Is Databricks vying for a full analytics stack?

Spark Summit East took place in New York last week. And while I'm a New Yorker, I'm not impervious to the cold, so I was escaping the frigid temperatures with my kids in Bermuda. That didn't stop me from reading my press releases though.
Two interesting ones came out of Databricks last Wednesday, covering announcements made at the event. One discussed a new "Community Edition" of the company's cloud service. Another announced the addition of a new dashboard feature. On their own, these new offerings seem rather tactical. Taken together, though, and with the benefit of nine days of pondering, I've decided this is a pretty big deal.
To understand why, let's take inventory of what was actually announced and then try to understand it in terms of what Apache Spark offers natively and what else the Databricks cloud service offers.
Supporting the community
Lots of open source-based products offer free community editions. And, since Spark is already open source, it's also already free to the community. What's not free, however, is the hardware needed to run it (even if in a simple development environment) or, in the case of a cloud service like Databricks', a cloud tenant for getting hands-on with it.
Databricks is attempting to close this gap by offering just such a free tenant. Sure, the infrastructure underlying it is what Databricks calls a "micro-cluster" and the company also calls out an explicit up-sell scenario to the paid tier. But the free environment sounds more than sufficient for getting hands-on with Spark and Databricks, and such a free tier is a necessary part of removing friction from adoption.
The Community Edition will be launched as an invite-only beta, to which attendees of Spark Summit East will be the first to get access. Others interested in participating in the beta can sign up for the wait list. That's all well and good. But when Databricks Community Edition hits General Availability (GA) is when things will get interesting. Potentially, lots of curious developers and data power users could get hands-on almost immediately.
Eye on the dash
The other announcement involved the addition of a dashboarding feature to the Databricks platform. Here too, the significance is larger than the announcement at first seems. In fact, one might wonder why Databricks didn't have a dashboarding feature already. And now that it does, it may seem that it's merely caught up with any number of self-service cloud BI products.
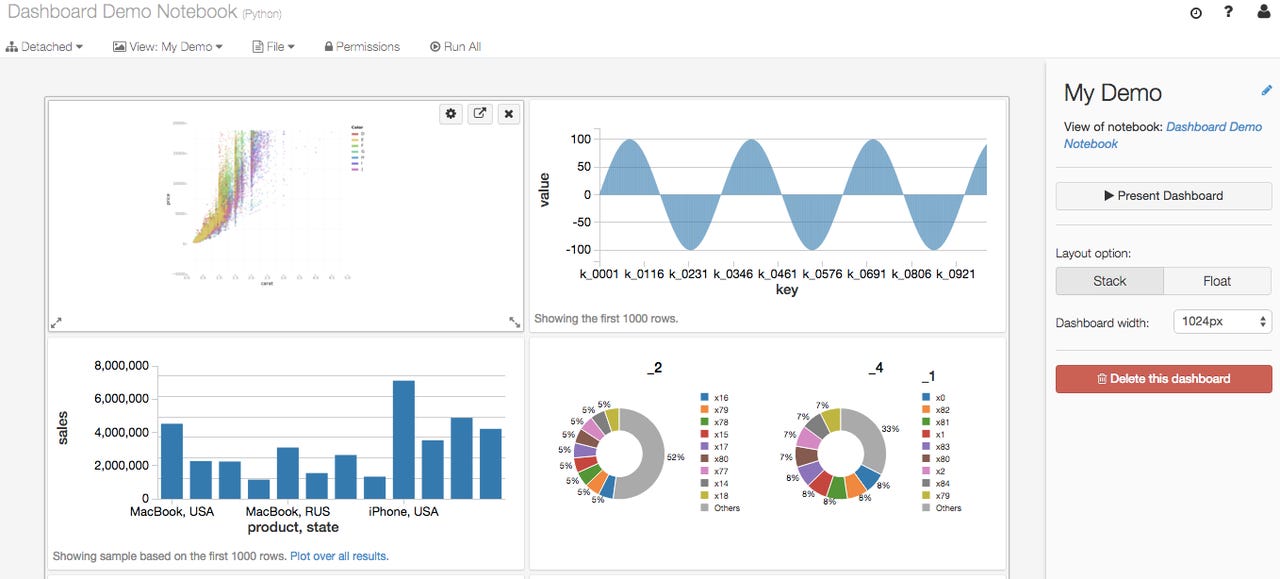
But that's the thing: Databricks isn't (or at least has not been) a self-service product at all. It's been a developer's product, providing command line access to the raw Apache Spark components as well as a "notebook" interface that is all the rage with developers, but kind of uninteresting to everyone else.
But what Databricks has now done is taken the notebook interface and added a graphical view to it, in the form of the new dashboard facility. Plus, the dashboards can be set up with a self-service UI for selecting parameter values and the like, and can be shared with non-developers via URL. Those non-developers can then have secured access (something else Databricks adds to raw Spark) and can start doing some data discovery work, even if it's limited.
Featured
All together now
When you think about Spark, which includes the core engine, as well as built-in components for SQL query access, streaming data, graph processing and machine learning, you have an all-around developer platform for data. Layer on the Databricks cloud, and the need to muck around with the hardware infrastructure goes away. Add in dashboards that are shareable with non-developers, and you've got fledgling business user functionality.
Put all that in a low-end free tier, and you've got a service that can start to compete with the likes of Microsoft Power BI and other cloud BI offerings, that end users are free to experiment with. Granted, they won't get far with a developer to help them...but now the analyst can promote Spark to her developers, in addition to the reverse.
I've signed up for the Databricks Community Edition Beta. I'm eager to get my hands on it. The dashboard feature will need to be more than simple charting if Databricks wants to offer an all-in cloud analytics platform. Will it be more than that? Does Databricks want it to be?
I'll have the chance to find out, when I chat with Databricks Co-Founder and Executive Chairman, Ion Stoica (as well as Neha Narkhede, Co-Founder and Head of Engineering at Confluent -- the company behind Apache Kafka) on stage at the Structure Data conference in San Francisco on March 10th.