TPU is 15x to 30x faster than GPUs and CPUs, Google says

Google on Wednesday shared some details regarding the performance of its custom-built Tensor Processing Unit (TPU) chip. Designed for machine learning and tailored for TensorFlow, Google's open-source machine learning framework, TPUs have been powering Google datacenters since 2015.
This first generation of TPUs, Google noted, have targeted inference -- the use of an already trained model, as opposed to the training phase of a model.
On production AI workloads that utilize neural network inference, the TPU is 15 times to 30 times faster than contemporary GPUs and CPUs, Google said.
Additionally, the TPU is much more energy efficient, delivering a 30 times to 80 times improvement in TOPS/Watt measure (tera-operations [trillion or 1012 operations] of computation per Watt of energy consumed).
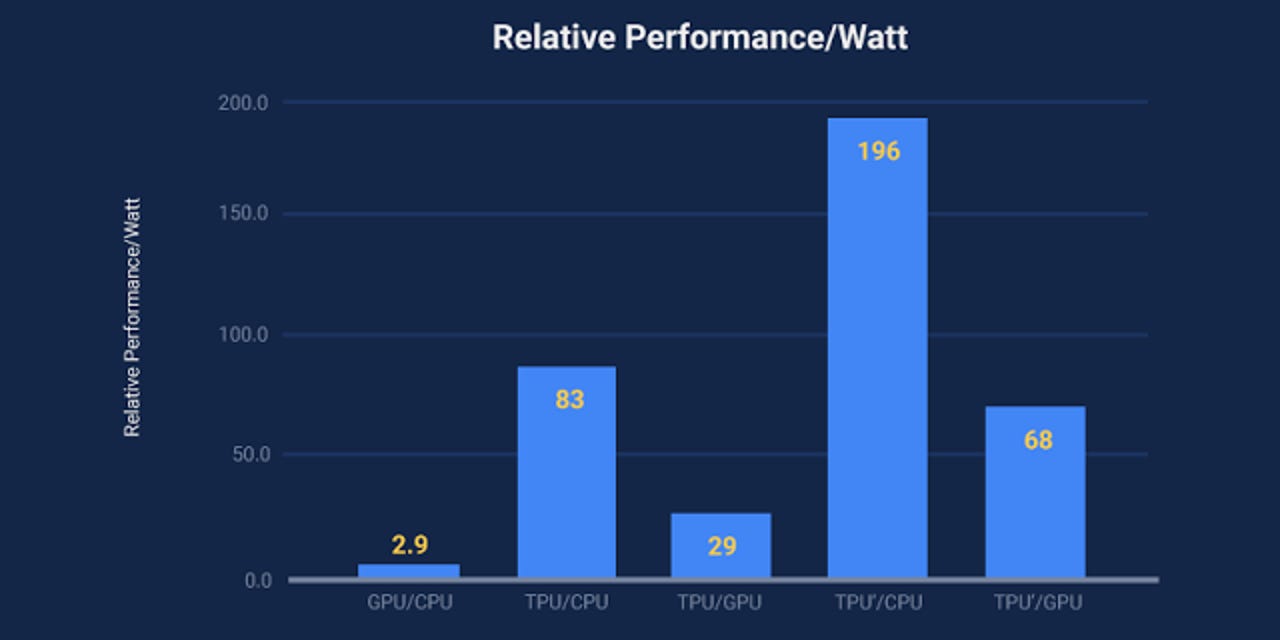
Without the TPU, the computational expense of its deep learning models would have been tremendous Google said.
"If we considered a scenario where people use Google voice search for just three minutes a day and we ran deep neural nets for our speech recognition system on the processing units we were using, we would have had to double the number of Google datacenters!" wrote Google hardware engineer Norm Jouppi.
The TPU details were shared ahead of a talk at the Computer History Museum in Silicon Valley, and they're included in a study with more than 70 contributors.
VIDEO: Finland relies on open data to smarten up the power grid