Microsoft improves Translator and Azure AI services with new AI 'Z-code' models

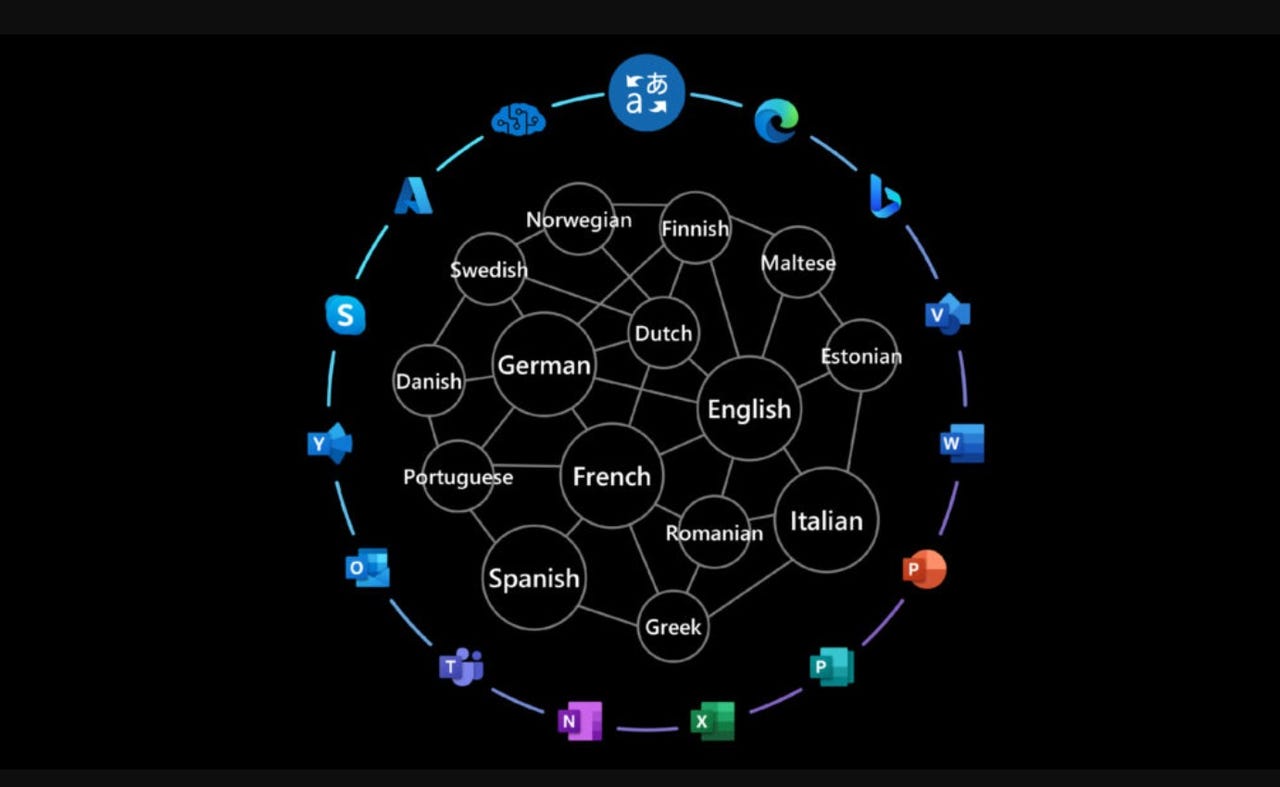
Microsoft is updating its Translator and other Azure AI services with a set of AI models called Z-code, officials announced on March 22. These updates will improve the quality of machine translations, as well as help these services support more than just the most common languages that have less available training data.
The new Z-code models use a sparse "Mixture of Experts" approach, which Microsoft execs described as being more efficient to run because it only needs to engage a portion of the model to complete a task. The result, according to Microsoft: Massive scale in the number of model parameters while keeping the amount of compute constant.
Microsoft recently deployed Z-code models to improve common language-understanding tasks like name entity recognition, text summarization, custom text classification and key phrase extraction across its various Azure AI services. But today's development marks "the first time a company has publicly demonstrated that it can use this new class of Mixture of Experts models to power machine translation products."
Z-code is part of Microsoft's larger XYZ-code project which seeks to combine models for text, vision, audio and multiple languages to create more powerful and integrated AI systems that can better speak, hear, see and understand. The Z-code models fall under the Microsoft AI at Scale and Turing initiatives which are seeking to develop large models that are pretrained using large amounts of textual data and which can be integrated directly into Microsoft and customer-developed products.
Officials said in order to get these models into production, Microsoft is using NVIDIA GPUs and its Triton Inference Server to deploy and scale them efficiently.
Speaking of NVIDIA, Microsoft announced today that it is working with NVIDIA to bring its confidential computing capability to NVIDIA GPUs.
Azure Chief Technology Officer and Technical Fellow Mark Russinovich explained the significance in a March 22 blog post:
"With confidential GPUs, data is encrypted when it is transferred between the CPU and GPU over the PCIe bus with keys that are securely exchanged between NVIDIA's device driver and the GPU. The only place where data is decrypted is within a hardware-protected, isolated environment within the GPU package where it can be processed to generate models or inference results. Much like other Azure confidential computing solutions, confidential GPUs support cryptographic attestation based on a unique GPU identity provisioned by NVIDIA during manufacturing. Using remote attestation, organizations can independently verify that their data is only processed within genuine and correctly configured confidential GPUs."