Flink 1.2 new features

Dynamic scaling
Changing the number of machines allocated to a job while running requires being able to split or merge state to redistribute it to a smaller or larger number of machines. Much of the work on dynamic scaling focused on the internal representation of state. It's now possible to adapt the scale of running jobs while guaranteeing state consistency. Image: Data Artisans
Queryable state
"Turning the stream processor into a database."It means that key-lookup requests are sent directly to Flink (rather than a key-value store or database), and Flink answers directly from its internal operator state. This is significant because 1) it means the results from a Flink computation are immediately accessible without first being sent to a storage layer and 2) the storage layer becomes unnecessary for certain use cases. Image: Data Artisans
Asynchronous I/O
Improvements in the way Flink interacts with external data stores, for instance, when enriching stream events with data stored in a database. Image: Apache Flink
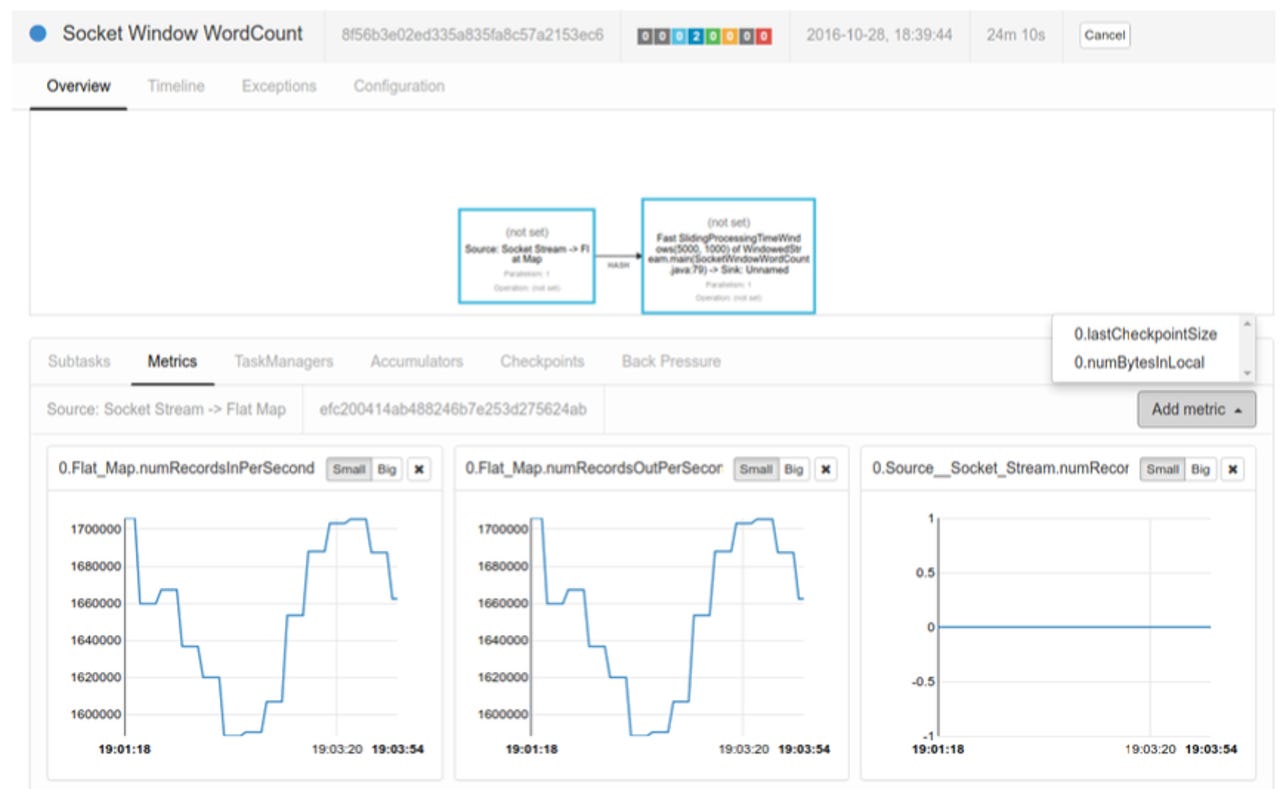
Metrics
In Flink 1.1, the community released Flink's first metrics system for monitoring and debugging. Metrics are now exposed in Flink's web interface. Image: Apache Flink
Security
Kerberos authentication for YARN, HDFS, Zookeeper, and Kafka, and state backend security. Image: Kerberos Project/MIT
Table API & StreamSQL
The Table API is a declarative, embedded API to define relational queries on dynamic and static tables. Table API & SQL major improvements: 1) streaming group windows on the Table API, 2) support for user-defined scalar and table-generating functions, 3) much improved coverage of built-in functions, data types, and relational operators. Image: Data Artisans
Cluster management
Flink can be deployed in a variety of environments, from YARN to Mesos to Kubernetes. Flink 1.2 includes resource manager improvements and makes it straightforward to add support for new tools in the future. Image: Apache Flink/Mesos/Hadoop