign) on the upper left, then select the "Intelligence and analytics" category, and finally select HDInsight itself. These selections are highlighted in red rectangles in this slide. Subsequent slides are likewise visually annotated.
Provisions
The HDInsight provisioning "blade" is the next one to appear in the Azure portal. Several of the items in the blade will open up additional blades, to the right, for the details. We'll go through the important ones in this gallery.
What's your name?
Start by entering a name for your cluster. The name must be unique across all HDInsight clusters, because ".azurehdinsight.net" will be appended to it to render the Internet hostname with which you will connect to it.
After entering the name, a green check mark will appear to the right if the name passes the uniqueness test. If the check comes up before you're done typing, that's OK; just keep entering characters until you're done, then confirm that the check mark appears again. If you see a red exclamation point instead, it means you need to modify the cluster name.
When you're done, click on the "Cluster configuration" section of the form, below the "Cluster name" section.
Cluster configuration
Now you need to specify the type of HDInsight cluster you'd like and then, depending on the type selected, select a version of HDInsight (and Hadoop) you'd like to use. You may also need to select an operating system. We'll look at cluster type and operating system options in the next two slides.
Pick a cluster type
Here's the full list of cluster types. The Hadoop type is just that -- a cluster configured in a general way for general Hadoop tasks. While that cluster type does include other components, including HBase (a NoSQL database whose tables are Hadoop Distributed File System files), there is nonetheless a cluster type that is optimized for HBase work. The third type is optimized for streaming data applications using Storm. Another cluster type is geared to working with the distributed in-memory technology known as Spark, which also includes developer "notebooks," which we'll look at later.
The Interactive Hive cluster type is in preview, and lets you work with a new mode of Hive called LLAP (Live Long And Process) which uses caching and other optimizations to deliver what the development team behind it says are sub-second query response times. The penultimate cluster type lets you code against Spark using Microsoft's R Server (MRS) product, and the last type lets you build streaming data applications using Kafka.
Hadoop, HBase, Storm, Spark, Hive and Kafka are all Apache Software Foundation open source projects.
Operating system selection
In the wider world of Big Data, Hadoop always runs on Linux. But HDInsight's original claim to fame was that it was a Microsoft- and Hortonworks-produced port to Windows. Microsoft now offers Hadoop running on either operating system, but Linux is now the de facto default, and only the first three cluster types listed in the last slide are available on Windows.
Pictured here is the selection of the generic Hadoop cluster type, with Linux selected as the OS. Note the five features, highlighted at the center-left, that are available because of this selection and the one feature, highlighted at the center-right, that is not.
Perhaps the most noteworthy feature that is available due to the selection Linux as the OS is that of "HDInsight applications." Since the Hadoop ecosystem is fully Linux-focused, many third party applications are compatible with HDInsight only when it runs on the open source OS.
Your credentials, sir?
Your HDInsight cluster will be an Internet-facing resource. As such, you'll need to set up login credentials so that only authorized parties can connect to it. In fact, you'll need two sets of credentials, one for connecting to browser-based management tools and Hive databases, and another for establishing SSH (Secure SHell) terminal sessions.
This blade in the portal lets you specify both credential pairs. Note that the usernames cannot be the same and, while both must have complex passwords, the particular rules governing password character and length requirements are different for each of the two credential sets.
Want files with that?
The Data Source settings for HDInsight clusters may seem complex at first, but there's a very simple explanation that will clarify what's going on: HDInsight's implementation of HDFS (the Hadoop Distributed File System) is based on Azure blob storage. As such, you must specify an Azure storage account and blob container that will constitute the HDFS volume for your cluster.
You can use an existing account or create a new one on-the-fly. The scenario shown here is one where the user is about to click the "Select existing" button to use an Azure storage account that has already been created.
Which account?
In this screen we're selecting a specific, pre-existing storage account.
Container selection
After you've picked your storage account, type the name of a new or existing blob container, within the account, to use for your cluster's file storage. Picking an existing container lets your new cluster reconnect to storage used by a previously de-provisioned HDInsight cluster. Watch for the highlighted green check mark -- it indicates that the container name you've specified has been validated. Now click "Select" to move on to the next provisioning step.
Sizing
Click on "Cluster size" in the main provisioning blade to open the "Pricing" blade, which lets you size your cluster. Specifically, you can pick the number of worker nodes in the cluster. Each node is a separate Azure virtual machine, so the more nodes you have, the more it will cost to run your cluster. The default number of worker nodes is 4. Adjust the number up or down, depending on your needs. The updated cost per hour to run the cluster will be displayed in the middle of the blade. If you're just creating the cluster for hands-on learning purposes, you may wish to size it at just 1 or 2 nodes.
Optionally, you can also specify the virtual machine type to be used for head nodes and/or worker nodes. When you're done, click the "Select" button to move on.
And...scene!
You're at the finish line now! Specify the name of a new or existing Azure resource group, to contain all of the provisioned resources, check the "Pin to dashboard" checkbox and then, when you're ready, click the "Create" button. Note the estimated provisioning time for a default Hadoop cluster is 20 minutes -- and other types can take longer. So after you click "Create" you'll be able to take a little break.
Please stand by...
Before you go though, wait for the portal to redirect you to your dashboard and watch for the tile pictured here to show up. It provides nice positive feedback that work is actually going on and your cluster is being built. (Note that if you neglected to click the "Pin to dashboard" checkbox in the previous step, this tile will not appear.)
Cluster ready
When deployment has completed, the Azure Management portal will redirect you to this screen. Note the many available options, including those for opening up the cluster dashboard and scaling (resizing) the cluster, as well as links to documentation and "Quickstart" materials.
Beam me up
Click the "Cluster dashboard" button at the middle of the screen and the "HDInsight cluster dashboard" button will appear towards the upper-right. Click that button to connect to Apache Ambari, the open source Hadoop management console software used by HDInsight.
What's the password?
Before you can get into Ambari, you'll need to provide credentials. Use the first user ID and password pair you specified when provisioning the cluster. Note also that if you'd like to come back to Ambari without using the Azure management console, you can simply point your browser at https://<clustername>.azurehdinsight.net, where <clustername> is the name you assigned to your cluster during provisioning ("bluebadgehdi" in this case).
Bienvenidos al Ambari
Assuming you entered your credentials correctly in the challenge login dialog, you should now find yourself at the main Ambari screen. While this tool is designed for cluster management (note the list and performance indicators for all the services running on the cluster), our purpose here is to use an Ambari "view," specifically designed for Hive (which I'll describe in the next slide). Access to that view is obtained by clicking on the "tic tac toe" icon toward the right of the upper nav bar, then choosing "Hive view".
Back home again
Thus far, the entire HDInsight environment may have felt a bit alien, but now just about any developer or data person should feel at home. That's because Hive is nothing more than a SQL-based database system, implemented on HDFS, and this Hive view provides a workspace for entering and executing queries in HiveQL, Hive's dialect of SQL.
On every HDInsight cluster, Hive is pre-configured with a single table of sample data called, logically enough, "hivesampletable." In the Databases tab at center-left, drill down on the "default" database's node and you'll see a node for hivesampletable appear. In the worksheet pane, you can enter a simple SELECT * query against the table, and click "Execute" to see its structure and content.
The results are in
After a short pause, the result set will appear. Note that hivesampletable contains data pertaining to cell phones and their communication with cell towers, including the operating system, manufacturer and model of the phone (in the "deviceplatform", "devicemake" and "devicemodel" columns), the state and country where the tower is located ("state" and "country" columns) and the duration of the interaction between the device and the tower (the "querydwelltime" column).
Other columns are present but these will be the ones we'll be most interested in.
Make me a chart
Click the chart button towards the center-right of the screen and you'll be taken to a screen where you can graph your query results rather than view them as text in a grid. In this case, we've selected deviceplatform for the x axis, SUM of querydwelltime for the y axis and bar chart as the visualization type.
Not bad for a simple query facility buried in the cluster's admin console!
Show me yours
If you don't feel like building charts manually, just click the "Data Explorer" tab towards the top-left to see a bunch of automatically-generated charts instead. Some of the generated charts will be more useful than others.
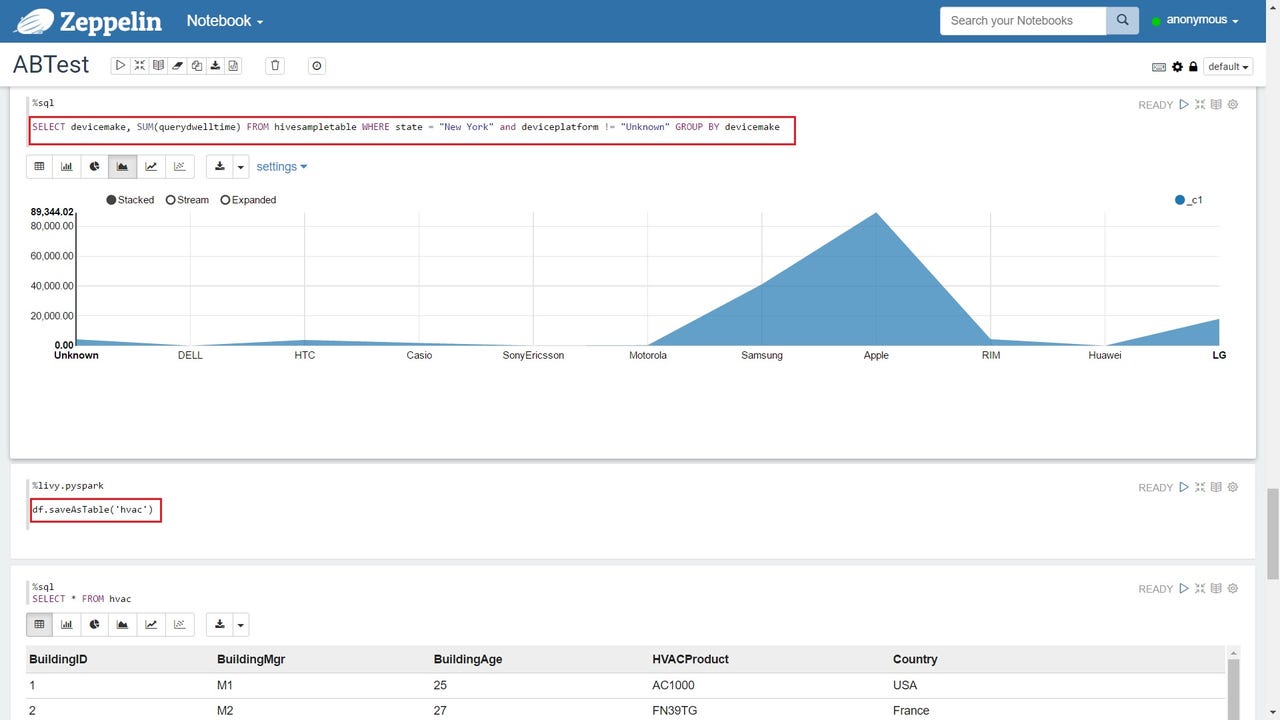
Zeppelin notebook
There are other places to run your queries, of course. For example, users of the Spark cluster type will have access to Zeppelin and/or Jupyter notebooks. Notebooks are sort of a mashup of wiki pages, code editors and code output; users of the Spark cluster type can use notebooks to write code against Spark in Scala or Python.
Zeppelin notebooks are available when you select "Spark 1.6.2 (HDI 3.5)" in the "Version" drop-down of the "Cluster configuration" blade during provisioning. This slide shows a Zeppelin notebook with a small bit of Python code toward the bottom, and some Spark SQL code (HiveQL, essentially) at the top. The output of the SQL query has been visualized as an area chart.
A really good SSHow
Another way to connect to and work with HDInsight is via the command line, over an SSH terminal session.
Back in the Azure portal, click the "Secure Shell (SSH)" button towards the bottom-left, then copy the SSH command string into your clipboard using the "Click to copy" button towards the center of the screen.
Kicking off the connection
The command string you've copied into your clipboard will work as-is in a terminal window on the Mac or at a Linux command prompt. If you're running Windows 10 and have installed its new Windows Subsystem for Linux (a preview feature), you can also use the command directly at the Bash on Ubuntu on Windows prompt, as shown here.
If you're running a version of Windows earlier than Windows 10, or don't have the Windows Subsystem for Linux installed, copy just the SSH hostname from the portal, rather than the entire command line string. You can then download the PuTTY application for Windows and fire up an SSH connection there.
As you can see in this screen capture, pasting in the command string and entering the SSH password (from the second set of credentials you entered) gets you to the Linux command prompt on the head node of your HDInsight cluster. From there, you can perform a number of tasks using the various services' command line interfaces.
Old School
Want to run a MapReduce job on your cluster? Doing it over SSH is perhaps the easiest way. The command shown here runs the WordCount MapReduce sample using /example/data/gutenberg/davinci.txt as the input file and /example/data/WordCountOutput as the output folder.
MapReduce, reduced
Here's the job run output of the MapReduce job, viewed over the same SSH connection. Note the successive progress status messages for both the map and reduce steps of the job.
So PoSh
Since it's a Microsoft service, PowerShell commandlets are available for all aspects of working with HDInsight, including provisioning clusters and running jobs. The code shown here, in the PowerShell ISE, runs the same MapReduce job that we just saw in the SSH session.
Connecting to data from external tools
Not only does Hive provide a SQL interface over data in Hadoop, but it works over ODBC (and JDBC) as well. That means you can connect to Hive data using external BI tools, or even just Excel.
Shown here is the first step in setting up a connection to Hive over ODBC from Excel 2016 for Windows (after clicking Data/New Query/From Other Sources/From ODBC). You'll need to download the Microsoft Hive ODBC driver before you can do this. You'll also need to configure the Data Source Names (DSNs) the installer sets up, pointing them to your cluster, and authenticating with the first of the two credential sets you created during provisioning.
Show me the data
Once connected to the Hive server, drill down on the various tree nodes at the left of Excel's Navigator dialog to reveal the node for the table you're interested in (hivesampletable in our case). You'll see a preview of the data on the right, and you can then click the "Load" button to bring the data into the Excel workbook.
Familiar territory
It will take some time, but eventually the Hive data will load directly into your spreadsheet. Notice the Workbook Query task pane to the right, which indicates data retrieval progress while data is loading and a final row count when the load is complete. Click the "x" to close the task pane if you'd like. The data can now be manipulated as any regular spreadsheet data could. You can also build charts from it.
The end
Speaking of charts, Power BI Desktop (a free download for Windows) can connect to Hive over ODBC too, using almost the same procedure as that used in Excel. A full Power BI report page against the hivesampletable data is shown here. Other BI tools, like those form Tableau and Qlik, can connect to Hive, and visualize its data, in fashions similar to what I've shown here for Excel and Power BI.
That's the end of our tour. If you've worked with Hadoop before, much of what we've seen after provisioning may have looked familiar. Other pieces may have been new. Regardless, you should now be ready to do big data analysis, in the cloud, with HDInsight.