MapR-DB adds native JSON support to cut Hadoop data shuffling

Out today, a free MapR-DB developer preview shows how the NoSQL database can now handle JSON documents natively, in a move designed to simplify and speed up big-data app development.
The addition of JSON support to the proprietary HBase-compatible wide-column database will also mean less shuffling of data in and out of Hadoop. The new feature offers fast access to documents for analytics, according to Hadoop distribution firm MapR.
"Because we can store and manipulate JSON documents natively in the database using our new JSON API, that makes development very easy and quick," MapR technical evangelist Tugdual Grall said.
"So the time to market to add new features is a lot better. But the other part that's key is that it's integrated with a Hadoop platform. If you want to do some complex processing of the data, some machine learning, you don't have to move the data anymore. You just use the same format schema and you don't have anything thing to move or deploy."
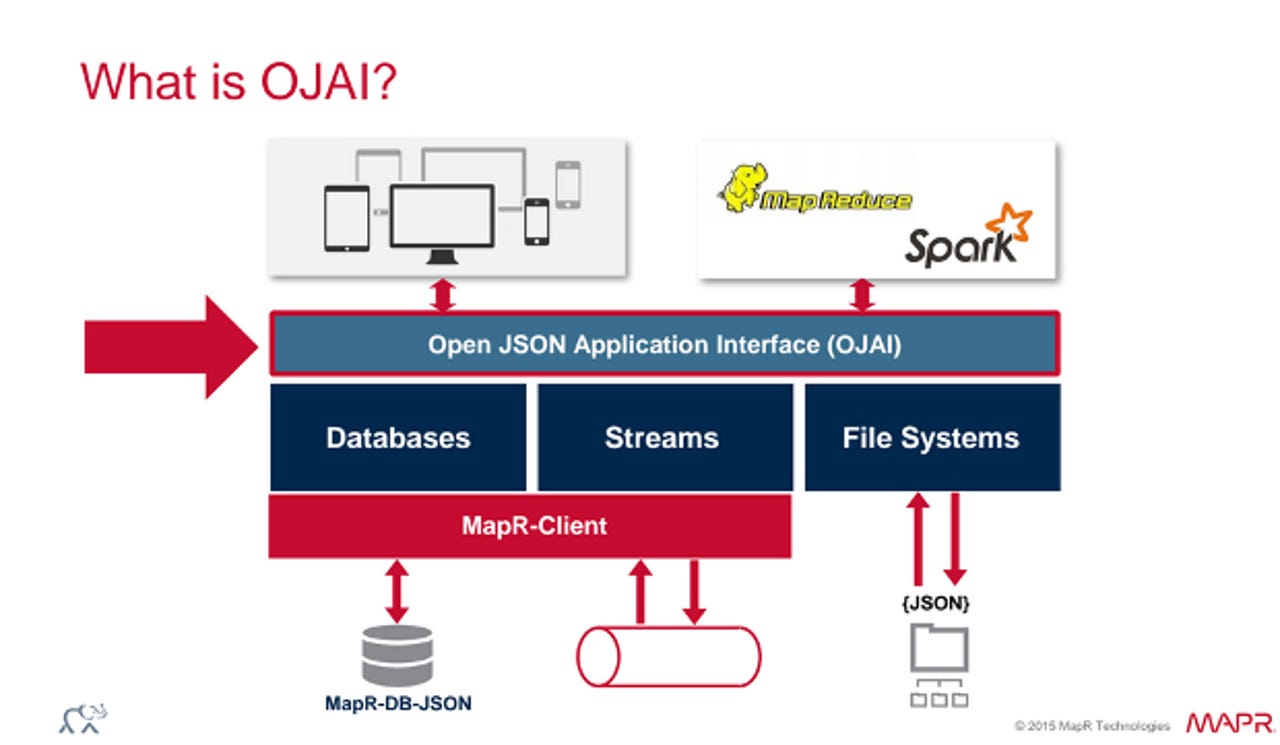
MapR-DB, which is designed to add operational analytics to Hadoop, comes with the Open JSON Application Interface, or OJAI, described as a general-purpose JSON access layer that sits on databases, file systems, and message streams.
JSON-supporting MapR-DB is available free as part of MapR's community edition, which allows production use, with general availability expected at the end of the quarter. MapR also sells an enterprise database edition offering additional features such as high availability, disaster recovery and replication.
Before the addition of JSON support, users could employ another tool or NoSQL database to tackle the issue of manipulating documents.
"But if you want to integrate that into your machine learning - to do some fraud detection or some recommendations - you'll have to move this data from your operational database into your big-data platform and do the work - and you'll have to update that on a regular basis," Grall said.
"The other option is to use the MapR-DB binary content, or HBase. But it's a very complex API for developers. So JSON support simplifies the management of the data and development."
Grall said the use of JSON documents or log files based on JSON is increasing significantly, potentially resulting in considerable movement of data between systems.
"The reason it's important to have an operational database inside the distribution is because you'll be able to query the data directly in the database and join it in some specific analytics task with other data that you have in your cluster," he said.
"Once again, you don't have to move anything. We're working actively on integration with our SQL engine, Apache Drill, to make it very easy for the analyst to plug that into their tools. We've been integrating Apache Drill to give discovery and other analytical features to analysts with any tool compliant with SQL."
The developer preview includes sample code, documentation and demo, and Java, Python and Node.js language bindings.
The inclusion of multi-master features in MapR-DB 5.0, launched in June, and the database's global deployment features also have some benefits in the context of native JSON support.
"If you're working in retail or in healthcare and you have many datacenters all over the world or in different states, you might want to be able to aggregate the data in a datacenter. So, for example, you have shops in all the states and you want to do analytics and transformation. You don't have to do anything," Grall said.
"You just enable replication of your JSON tables from your shops in different states into the centralised HQ. The power of the replication lets you select the specific columns you want and the ones you don't want to push to the central datacenter, just with a few lines of configuration. That's really helpful for aggregating data."
More on Hadoop
- Hortonworks' Murthy: Hadoop's next mission is to be more business friendly
- Three Big Data themes at Strata/Hadoop World NY
- Google opens beta on managed service for Hadoop and Spark
- Hadoop's growing enterprise presence demonstrated by three innovative use cases
- Cloudera wants Spark and Hadoop to be one platform, that works
- SAP Introduces Spark-based HANA Vora
- Intel invests in BlueData, forges big data partnership
- Hortonworks introduces DataFlow, acquires Apache NiFi-backer Onyara