Strata Data 2019: Vendors focus on implementation success

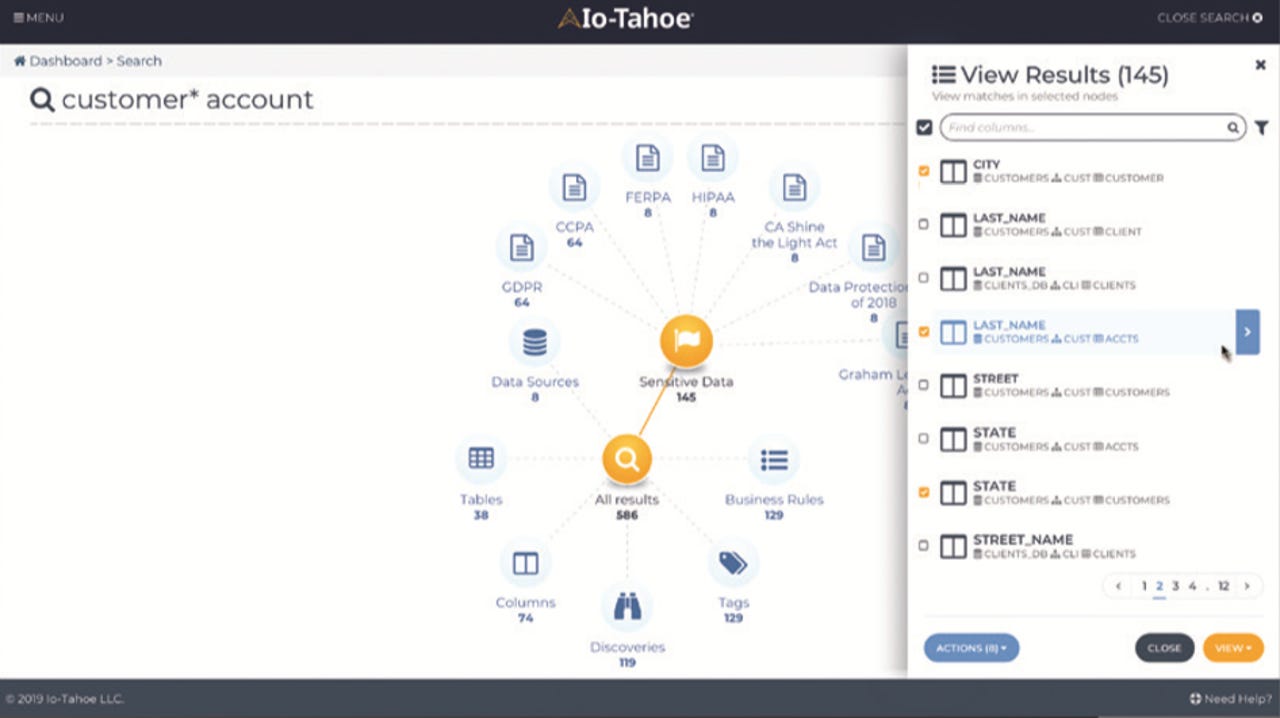
Io-Tahoe's Enterprise Search and its "galaxy view" results visualization
This year at Strata Data conference in New York, the news cycle wasn't lauding new companies, frameworks or paradigms. Beyond Cloudera's major announcement before the show started, it wasn't about Hadoop or Spark. Nor was it about Kafka or TensorFlow or Snowflake or Databricks or even, really, Cloudera. This year's news cycle was about taking what we've got and making it work better. This year's slate of announcements wasn't about rolling out new technologies for proofs of concept. Instead, it was about fully implementing existing technologies, in the Enterprise, successfully.
In this post I cover some ten announcements. Some are focused on database technology and several more come from the realm of data management. The remaining one concerns an authoritative source of comprehensive data, critical to financial industry. None of these goes for the pizzazz, or the fabulous; all of them support customers striving for success.
Of NICs and column stores
On the database side, three vendors had announcements, all of them focused, at least in part, on performance. In-memory database purveyor Aerospike had perhaps the most hardcore technical news, announcing that the new release of its database is the first to be compatible with Intel's new 800 Series network interface cards (NICs) and, specifically, their Application Device Queues (ADQ) feature that can prioritize network traffic for specific applications. To Aerospike, its product now addresses both server infrastructure performance bottlenecks: disk (addressed through the use of memory) and network (through compatibility with Intel's new Ethernet cards).
In other database news, MemSQL announced both the release of its Helios managed database as a service platform (which, as you might expect, is cloud-based and elastic) and the beta release of version 7 of the product. The latter includes a new feature that MemSQL calls "SingleStore," which is meant to mitigate the trade-offs between row store tables -- typically used for operational workloads -- and their column store cousins, typically used for analytics.
In fact "SingleStore" is a bit of a misnomer, because MemSQL 7 continues to offer both table types, but the company has enhanced each one with properties of the other. MemSQL 7 row store tables enjoy in-memory null compression -- allowing them to be much more memory-efficient -- and its column store tables are now seek-able, a property enabled by the use of multiple secondary indexes, and allowing them to be more ably used for operational workloads. Regarding my misnomer critique, MemSQL says this iteration of SingleStore technology is merely a down payment on what it envisions for the future, including a hybrid table type that more literally merges row and column store structures, by having single tables contain segments for each
From couch to container
The final database item comes from IBM, which, as you probably know, is the parent of RedHat, purveyors of the popular OpenShift on-premises Kubernetes (K8s)-based container computing platform. IBM's announcement is around the release of a K8s Operator (which you could think of as something like a driver/connector/adapter) for the open source Apache CouchDB NoSQL document store database.
To me, IBM's is one of the more curious announcements. I like CouchDB -- it was in fact the first NoSQL database I worked with and I found it not just easy, but addictively enjoyable to use. That said, its adoption compared to say, MongoDB, Cassandra, HBase or the cloud providers' proprietary NoSQL platforms (e.g. Amazon's DynamoDB and Microsoft's Cosmos DB), has seemed challenged. But as a pure open source document store and, again, one very appealing in its ease of use and JavaScript programmability, IBM/RedHat may feel that when paired with K8s/OpenShift, CouchDB's couch potato adoption days may be over. Perhaps that's why it's also offering advanced support services for the database.
Cloud integration
From databases, let's move on to data management, starting with integration and data pipelines. To begin with, SAP announced the release of its Data Intelligence cloud service that integrates its Data Hub integration and Leonardo Machine Learning platforms, in one. It also announced a new release of its overall SAP Analytics Cloud, which includes not only the Data Intelligence piece, but Augmented Analytics and a new Analytics Designer as well. The latter includes a ready-to-run service for queries within SAP Business Warehouse (SAP BW).
Also read: SAP unveils its Data Hub
Also read: SAP ups the ante for its Analytics Cloud and Cloud Platform
In other integration/pipeline news, Infoworks announced availability its automated cube, modeling, pipeline and orchestration platform on Microsoft's Azure cloud (via its marketplace) and compatibility with Azure Databricks, that cloud's version of Databricks' managed platform, based on Apache Spark. It's not all about Redmond, though, as Infoworks has forged an explicit partnership with Databricks itself and is now available on Google Cloud Platform (GCP) in addition to Azure (and Amazon Web Services -- AWS -- before that).
Beyond cloud availability and vendor partnerships, Infoworks has announced version 3.0 of its core DataFoundry platform. The new version, in addition to running on Cloudera's CDH and HDP Hadoop distributions on-prem, and AWS Elastic MapReduce, Azure HDInsight and Google Cloud Dataproc in the cloud, now includes an expanded data catalog that the company says provides tagging, search, change management, and full lineage.
In search of compliance
Speaking of catalogs, data governance vendors Collibra, Io-Tahoe and Immuta announced new features in theirs. Collibra has added a new machine learning-powered data classification feature that automates ingestion and tagging of the data. Io-Tahoe, whose Smart Data Discovery platform has always focused on ML-based automated discovery of sensitive data, data relationships, data flows and data redundancy, has added new capabilities around search and de-duping. The latter uses clustering and reinforcement learning; the former returns results in a "galaxy" view (see figure at the top of this post), identifying matching data entities by type, and reflecting compliance-based data sensitivity, with specific regard to the EU's General Data Protection Regulation (GDPR) and California's Consumer Protection Act (CCPA), among others.
Also read: GDPR: What the data companies are offering
Immuta, which taglines its platform as Automated Data Governance, announced its Fall 2019 release, which adds a sensitive data detection facility, and authoring of data privacy policies that "ensure" compliance with GDPR, CCPA, the Health Insurance Portability and Accountability Act (HIPAA) and other data protection regulatory frameworks. It also offers native HDFS workspaces and Webhook-based integration with third party tools.
Glue and ACID
At the intersection of the database and data management disciplines lie two announcements from Qubole, a provider of cloud-based data lake services employing the same container-based approach only now being discovered by Cloudera and GCP. On the data management side, Qubole has announced support for the data catalog component in AWS Glue. Now, data engineering, ML and analytics jobs can run on the Qubole Data Platform using Glue's data catalog as the metastore. This seems logical, given Glue data catalog's compatibility with Apache Hive's metastore .
Qubole actually announced the Glue data catalog support this past May but (speaking speaking of Hive) Qubole announced just one week ago that it's been hard at work adding ACID (atomicity, consistency, isolation and durability) capabilities to Hive's bag of tricks. Qubole's motivation here is data governance, in that ACID capabilities ensure that inserts, updates and deletes are committed to the database immediately and transactionally which, among other things, expedites data subjects' "right to be forgotten," and important GDPR compliance requirement.
Bloomberg goes cloud-global
You'll forgive me if I've "cheated" by mentioning Qubole's older news in a story covering new announcements. And you'll hopefully forgive me again, if I do so once more. In that spirit, I'll mention that Bloomberg announced on September 12th that its B-PIPE data feed is now available in the cloud in AWS European and Asian regions, as well as on the US regions that were announced in November of last year.
Also read: Amazon re:Invent: Data partner news summary
As cool as database and data management technology is, actual data, especially that which powers the ubiquitous Bloomberg Terminal, is the whole reason we're doing this. And it's quite fitting with the implementation-oriented announcements at this year's Strata Data NYC event.
Disclosure: Brust worked with Io-Tahoe, in a consulting capacity, from 2017 to 2018.