Data Mesh: Should you try this at home?

Data Mesh
To centralize or distribute data management? That question has been on the front burner ever since departmental minicomputers invaded the enterprise, followed even more subversively by PCs and LANs walking through the back door. And conventional wisdom has swung back and forth ever since. Workgroup or departmental systems to make data accessible, then enterprise database consolidations to get rid of all the duplication.
Remember when the data lake was supposed to be the end state? Just like the enterprise data warehouse before it, the notion that all data could roll into one place so that there was only a single source of truth that all walks of life across the enterprise could access proved unrealistic. The connectedness of the Internet, the seemingly cheap storage and endless scalability of the cloud, the explosion of smart device and IoT data threaten to overwhelm the data warehouses and data lakes so laboriously set up. Data lakehouses have lately emerged to bring the best of both worlds, while data fabrics and intelligent data hubs optimize the tradeoffs between virtualizing and replicating data.
It would be pointless to state that any of these alternatives offer the definitive silver bullet.
Enter the Data Mesh
Over the past year, a new theory has emerged that recognizes the futility of top-down or monolithic approaches to data management: the data mesh. While much of the spotlight of late has been on AI and machine learning, in the data world, there are fewer topics that are drawing more discussion than data mesh. Just look at Google Trends data for the past 90 days: searches for Data Mesh far outnumber those for Data Lakehouse.
It was originated by Zhamak Dehghani, director of next tech incubation at Thoughtworks North America, through an extensive set of works beginning with an introduction back in 2019, a drill-down on principles, and logical architecture in late 2020, that will soon culminate in a book (if you're interested, Starburst Data is offering a sneak peek). Data meshes have often been compared to data fabrics, but a close read of Dehghani's work reveals that this is more about process than technology, as James Serra, an architecture lead at EY and formerly with Microsoft, correctly pointed out in a blog post. Nonetheless, the topic of data meshes (which are distributed views of the data estate) vs. data fabrics (which apply more centralized approaches) merits its own post, as interest in both has been pretty similar.
Simply stated, if that is possible, data mesh is not a technology stack or physical architecture. Data mesh is a process and architectural approach that delegates responsibility for specific data sets to domains, or areas of the business that have the requisite subject matter expertise to know what the data is supposed to represent and how it is to be used.
There is an architectural aspect to this: instead of assuming that data will reside in a data lake, each "domain" will be responsible for choosing how to host and serve the datasets that they own.
Aside from external regulation or corporate governance policy, the domains are the reason why specific data sets are collected. But the devil is in the details, and there are a lot of them.
So, the data mesh is not defined by the data warehouse, data lake, or data lakehouse where the data physically resides. Neither is it defined by the data federation, data integration, query engine, or cataloging tools that populate and annotate these data stores. Of course, that hasn't stopped technology vendors from data mesh washing their products. Over the next year, we're likely to see providers of catalogs, query engines, data pipelines, and governance paint their tools or platforms in a data mesh light. But as you see the marketing messages, remember that data meshes are about process and how you implement technology. For instance, a federated query engine is simply an enabler that can help a team with implementation, but on its own does not suddenly turn a data estate into a data mesh.
The core pillars
Data Mesh is a complex concept, but the best way to start is by understanding the principles behind it.
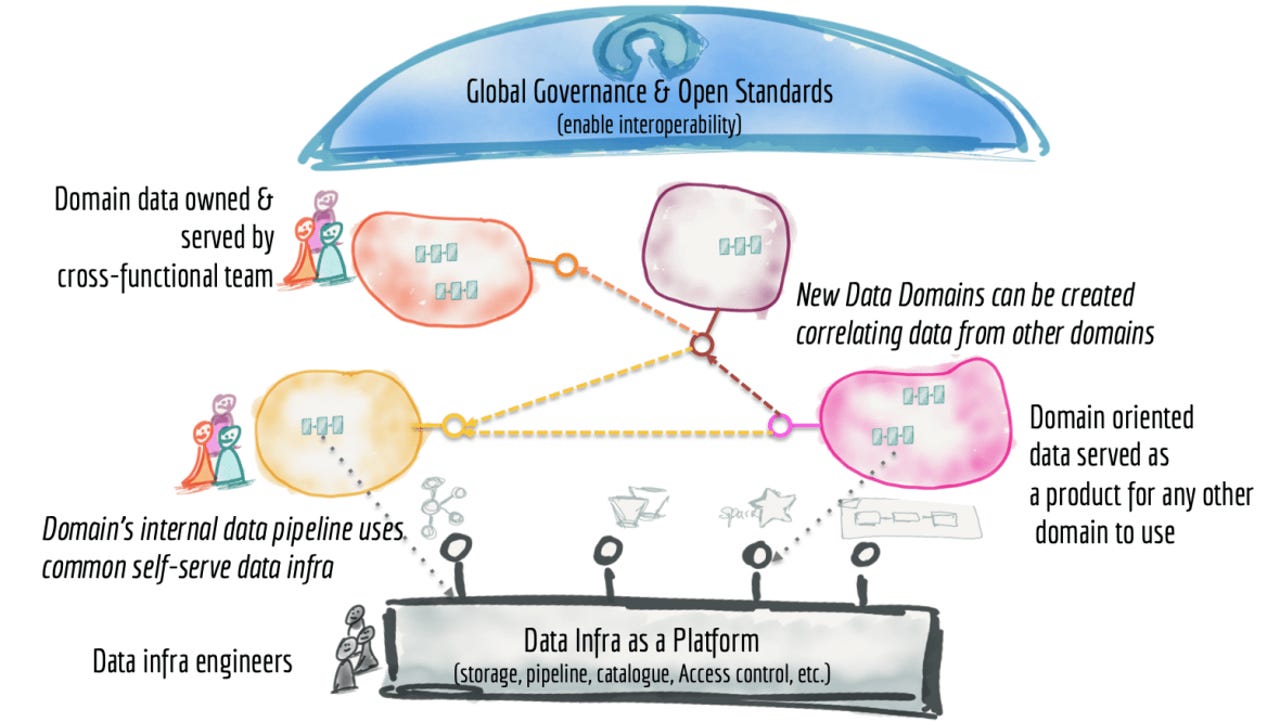
The first principle is about data ownership – it should be local, residing with the team responsible for collecting and/or consuming the data. If there is a central principle to data meshes, this is it – it's that the control of data should devolve to the domain that owns it. Think of a domain as an extension of domain knowledge – this is the organizational entity or group of people who understand what the data is and how it relates to the business. This is the entity that knows why the dataset is being collected; how it is consumed, and by whom; and, how it should be governed through its lifecycle.
Things get a bit more complicated for data that is shared across domains, or where data under one domain is dependent on data or APIs from other domains. Welcome to the real world, where data is rarely an island. This is one of the places where implementing meshes could get sticky.
The second principle is that data should be regarded as a product. That is, in effect, a more expansive view of what comprises a data entity, in that it is more than the piece of data or a specific data set and takes more of a lifecycle view of how data can and should be served and consumed. And part of the definition of the product is a formal service level objective, which could pertain to factors such as performance, trustworthiness and reliability, data quality, security-related authorization rules, and so on. It's a promise that the domain that owns the data makes to the organization.
Specifically, a data product goes beyond the data set or data entity to include the code for the data pipelines necessary to generate and/or transform the data; the associated metadata (which of course could encompass everything from schema definition to relevant business glossary terms, consumption models or forms such as relational tables, events, batch files, forms, graphs, etc.); and infrastructure (how and where the data is stored and processed). This has significant organizational ramifications, given that the building of data pipelines is often a disjoint activity handled independently by specialist practitioners such as data engineers and developers. At least in a matrix context, they need to be part of, or associated with, the domain or business team that owns the data.
On, and by the way, that data product needs to satisfy some key requirements. The data must be readily discoverable; this is presumably what catalogs are for. It should also be explorable, enabling users to drill down. And it should be addressable; here, Dehghani mentions that data should have unique canonical addresses, which sounds like a higher-level abstraction that semantic web remnant, the classic Uri. Finally, data should be understandable (Dehghani suggests "self-describing semantics and syntax"); trustworthy; and secure. Let's not forget that, since this is intended to cross multiple domains, that data harmonization efforts will be necessary.
While data mesh is not defined by technology, in the real world, specific engineering groups will own the underlying data platform, whether it be a database, data lake, and/or streaming engine. That applies regardless of whether the organization is implementing these platforms on-premises or taking advantage of a managed database service in the cloud, and more likely, in both places. Somebody needs to own the underlying platform, and these platforms will be considered products, too, in the grand scheme of things.
Self-service data platform
The third principle is the need for data to be available via a self-service data platform as shown above. Of course, self-service has become a watchword for broader data access as it is the only way for data to become consumable as the data estate expands, given that IT resources are finite, especially with data engineers who are rare and precious. What she is describing here should not be confused with self-service platforms for data visualization or data scientists; this one is more for infrastructure and product developers.
This platform can have, what Dehghani terms, different planes (or skins) that service different swaths of practitioners. Examples could include an infrastructure provisioning plane, that deals with all the ugly physical mechanics of marshaling data (like provisioning storage; setting access controls; and the query engine); a product development experience that provides a declarative interface to managing the data lifecycle; and a supervision plane that manages the data products. Dehghani gets a lot more exhaustive on what a self-serve data platform should support, and here is the list.
Finally, no approach to managing data is complete without governance. That's the fourth principle, and Dehghani terms it federated computational governance. This acknowledges the reality that in a distributed environment, there will be multiple, interdependent data products that must interoperate, and in so doing support data sovereignty mandates and the accompanying rules for data retention and access. There will be a need to fully understand and track data lineage.
A single post would not do this topic justice. At the risk of bastardizing the idea, this means that a federation of data products and data platform product owners create and enforce a global set of rules applying to all data products and interfaces. What's missing here is that there needs to be provision for top management when it comes to enterprisewide policies and mandates; Dehghani infers it (hopefully her book will get more specific). In essence, Dehghani is stating what is likely to be informal practice today, where a lot of ad hoc decision-making on governance is already being made at a local level.
Federated Computational Governance
So should you try this at home?
Few topics have drawn as much attention in the data world over the past year as the data mesh. One of the triggers is that, in an increasingly cloud-native world where applications and business logic are being decomposed into microservices, why not treat data the same way?
The answer is easier said than done. For instance, while monolithic systems can be rigid and unwieldy, distributed systems introduce their own complexities, welcome or not. There is the risk of creating new silos, not to mention chaos, when local empowerment is not adequately thought out.
For instance, developing data pipelines is supposed to be part of the definition of a data product, but when those pipelines can be reused elsewhere, provision must be made for data product teams to share their IP. Otherwise, there's lots of duplicated effort. Dehghani calls for teams to operate in a federated environment, but here the risk is treading on somebody else's turf.
Distributing the lifecycle management of data may be empowering, but in most organizations, there are likely to be plenty of instances where ownership of data is not clear-cut for scenarios where multiple stakeholder groups either share use or where data is derived from somebody else's data. Dehghani acknowledges this, noting that domains typically get data from multiple sources, and in turn, different domains may duplicate data (and transform them in different ways) for their own consumption.
Data meshes as concepts are works in progress. In her introductory post, Dehghani refers to a key approach for making data discoverable: through what she terms "self-describing semantics." But her description is brief, indicating that using "well-described syntax" accompanied by sample datasets, and specifications for schema are good starting points -- for the data engineer, not the business analyst. It's a point we'd like to see her flesh out in her forthcoming book.
Another key requirement, for federated "computational" governance, can be a mouthful to pronounce, but it will be even more of that to implement, as a look at the diagram above illustrates. Localizing decisions as close to the source while globalizing decisions regarding interoperability is going to require considerable trial and error.
All that said, there are good reasons why we're having this discussion. There are disconnects with data, and many of the issues are hardly new. Centralized architecture, such as an enterprise data warehouse, data lake, or data lakehouse, can't do justice in a polyglot world. On the other hand, arguments can be made for the data fabric approach that maintains that a more centralized approach to metadata management and data discovery will be more efficient. There is also a case to be made that a hybrid approach that harnesses the power of unified metadata management of the data fabric could be used as a logical backplane for domains to build and own their data products.
Another pain point is that the processes for handling data at each stage of its lifecycle are often disjoint, where data engineers or app developers building pipelines may be divorced from the line organizations that the data serves. Self-service has become popular with business analysts for visualization, and for data scientists in developing ML models and moving them into production. There is a good case to be made to broaden this to managing the data lifecycle to teams that, by all logic should own the data.
But let's not get ahead of ourselves. This is very ambitious stuff. When it comes to distributing the management and ownership of data assets, as mentioned earlier, the devil is in the details. And there are plenty of details that still need to be ironed out. We're not yet sold that such bottom-up approaches to owning data will scale across the entire enterprise data estate, and that maybe we should aim our sights more modestly: limit the mesh to parts of the organization with related or interdependent domains.
We're seeing several posts where customers are prematurely declaring victory. But as this post states, just because your organization has implemented a federated query layer or segment its data lakes does not render its deployment a data mesh. At this point, implementing a data mesh with all of its distributed governance should be treated as proof of concept.