Databricks' TPC-DS benchmarks fuel analytics platform wars

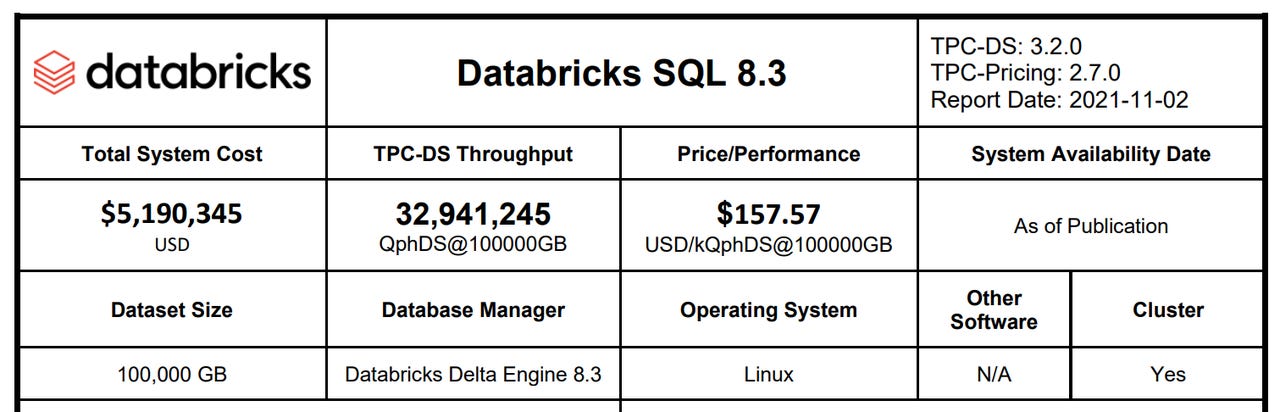
Databricks' TPC-DS benchmark results summary
As data sources and volumes grow, and as a data-driven orientation is increasingly deemed to be a competitive necessity, the war between platform vendors to provide the primary repository for our data is intense. The war has several fronts, one of which is analytics. And within that scope, the data warehouse and data lake camps are the main combatants.
The data warehouse side is strong, as it includes a combination of stalwart incumbent vendors like Teradata and Vertica (now part of Micro Focus), all three major cloud providers (AWS, Google Cloud, Microsoft Azure), and industry darling Snowflake. On the data lake side, independent providers, like Cloudera and Databricks, are perhaps the most emblematic competitors.
ZDNET Recommends
A few months ago, Databricks said it achieved record performance benchmark results that render it victorious in the battle, vanquishing the data warehouse model and the vendors who champion it. While this is no longer late-breaking news, some analysis of the announcement is still necessary.
Don't just tread water
While proponents of the data lake (and "lakehouse," as Databricks likes to call its own platform) may criticize the warehouse as outdated, the latter is time-tested and enjoys a certain dominance. That puts the burden of proof on the data lake side to show it can handle the same workloads as the warehouse with competitive performance.
Databricks now believes it has that proof. This past November, the company announced the results of a set of benchmarks audited by, and based on, standards from the Transaction Processing Performance Council (TPC). The tests were run against the relatively new -- and even more recently improved -- Databricks SQL platform, the company's foundation for the aforementioned lakehouse architecture. Specifically, the benchmark configuration used Databricks SQL 8.3, which includes Databricks' proprietary Photon engine, a vector-processing, query processor-optimized replacement for Spark SQL written in C++.
Databricks SQL specifically, and the lakehouse architecture generally, use data lake technology at the core, combined with enhancements -- like ACID compliance, writeback, and vector processing -- that help provide capability parity with data warehouse platforms. Databricks SQL still uses clusters of machines running the Spark-based Databricks Runtime, but it optimizes the nodes on those clusters for the kinds of queries and user demand patterns common in data warehouse and business intelligence (BI) use cases.
DS, FTW
Databricks used the TPC-DS stable of tests, long an industry standard for benchmarking data warehouse systems. The benchmarks were carried out on a very beefy 256-node, 2112-core Databricks SQL cluster, the cloud infrastructure for which is priced out at north of $5 million by Databricks. "DS," by the way, stands for "decision support," a precursor to the term business intelligence, which, given Databricks SQL's design and mission, is quite appropriate.
Databricks characterizes the benchmark results by saying it set a new world record for TPC-DS performance executed on any platform, be it warehouse, lake, or lakehouse.
The previous record holder for performance at the scale of Databricks' TPC-DS benchmark runs was Alibaba. The Chinese Internet and e-commerce giant had achieved a result of 14,861,137 QphDS @ 100TB (decision support queries per hour, based on queries involving a 100TB of data), using its own custom-built -- and also quite beefy -- data warehouse system.
Databricks, meanwhile, announced it achieved a result of 32,941,245 QphDS @ 100TB -- more than double Alibaba's performance. It did so on a system that, the company says, was 10% lower in cost than Alibaba's home brew platform. And while the benchmarks were conducted by Databricks itself, the results were audited by the TPC.
In Databricks' opinion, it set an all-time record.
The company further believes that any blockers that were preventing customers from using a lakehouse platform in place of a warehouse platform should now be cleared. That's significant because, even in its advocacy of the lakehouse approach, Databricks previously admitted that warehouse platforms performed better for certain workloads, and the company understood that this performance deficit prevented customers from coming over to the lakehouse side.
Confronting Snowflake
Databricks clearly felt these benchmark results made it successfully stand up to data warehouse darling Snowflake. Speaking of which, beyond the TPC benchmark results themselves, Databricks is touting work done by the Barcelona Supercomputing Center (BSC) comparing Databricks SQL and Snowflake. Databricks says that this work, which was based on TPC-DS benchmarks but not TPC-audited, shows Databricks SQL to be 2.7x faster (see the figure below from a Databricks blog post on the subject). BSC also reports that a Databricks SQL cluster is 12x better in terms of price performance than a similarly sized Snowflake setup.
Databricks SQL vs. Snowflake using a benchmark derived from TPC-DS.
There's plenty of spin here, but what the TPC and BSC results do show is that the lakehouse architecture can take these BI workloads on. This is significant because most Spark-based systems, including Databricks, had previously been best for data engineering, machine learning, and intermittent queries in the analytics realm. Getting such a system to service ongoing analytics workloads, or ad hoc analysis involving multiple queries that build on each other, was harder to come by.
If the question is whether this means the lakehouse is now a fully-enabled replacement for a warehouse, then the answer is unclear.
The chief reason for this lack of clarity has to do with customer opinion on why a lake or lakehouse was not an adequate substitute, before. Yes, for some, the reason to stick with a warehouse was performance, and this suite of TPC benchmarks may address those concerns and sway customers who espoused them.
A question of formality
Big Data
For other customers, the criteria are more about the paradigm -- including data modeling and, in a sense, data governance -- than it is about performance. The ethos of a lake is to store data in the form of named files in open formats, such that the data is compatible with, and can be used by, a range of database and analytics engines. And because the data is stored as files on disk or in cloud storage, the need (and the willingness) to model it is lessened.
This makes the data less formal, often less scrutinized, and also less vetted. Control is more delegated, making it easier to put data in. (These characteristics of a data lake apply to lakehouse scenarios, too.)
A data warehouse is more formal and controlled, typically enforcing a more explicit and comprehensive data model. It's less agile, which frustrates users, but it also has more of a filter, which can correlate with a generally higher degree of data quality and user trust.
Big benchmarks for big data
Databricks TPC-DS benchmarked configuration
A system with $5 million worth of infrastructure and massive data volumes may be able to take on Alibaba's benchmark showing, but it's not typical of what most customers need or can afford. It does show that Databricks SQL can take on huge workloads, and for some customers, that in itself will be important.
The significance of Databricks' benchmark results can be best understood through proper framing of the question. Databricks would frame it in terms of: "Which model reigns supreme?" But maybe the question is: "Which model appeals more to particular customers, in particular use cases?" Followed by: "Is performance now sufficient with both models?"
Ultimately, most enterprises can probably benefit from a data warehouse and a data lake(house). The warehouse can be a repository for highly-vetted, carefully conformed and modeled data to drive reporting, operational dashboards, and ad hoc queries in the realm of "known unknowns." Lakes and lakehouses, meanwhile, can accommodate more data, with a shorter on-boarding process, with less "modeling-on-write," and be used for exploratory analytics and impromptu visualizations.
The win, not the winner
The TPC results make it clear that both models work well, deliver excellent results, can interface when needed, and work with the same BI tools. They are also cost effective, cloud-first, elastic, and agile. But even though the warehouse/lakehouse question needn't require an either/or choice, there's an upside to vendors seeing it that way: Competition for the same customers and the same workloads results in continued innovation that benefits the customer.
Whether TPC benchmarks are the ultimate arbiter of what's best will depend on the buyer's criteria. But Databricks' TPC-DS results are impressive, regardless. They're a milestone for the industry and a forcing function to make certain that vendors adopt an approach of continuous improvement, whether they tout the lake, the lakehouse, or the warehouse.