Google ponders the shortcomings of machine learning

Critics of the current mode of artificial intelligence technology have grown louder in the last couple of years, and this week, Google, one of the biggest commercial beneficiaries of the current vogue, offered a response, if, perhaps, not an answer, to the critics.
In a paper published by the Google Brain and the Deep Mind units of Google, researchers address shortcomings of the field and offer some techniques they hope will bring machine learning farther along the path to what would be "artificial general intelligence," something more like human reasoning.
The research acknowledges that current "deep learning" approaches to AI have failed to achieve the ability to even approach human cognitive skills. Without dumping all that's been achieved with things such as "convolutional neural networks," or CNNs, the shining success of machine learning, they propose ways to impart broader reasoning skills.
Also: Google Brain, Microsoft plumb the mysteries of networks with AI
The paper, "Relational inductive biases, deep learning, and graph networks," posted on the arXiv pre-print service, is authored by Peter W. Battaglia of Google's DeepMind unit, along with colleagues from Google Brain, MIT, and the University of Edinburgh. It proposes the use of network "graphs" as a means to better generalize from one instance of a problem to another.
Battaglia and colleagues, calling their work "part position paper, part review, and part unification," observe that AI "has undergone a renaissance recently," thanks to "cheap data and cheap compute resources."
However, "many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches," especially "generalizing beyond one's experiences."
Hence, "A vast gap between human and machine intelligence remains, especially with respect to efficient, generalizable learning."
The authors cite some prominent critics of AI, such as NYU professor Gary Marcus.
In response, they argue for "blending powerful deep learning approaches with structured representations," and their solution is something called a "graph network." These are models of collections of objects, or entities, whose relationships are explicitly mapped out as "edges" connecting the objects.
"Human cognition makes the strong assumption that the world is composed of objects and relations," they write, "and because GNs [graph networks] make a similar assumption, their behavior tends to be more interpretable."
Also: Google Next 2018: A deeper dive on AI and machine learning advances
The paper explicitly draws upon work for more than a decade now on "graph neural networks." It also echoes some of the recent interest by the Google Brain folks in using neural nets to figure out network structure.
But unlike that prior work, the authors make the surprising assertion that their work doesn't need to use neural networks, per se.
Rather, modeling the relationships of objects is something that not only spans all the various machine learning models -- CNNs, recurrent neural networks (RNNs), long-short-term memory (LSTM) systems, etc. -- but also other approaches that are not neural nets, such as set theory.
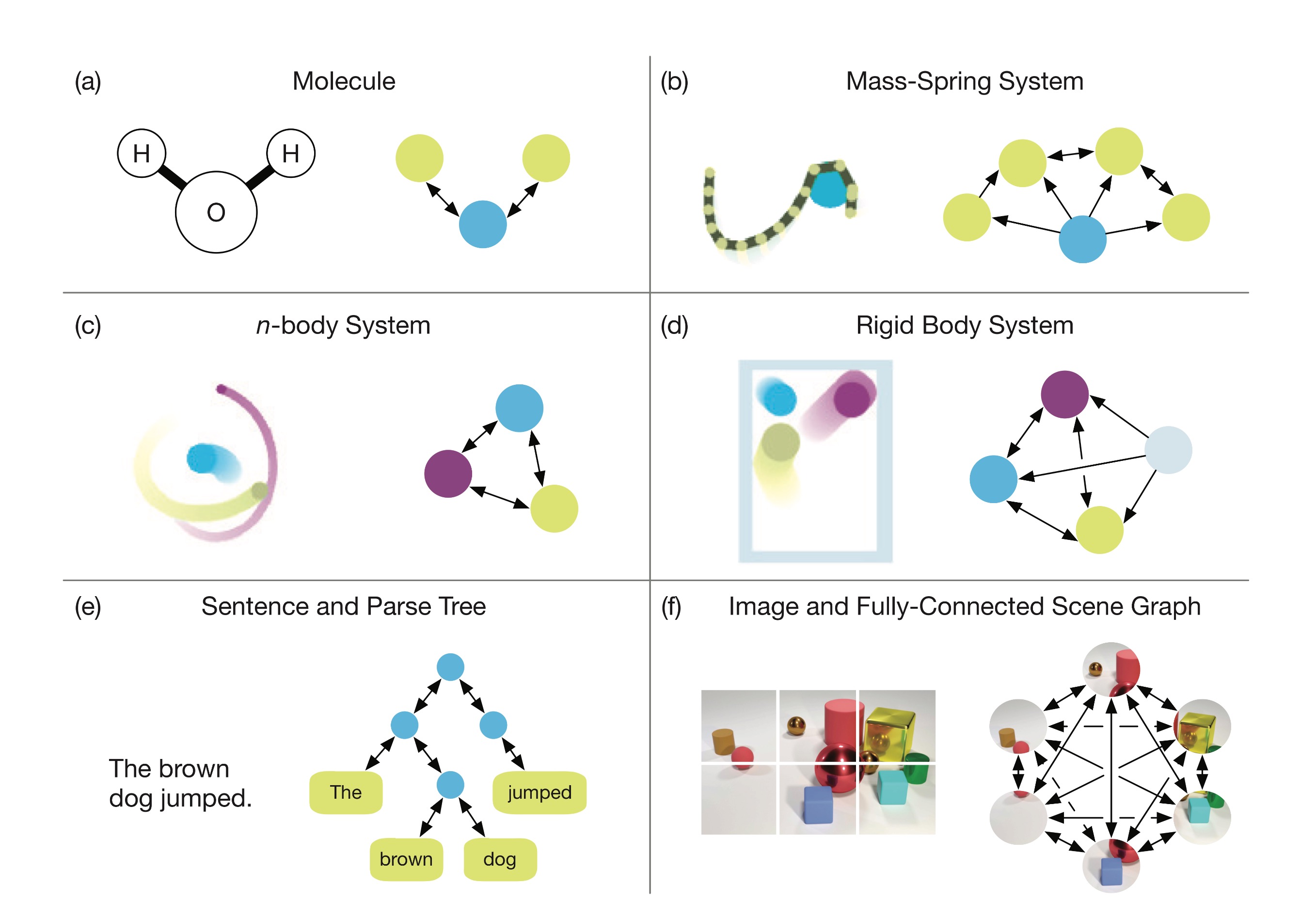
The Google AI researchers reason that many things one would like to be able to reason about broadly -- particles, sentences, objects in an image -- come down to graphs of relationships among entities.
The idea is that graph networks are bigger than any one machine-learning approach. Graphs bring an ability to generalize about structure that the individual neural nets don't have.
The authors write, "Graphs, generally, are a representation which supports arbitrary (pairwise) relational structure, and computations over graphs afford a strong relational inductive bias beyond that which convolutional and recurrent layers can provide."
A benefit of the graphs would also appear to be that they're potentially more "sample efficient," meaning, they don't require as much raw data as strict neural net approaches.
To let you try it out at home, the authors this week offered up a software toolkit for graph networks, to be used with Google's TensorFlow AI framework, posted on Github.
Also: Google preps TPU 3.0 for AI, machine learning, model training
Lest you think the authors think they've got it all figured out, the paper lists some lingering shortcomings. Battaglia & Co. pose the big question, "Where do the graphs come from that graph networks operate over?"
Deep learning, they note, just absorbs lots of unstructured data, such as raw pixel information. That data may not correspond to any particular entities in the world. So they conclude that it's going to be an "exciting challenge" to find a method that "can reliably extract discrete entities from sensory data."
They also concede that graphs are not able to express everything: "notions like recursion, control flow, and conditional iteration are not straightforward to represent with graphs, and, minimally, require additional assumptions."
Other structural forms might be needed, such as, perhaps, imitations of computer-based structures, including "registers, memory I/O controllers, stacks, queues" and others.
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.
Related stories:
- There is no one role for AI or data science: this is a team effort
- Startup Kindred brings sliver of hope for AI in robotics
- AI: The view from the Chief Data Science Office
- Salesforce intros Einstein Voice, an AI voice assistant for enterprises
- It's not the jobs AI is destroying that bother me, it's the ones that are growing
- How Facebook scales AI