How Facebook is speeding up the Presto SQL query engine

Created by the social-media giant for its huge data warehouse and open-sourced in November 2013, Presto is a SQL engine designed for low-latency interactive analysis of data sources of all sizes.
It was built to be faster than Hadoop data query framework Hive and fulfils a similar role to, for example, Cloudera's Impala and Pivotal's HAWQ.
In a blogpost published today, Facebook software engineer and creator of Presto Dain Sundstrom sets out the elements identified as key to improving the performance of Presto, publishing test figures showing the resulting impact on the engine's speed.
The areas that have received attention are columnar reads, predicate pushdown, lazy reads and the ORC reader - the ORC, or Optimized Row Columnar, file format is designed to provide an efficient way to store Hive data.
"The decision to write a new ORC reader for Presto was not an easy one. We spent a lot of time working with the Hive 13 vectorised reader and saw very good performance, but the code was not very mature. The vectorised reader did not support structs, maps, or lists, and neither the row-oriented nor the column-oriented readers supported lazy reads," Sundstrom said.
See also
"Additionally, at Facebook we use a fork of ORC named DWRF. The DWRF reader didn't support columnar reads or predicate pushdown, but it did support lazy reads. To get to the speed we were looking for, we needed all three features, and by writing a new reader, we were able to create interfaces that work seamlessly with Presto."
He said the new Presto ORC reader delivers significant improvements over its old Hive-based predecessor and the RCFile-binary reader.
"On top of that, we've seen massive speedups with the new lazy reads and predicate pushdown features. With the reader fully integrated into Presto, we saw a number of improvements with terabyte-scale ZLIB compressed tables," Sundstrom said.
These improvements include a jump of between two and four times in wall-clock and CPU time over the old Hive-based ORC reader, with identical figures over the RCFile reader.
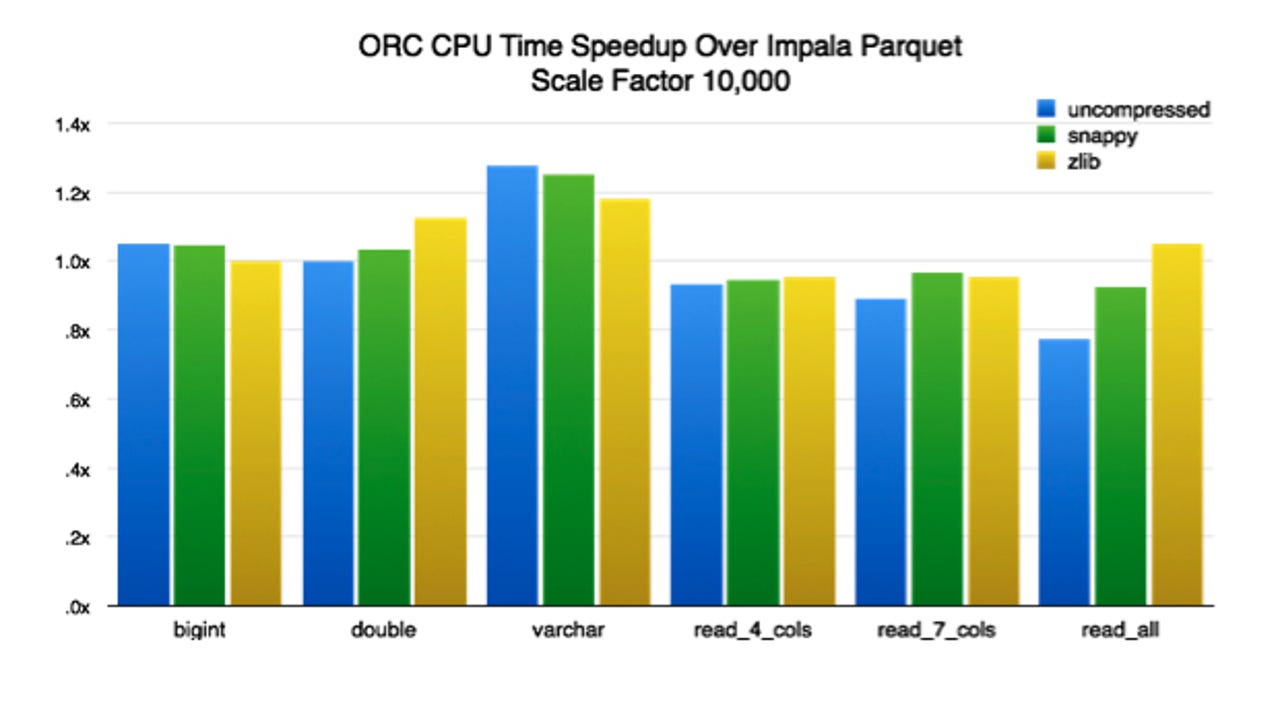
He also lists a 1.3 to 5.8 times wall-clock time speedup - and comparable CPU boost - over Impala Parquet, a four times improvement when lazy reads are used, and a 30-plus times boost when predicate pushdown is used.
"Will you see this speedup in your queries? As any good engineer will tell you, it depends. The queries in this test are carefully crafted to stress the reader as much as possible. A query bounded by client bandwidth - for example, SELECT * FROM table - or a computation-bound query - lots of regular expressions or JSON extraction - will see little to no speedup," Sundstrom said.
"What the new code does is open up a lot of CPU headroom for the main computation of the query, which generally results in quicker queries or more concurrency in your warehouse."
More on Hadoop and big data
- Couchbase ties into Hortonworks Hadoop for single analytics and transaction datastore
- Databricks CEO: Why so many firms are fired up over Apache Spark
- MySQL: Percona plugs in TokuDB storage engine for big datasets
- Cloudera links up with Hadoop developer Cask
- Mesosphere and MapR link up over Myriad to create one big data platform to rule them all
- Teradata rolls out big data apps, updates Loom
- MapR CEO talks Hadoop, IPO possibilities for 2015
- Teradata acquires archival app maker RainStor
- Hortonworks expands certification program, looks to accelerate enterprise Hadoop adoption
- Actian adds SPARQL City's graph analytics engine to its arsenal
- Splice Machine's SQL on Hadoop database goes on general release