Hands-on with Azure Data Lake: How to get productive fast

A data lake, in the cloud
Azure Data Lake is Microsoft's cloud-based mashup of Apache Hadoop, Azure Storage, SQL and .NET/C#. It gives developers an extensible SQL syntax for querying huge data sets stored in files of various formats, and it's accessible from the browser, from Visual Studio and even from BI tools.
In this gallery, I'll show you the ins and outs of the service's two main components: Azure Data Lake Store (ADLS) and Azure Data Lake Analytics (ADLA). I'll also introduce you to the provisioning process; the relevant tooling; the SQL dialect and its .NET integration; and how data in Azure Data Lake can be queried from external tools like Power BI.
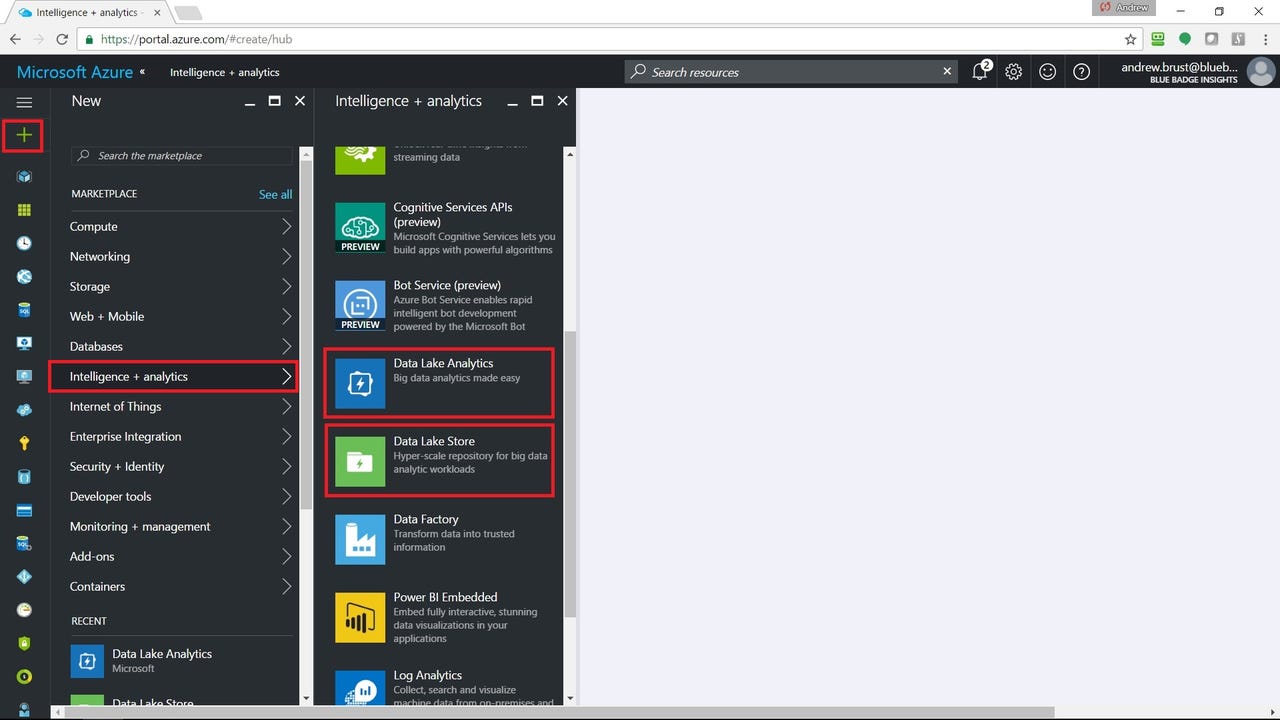
Pick your service
Getting started with Azure Data Lake is pretty easy. Just hit the "+" button on the upper-left-hand corner, choose "Intelligence + analytics," scroll down, and you'll see both relevant services: Data Lake Store and Data Lake Analytics. Set up Data Lake Store first.
Open the store
Setting up Azure Data Lake Store (ADLS) is also pretty easy. Enter a name for the account (it will have to be unique across all ADLS accounts), then the name of a resource group that will contain it. That's it! Now you can check "Pin to dashboard" and click the blue Create button.
Deploying
If you checked "Pin to dashboard" then you should see a tile added to your dashboard indicating that your ADLS account is being deployed, as shown here.
Deployment complete
Deployment won't take long. Once complete, you'll see this "blade" in the Azure portal. Note the button along the top that opens a file explorer-like interface for ADLS. This will be useful once you have some data in there.
Analytics provisioning
With your Azure Data Lake Store account now set up, you can go back to the step we showed in slide 2 ("Pick Your Service") and choose Azure Data Lake Analytics (ADLA).
Once you do, you'll see this provisioning form. As before, you'll need to supply a name and resource group name, but you'll also need to click on the Data Lake Store option and pick the ADLS account that you just provisioned.
In other words, you'll do the analysis work with ADLA, and it will retrieve data from, and save data to, the ADLS account.
As before, check "Pin to dashboard" and click the blue Create button to provision an ADLA tenant.
Get ready to analyze
Once provisioning is complete, this is the screen you'll see. Note the ability to add additonal users (and provide them access to your) data. The "Sample Scripts" button on the top can get you querying sample data in almost no time flat. Click it to start.
So close yet so far
Now you'll see options to query a tab-separated values (TSV) file, create a database and table, populate a table and query a table. But you can't do any of that until you click through the two items above those options, which will load the sample data and the U-SQL extensions (more on U-SQL shortly) into your ADLA tenant. So click each option and let both processes complete.
Query a file directly
Now you can click the "Query a TSV file" option. Once you do, a full fledged U-SQL script will come up.
U-SQL is a dialect of the popular Structured Query Language that you can use with ADLA to query data in ADLS. This particular U-SQL script pulls data out of a TSV file using U-SQL's EXTRACT command, and it pushes the result of the query into another TSV file using the OUTPUT command.
Notice the U-SQL editor, even though it's embedded in the Azure portal, features color syntax highlighting. There's even better editor support in Visual Studio, which we'll see. But this isn't bad for the browser!
Clicking "Submit Job" (highlighted) at the top will execute the query. We'll explore that in a bit.
Create database and table
Some users may find the familiar concept of tables more comfortable than keeping everything in files.
So rather than working exclusively with text files for input and output, this U-SQL script creates an ADLA database, called SampleDBTutorials, and an empty table within it, called SearchLog, into which data can be inserted later.
Populate data
This U-SQL script queries data out of a TSV file with EXTRACT and then uses INSERT INTO to populate the SearchLog table with its contents.
Query the database
Now that the table is populated, this U-SQL script uses the standard SELECT command to query it. No more using EXTRACT and flat files! The result set gets persisted into a variable called @athletes.
Next, the OUTPUT command is used to export the @atheletes result set, and then the entire SearchLog table, to files.
3...2...run!
Now go back to the first script (Query a TSV file) and click Submit to run the job.
The job will go through a preparation phase, then a queuing phase, shown here. The work to be done in the job is represented by the tasks in the job graph, to the right. Bear in mind, these graphs can get much more complex than this one.
Running and Finalizing phases follow, after which the output of the job will exist as a file called SearchLog_output.tsv.
Preview the data
When the job is finished, click on the shape representing the SearchLog_output.tsv file (at the bottom of the job graph). This will let you preview its contents right in the Azure portal, as shown here.
Getting visual
As slick as it is to be able to do all that work in the browser, many pros will prefer to use a full fledged integrated development environment.
To that end, Microsoft has created Azure Data Lake Tools for Visual Studio, a free download. They also have a great sample Azure Data Lake project for Visual Studio that you can download from GitHub. (And if you don't have Visual Studio, the full-featured Community Edition is a free download too.)
Do all that, bring up the project, log in to your ADLA tenant, open up the first script and click its Submit button. The job will run right in Visual Studio, as shown here.
When job execution is complete, right click the job graph shape for the output file, and you'll see options to preview and download the data, and more.
Show me the files
If you choose the "Open Folder" option from the menu mentioned in the previous slide, you'll see a full-fledged ADLS file explorer comes up right inside Visual Studio, as shown here.
What's inside
Drill down to the /Output/TweetAnalysis folder, then open MyTwitterAnalysis1.tsv, the output file from the job.
The file will come up in the viewer shown here, which will display the file's metadata, several rows of its data in a tabular view, and provide options to save the data locally in CSV format or preview the data in Excel.
Run local
Visual Studio's U-SQL script editor has a drop-down at the top that lets you select "(Local)" as your ADLA tenant. Pick that and you can run jobs locally, without incurring any cloud usage fees.
Shown here is an execution of the same script as in slide 15 ("Getting visual"), but locally this time. Note that when execution is complete, you can hover over the job graph shape for the output file to see its location on your local disk.
Find it, open it
Go to AppData\Local\USQLDataRoot folder in your user folder to get to the local disk equivalent of the ADLS root folder in the cloud. Then drill down to the Output\TweetAnalysis sub-folder within it and you'll find the output file, as shown here. Double click the file to open it in the default editor for TSV files (Excel 2016 in the case of this screenshot).
Nothing but .NET
Doing Azure Data Lake work in Visual Studio is about more than using a desktop app. That's because U-SQL queries can call functions written in C#, either in code-behind files or in separate .NET assembly projects.
The source code for a C# function called get_mentions is shown here. Look at the Solution Explorer window at the upper-right and you'll see that the class file containing this code is in its own C# project, separate from the Azure Data Lake project, but in the same Visual Studio solution.
C# expressions can also be used inline, in U-SQL scripts. This includes scripts built in the Azure portal. The C# code-behind and assembly techniques require Visual Studio though.
Polyglot
This U-SQL script uses the get_mentions function in a SELECT query.
Note, at the top of the script, the REFERENCE ASSEMBLY command used to link to the .NET assembly created by compiling the C# project shown in the previous slide.
The CREATE ASSEMBLY command must be run once before REFERENCE ASSEMBLY can be used. The code for the former is also shown, though it is commented out.
Menu, sir?
Look carefully at Visual Studio's (admittedly crowded) main menu. If you're in an Azure Data Lake project, you'll see a "Data Lake" item, approximately 7th or 8th from the left. Click it and you'll see the options shown here.
You've got the Power (BI)
Did you know that Microsoft's Power BI can connect directly to data stored in ADLS? It's true, and shown here.
Let's get visual
You wouldn't connect to that data unless you wanted to visualize it, right? Shown here are several visualizations against the influencer.csv output file from the 8-TweetAnalysis-WindowingExpr.usql script in the Visual Studio sample project. This is the finish line!
---
You've now gone end-to-end with Azure Data Lake, from provisioning ADLS and ADLA, using the Azure portal U-SQL tooling, working with ADL Tools for Visual Studio, with both U-SQL and C# code and even integrating the data into Power BI.
This experience will all be very intuitive to .NET and SQL Server developers. And the fact that they're using Hadoop and YARN under the hood? It's just an implementation detail now.