Azure HDInsight gets its own Hadoop distro, as big data matures

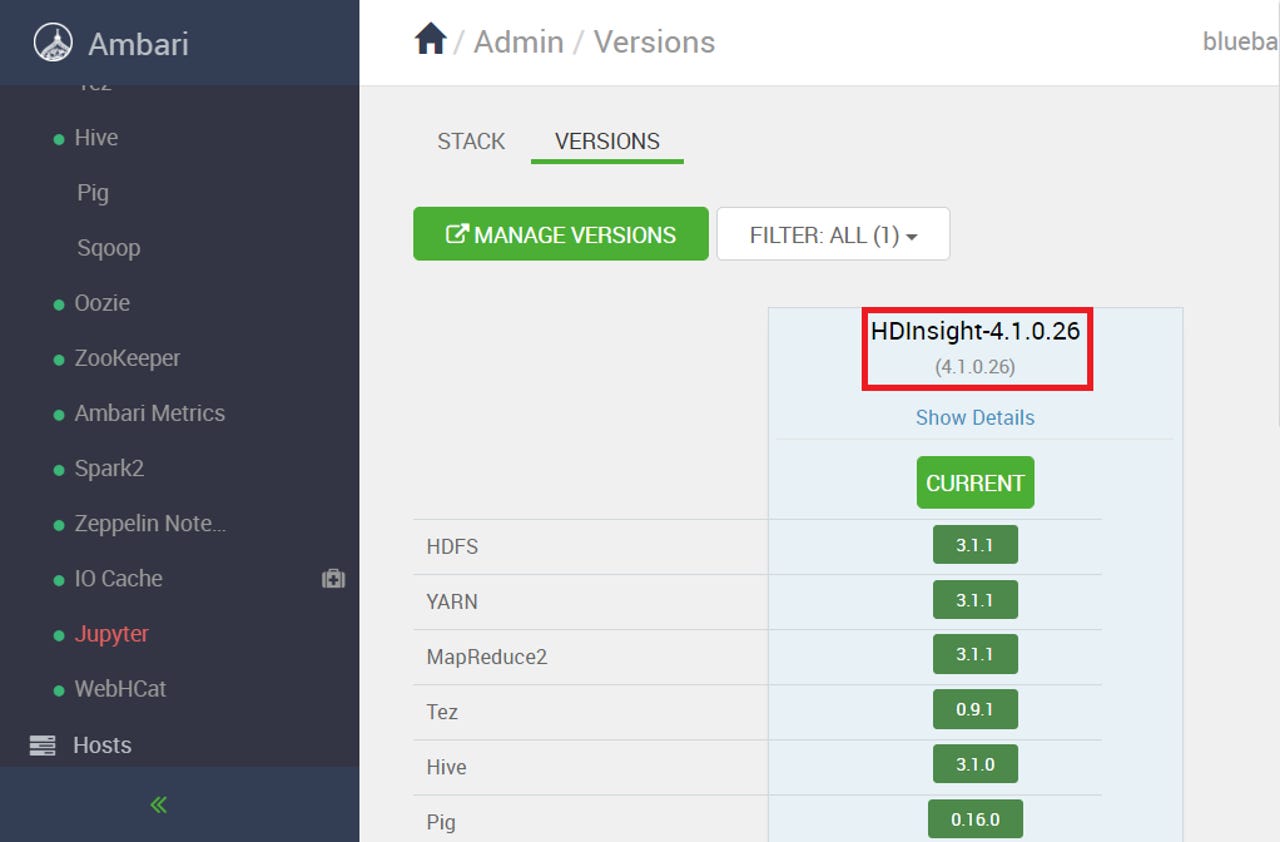
The Ambari Admin screen Versions tab, for an HDInsight cluster based on Microsoft's own Hadoop distribution.
Several years ago, big data was at the height of its hype cycle and Hadoop was its poster child technology. Today, open source analytics are solidly part of the enterprise software stack, the term "big data" seems antiquated, and it has become accepted folklore that Hadoop is, well…dead. That's just so much hyperbole, though; while Hadoop is no longer white hot, it is still a significant factor. That's because it defines an ecosystem of affiliated projects supporting database, data lake, streaming data and data engineering functionality. And that's why cloud services based on Hadoop, like Amazon's EMR and Google Cloud's Dataproc, are still critical and useful.
Microsoft's cloud Hadoop service, Azure HDInsight, is an especially good example of the utility of Hadoop, because the service persists, even as Microsoft has launched other offerings that compete with it. For example, Microsoft partnered with Databricks, the company founded by Apache Spark's creators, to offer and directly support a version of that company's eponymous service. Additionally, Microsoft evolved its Azure SQL Data Warehouse service into Azure Synapse Analytics, which now offers on-demand Spark pools to support full data lake functionality, as a public preview feature. But HDInsight, the Hadoop service Microsoft first launched in 2013, is still chugging along.
Must read:
- Databricks comes to Microsoft Azure
- Azure Synapse Analytics combines data warehouse, lake and pipelines
Dance with the elephant that brung ya?
HDInsight was co-developed with Hortonworks, a company that subsequently merged with Cloudera. After that merger, the new Cloudera rationalized and refactored the two companies' Hadoop distributions – Hortonworks Data Platform (HDP) and Cloudera Distribution including Apache Hadoop (CDH) into the runtime for the new Cloudera Data Platform (CDP). And while that's all well and good for Cloudera, the retirement of HDP created a challenge for Microsoft, as HDInsight has been based on HDP since its inception.
Also read:
- Cloudera and Hortonworks' merger closes; quo vadis Big Data?
- Cloudera Data Platform launches with multi/hybrid cloud savvy and mitigated Hadoop complexity
Many were wondering whether Microsoft would somehow adopt the CDP runtime, or if it would perhaps go its own way, and build its own Hadoop distro, as AWS and Google did from the get-go. The latter has now come to pass, as Microsoft has created its own Hadoop distribution, based on Apache open source components. The general availability of the new distribution was announced on July 21st during Inspire, Microsoft's virtual event for its partner ecosystem.
As it turns out, in order to maintain compatibility and minimize disruption, Microsoft took HDP 3.1.6, on which HDInsight 4.0 was based, and cloned it. Today, if you provision an HDInsight 4.0 cluster in various Azure regions (I've confirmed it for Canada East, US Central and US East), your cluster will use this new distro. You probably won't notice though. The HDI version number hasn't changed and neither have the underlying open source project versions. The only way you'd really know the change took place is the replacement of "HDP-3.1.6.2" with "HDInsight-4.1.0.26" in the "Versions" tab of Ambari's Admin screen, as shown in the figure at the top of this post. In all other respects, the experience will be identical.
Value prop
Why did Microsoft go to the trouble, you might ask? Keep in mind, even if there's overlap, that HDInsight can do things other Azure data services cannot. For example, Azure Databricks clusters do not mix and match components – they feature a combination of a proprietary version of Spark, Delta Lake, Delta Engine and MLflow. Synapse Spark pools are also Spark-exclusive, though they're based on the open source Spark bits. They're also serverless, with billing based on actual queries executed. For some customers that model is better; for others, not so much.
Also read: Databricks moves MLflow to Linux Foundation, introduces Delta Engine
So if you want a discrete big data cluster on Azure, billed by the hour, with open source Spark, as well as Hive, HBase, Pig and Hadoop (and, optionally, Kafka, Storm, Microsoft's Machine Learning Server and open source Spark as well), you're going to want to use HDInsight. And now, with Microsoft having made the investment to build, test and deploy its own Hadoop distribution, the service has a future that's much more solid and it can continue to service the workloads it's uniquely suited to.
Go big or go clone
Now that Microsoft controls HDInsight's underlying distribution, will it innovate and evolve it beyond the HDP clone that it is now? There's precedent for that, given Microsoft had already innovated on top of the HDP-based distro. Working with Hortonworks, Microsoft had built unique integrations with Azure Blob Storage and Azure Data Lake Storage, as well as Azure SQL Database. More recently, the addition of Machine Learning Server and .NET for Apache Spark introduced additional value-adds.
Also read: .NET for Apache Spark brings enterprise coders and big data pros to the same table
Perhaps Microsoft could next integrate Spark 3.0, Presto and AirFlow into HDInsight's mix of open source components. On the Microsoft technology side, support for one or two of the company's own notebook experiences, and perhaps tighter integration with Cosmos DB and Azure Machine Learning could come as well. These integrations would add value to HDInsight and the Azure services with which it became more tightly integrated.
Moves such as these would make Microsoft's commitment to HDInsight clear. Ultimately, that commitment has to be full-throated; for too long, it's been halfhearted. But for now, uncertainty has been eliminated, compatibility has been maintained and HDInsight is no longer dependent on a third party organization. That's a win for Microsoft's customers; it just might embolden them to want more.
Brust is a Microsoft Data Platform MVP and Cloudera is a customer of Brust's advisory firm, Blue Badge Insights.