Google researchers: COVID-19 super-spreaders are a big part of the problem

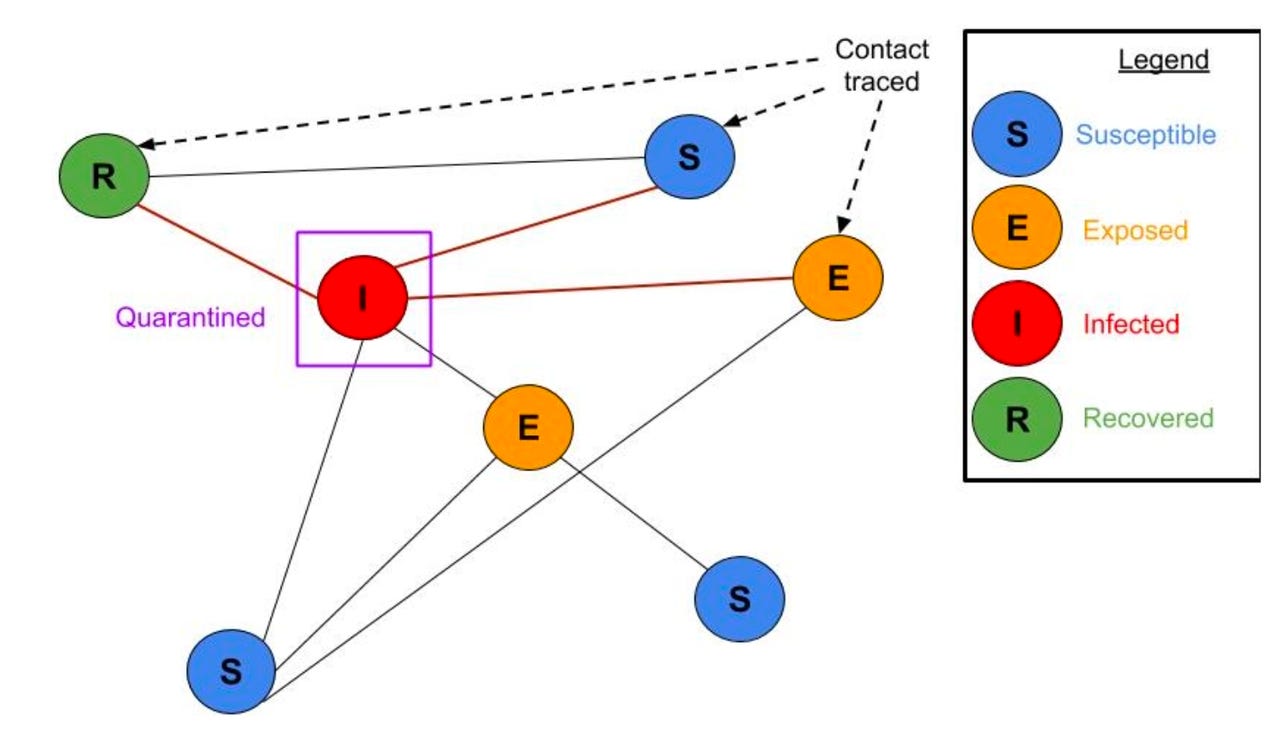
Reich and colleagues construct graphs of people in their various states of infection and the like among people, to simulate how COVID-19 spreads. Caption from the article: "Contact tracing. Some share of the neighbors of a node which tests positive are traced and tested themselves."
New work from Google scientists suggests that mass-testing of populations for the COVID-19 disease is not the way to go, given that infectious events may be heavily weighted toward the so-called super-spreaders, individuals in the population who have a larger-than-average number of contacts and tend to infect more people as a result.
Featured
Scientists Ofir Reich and Guy Shalev of Google, and Tom Kalvari of Tel Aviv University, put together a simulation of the spread of COVID-19 using assumptions about people's networks of relationships. They offer two main takeaways. One is that to unlock society, extensive testing for infection is needed. Second, simply trying to test everyone ignores the structure by which infection spreads, a structure that demands more selective kinds of testing.
The paper, "Modeling COVID-19 on a network: super-spreaders, testing and containment," was posted Tuesday on the pre-print server medRxiv. The paper has not been peer-reviewed, which should be kept in mind in considering its conclusions.
Reich and colleagues move beyond the typical infectious disease models that are commonly used for COVID-19. Those models are based on the so-called "susceptible, infectious, recovered" model of disease spread. The SIR model is a "mechanistic" model, based on a very general understanding of the mechanism by which all infectious diseases spread. It was first introduced in 1927 by scientists William Ogilvy Kermack and Anderson Gray McKendrick.
The problem, according to Reich & Co., is that SIR is focused heavily on one number above all others, the "R-naught," the theoretical transmission rate, how many people, on average, each infected person can infect. It's been the dominant focus of models of COVID-19 for months now.
Also: Graph theory suggests COVID-19 might be a 'small world' after all
Instead, Reich and team emphasize not the average, but the extraordinary cases in society, the people who have many more contacts than most people, and can therefore infect an unusually large amount of people. Super-spreaders have been studied for many years with respect to numerous epidemics. The 2014-2015 outbreak of the Middle East Respiratory Syndrome coronavirus, or "MERS," was traced to one South Korean individual who spread the disease to numerous individuals, two of whom spread the disease to further large groups. Similar patterns of "index" patients were observed with Ebola and with the SARS outbreak in 2002 to 2003.
Scientists don't know exactly why certain people "shed" virus, meaning, pass it on, more than others. It might have to do with weakened immunity in those individuals, but there are other hypotheses. (Scientist Gary Wong and colleagues at the Chinese Academy of Science provided an excellent explanation of the super-spreader phenomenon in a paper a few years ago, and their work is cited by Reich & Co.)
Reich, who is a data scientist at Google, doesn't have the explanation for why super-spreading happens. Rather, he and colleagues take the fact of super-spreading as a given to create predictions of what super-spreading does in a pandemic.
To model the effect of super-spreading, they rely on what's called graph theory, where each person is thought of as a "node" that is connected to other people -- friends, family, colleagues -- by links. This is the notion of a social network: Every person in a population has links to friends and family and co-workers, everyone is "connected" to others to a greater or lesser extent.
There is an average number of relations for any person in that network, and then there are people who are extraordinary in their connectedness, the super-spreaders.
Here's where Reich and colleagues depart from the SIR model as it is commonly used. SIR models "implicitly assume that each infectious node causes the same number of infections, and that each susceptible node is equally likely to be infected," they write.
That assumption means the calculations of such models are "systematically wrong," Reich and colleagues contend. Such models have no structure, meaning, they don't reflect the way that people come into contact in the real world.
"Graph structure, i.e. the network of who can infect whom, has a decisive effect on the growth of epidemics," write Reich and team. Specifically, super-spreaders "matter a lot" in that structure, they write.
It is "crucial to model the graph structure to reach the right conclusions about epidemic spread."
In a series of graphs, the authors illustrate how their modeling of super-spreaders shows that a disease can spread faster when the average transmission rate remains the same, just because there are more super-spreaders.
Reich and team contend their model achieves a much better prediction of what has been seen in the real world with COVID-19, "a far better predictor of the growth rate," as they put it, than the typical transmission rate of the SIR models.
Reich and colleagues have posted the code on GitHub to run the simulation.
Reich and colleagues show that even for the same "R," transmission rate, on average, infections can rise faster with a higher "gamma," the measure of how many "degrees" of contacts a person in the society has -- the super-spreaders.
The conclusions of the paper, as far as policy, are that testing has to happen, but in a selective way.
Testing is crucial, they argue, because otherwise, the easing of lockdown and quarantine in a society can lead to a resurgence of disease, including COVID-19.
"Exiting lockdowns without allowing critical levels of spread is possible if testing and tracing capacity are available," they write. "Without those measures driving R below 1, exiting lockdown would cause re-emergence of the epidemic," referring to the theoretical transmission rate.
The importance of testing to avoid a resurgence is a point other researchers have made recently. But trying to test as many people as possible is not the right way to go, Reich and colleagues insist. "Testing the general population (mass testing) is mostly futile for containment" because "it needs to be done at such a high rate that [it] requires infeasible resources."
It would be better, they contend, to focus that effort on those individuals who are already symptomatic, but that in itself won't contain a pandemic because it takes time to find and quarantine those people, and that allows time for them to infect others.
And, of course, given what appear to be large numbers of asymptomatic or "pre-symptomatic" people, there's going to be a lot of people who are sick and go undetected and don't get tested. For example, upward of 79% of the people who had COVID-19 in Hunan province in China in January are believed to have have shown no symptoms, at least one study has found.
"Something more is required," write Reich & Co.
That something else could be contact tracing, following up on the people to whom an infectious person has exposed themselves, and who may consequently be infected. "For those who tested positive, some fraction of their neighbors is traced and tested." Contact tracing can uncover the ways in which people infect others in "clusters," they surmise, and that means it can uncover a lot of other infectious events.
Google has announced smartphone technology to perform contact tracing in an automated fashion, along with Apple. The paper by Reich et al., however, does not appear to be an official Google effort.
Finally, all this testing can be combined with some degree of social distancing, "to slow the base rate of spread."
"Our simulations suggest some social distancing (short of lock-down), testing of symptomatics and contact tracing are the way to go."
There are numerous limitations to the work, which the authors discuss at length. There are a lot of details of real-world networks of human interaction that they don't have access to, which would require more real-world data. They haven't explicitly modeled the effect of asymptomatic members of the population, which could be an important area of further exploration, they note. Nor have they incorporated the phenomena of super-spreader "events," mass gatherings that may have led to substantial one-time infection outbreaks of COVID-19.
The work of Reich and colleagues is by no means the first to use graphs to model how people spread disease. There is a rich literature. More recently, research in late February by scholars Anna Ziff and Robert Ziff hypothesized COVID-19 might reflect a "small world" network where a few people who zip around the world on international flights can bring a disease back to their local community.
The graph approach is controversial even among those who've dedicated their careers to it. Harvard scientist Joel Miller, who has co-authored a book about networks of relationships in relation to disease took to Twitter this week to urge caution in applying graphs to COVID-19.
Given how much is still being learned about the disease, Miller wrote, super-spreaders are just one of the many things to consider. "There are other issues that are equally important."
Dear everyone (especially people reading @tylercowen's blog) and discovering the fact that epidemics can be modeled as spreading on networks.
We know about this fact. We also know it affects some of the predictions.— Joel Miller (@joel_c_miller) May 5, 2020