Is Google’s Snorkel DryBell the future of enterprise data management?

There's always been a rich market for software tools that clean up enterprise data and integrate it to make it more useful. With the mantra that "data is the new oil," there is more than ever a very good sales pitch to be made by vendors large and small, from Oracle to Talend.
But what if nothing needed to be cleaned up, per se? What if, instead, the most valuable parts of the data could be transferred, in a sense, into machine learning models, without altering the data itself?
That notion is implied by a new technology introduced Thursday by Google's AI team, in conjunction with Brown University and Stanford University.
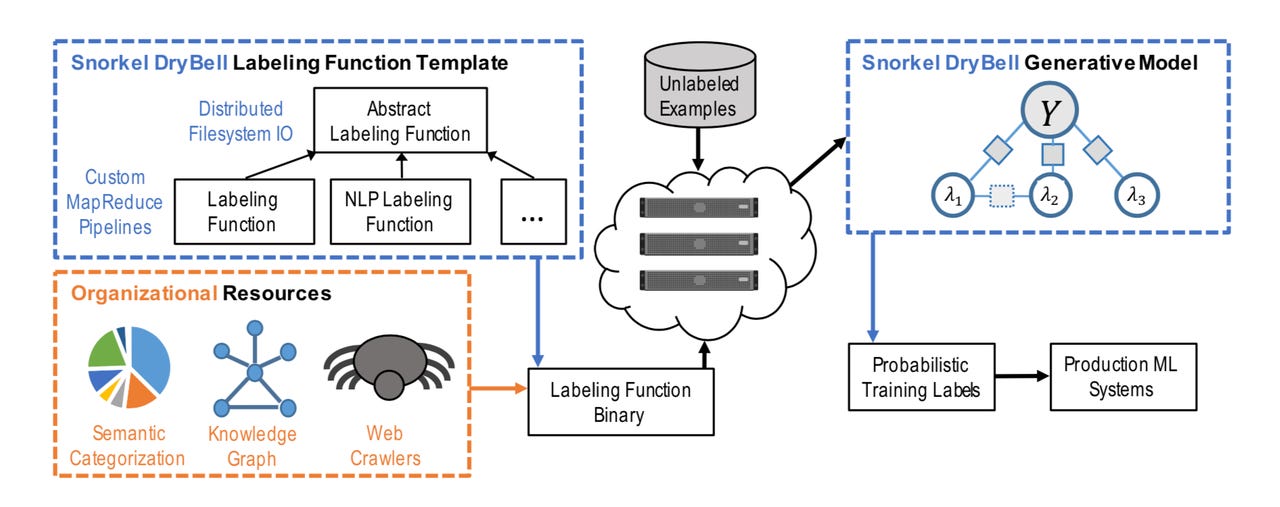
The code, which goes by the somewhat ungainly name "Snorkel DryBell," builds on top of the existing Snorkel software, an open-source project, which was developed at Stanford. Snorkel lets one automatically assign labels to data, a kind of taxonomy of what's in the data, from content repositories to real-time signals coming into the data center.
Also: Google's distributed computing for dummies trains ResNet-50 in under half an hour
The work points out that there is that a lot of data that can't be used outside the firewall but that can nevertheless be leveraged to train deep learning. This is known as "non-serveable" data, "like monthly aggregate statistics" or "expensive internal models," according to Google. All that should be able to be leveraged to make machine learning better, they argue.
The question raised, implicitly, is whether any data needs to be cleaned up at all. Instead, it can simply be made part of the pipeline of building machine learning without modification. All that's needed is to industrialize that basic Snorkel function, so that it can handle more diverse data sources, and at a greater scale that suits enterprise settings.
A blog post by Alex Ratner, a PhD student in the computer science department at Stanford University, and Cassandra Xia, with Google AI, explains the work. There is also an accompanying paper, "Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale," of which Stephen Bach is the lead author, posted on the arXiv pre-print server.
The Snorkel approach is easy enough to understand. In a traditional supervised learning version of machine learning, data that is fed to a machine learning system has to be labeled by subject-matter experts. The human-crafted labels are how the machine learns to classify the data. That's time-consuming for humans.
Also: MIT lets AI "synthesize" computer programs to aid data scientists
Snorkel instead lets a team of subject matter experts write functions that assign labels to the data automatically. A generative neural network then compares which labels multiple functions generate for the same data, a kind of vote tallying that results in probabilities being assigned as to which labels may be true. That data and its probabilistic labels are then used to train a logistic regression model, instead of using hand-labeled data. The approach is known as "weak supervision" in contrast to traditional supervised machine learning.
The Google-Stanford-Brown team make adjustments to Snorkel to process the data at greater scale. In other words, Snorkel DryBell is the industrialization of Snorkel.
For one, they changed the optimization function used in the generative neural network of DryBell from that used in Snorkel. The result is a rate of computing labels that is double the speed of what Snorkel conventionally delivers, they write.
While Snorkel is meant to be run on a single computing node, the team integrated DryBell with the MapReduce distributed computation method. That allows DryBell to be run across numerous computers in a "loosely coupled" fashion.
Also: Can IBM possibly tame AI for enterprises?
With that industrialization, the team is able to supply much more weakly labeled data to the deep learning system, and the results, they write, showed the weak supervision beat conventional supervised learning using hand-crafted labels — up to a point.
For example, in one test task, "topic classification," where the computer has to "detect a topic of interest" in enterprise content, they "weakly supervised" the logistic regression model on "684,000 unlabeled data points."
"We find," they write, "that it takes roughly 80,000 hand-labeled examples to match the predictive accuracy of the weakly supervised classifier."
Crucial in all this is the non-serveable data, the messy, noisy stuff that nevertheless is of great value inside an organization. When they did an "ablation" study, where they removed the pieces of training data that are non-serveable, results weren't as good.
The result of including non-serveable data is a kind of "transfer learning." Transfer learning is a common machine learning approach where the machine is trained on one bunch of data, and is then able to generalize its discrimination to similar data from a different source.
As the authors write, "this approach can be viewed as a new type of transfer learning, where instead of transferring a model between different datasets, we're transferring domain knowledge between different feature sets."
Transferring in this fashion has the benefit of taking data that's trapped in the enterprise and giving it newfound utility. That, they write, is "one of the major practical advantages of a weak supervision approach like the one implemented in Snorkel DryBell."
Must read
- 'AI is very, very stupid,' says Google's AI leader (CNET)
- How to get all of Google Assistant's new voices right now (CNET)
- Unified Google AI division a clear signal of AI's future (TechRepublic)
- Top 5: Things to know about AI (TechRepublic)
Imagine, then, the new enterprise data management task: write some labeling functions in C++, based on a best guess by domain experts, and use the output of those labeling functions to train a neural network, and move on. No more spending eons cleaning up or regularizing data, no more buying specialized tools required to do that.
"We find that the labeling function abstraction is user friendly, in the sense that developers in the organization can write new labeling functions to capture domain knowledge," they write.
Moreover, the generative model that tallies up the labels becomes a kind of arbiter of the quality of enterprise data, in the process, something they describe as "critical."
"Determining the quality or utility of each source, and tuning their combinations accordingly, would have itself been an onerous engineering task," they observe.
"Using Snorkel DryBell, these weak supervision signals could simply all be integrated as labeling functions, and the resulting estimated accuracies were found to be independently useful for identifying previously unknown low-quality sources (which were then later confirmed as such, and either fixed or removed)."
The only thing missing from the current work is evidence it can work with deep learning neural network models. Weakly supervising a simple logistic regression model is one thing. Training very deep convolutional or recurrent networks would be an interesting next challenge for such a system. (Note that Stanford's Ratner pointed out in a tweet, subsequent to this posting, that Snorkel itself does work with deep neural networks. Further empirical studies will show how well Snorkel DryBell generalizes to deep networks.)
Do you think Snorkel and Snorkel DryBell can find a place in enterprise data management? Let me know what you think in the comments section.
Best of MWC 2019: Cool tech you can buy or pre-order this year
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.