Alpine Data Spark Auto Tuning
Alpine Data's approach to automating Spark

1 of 6 Alpine Data
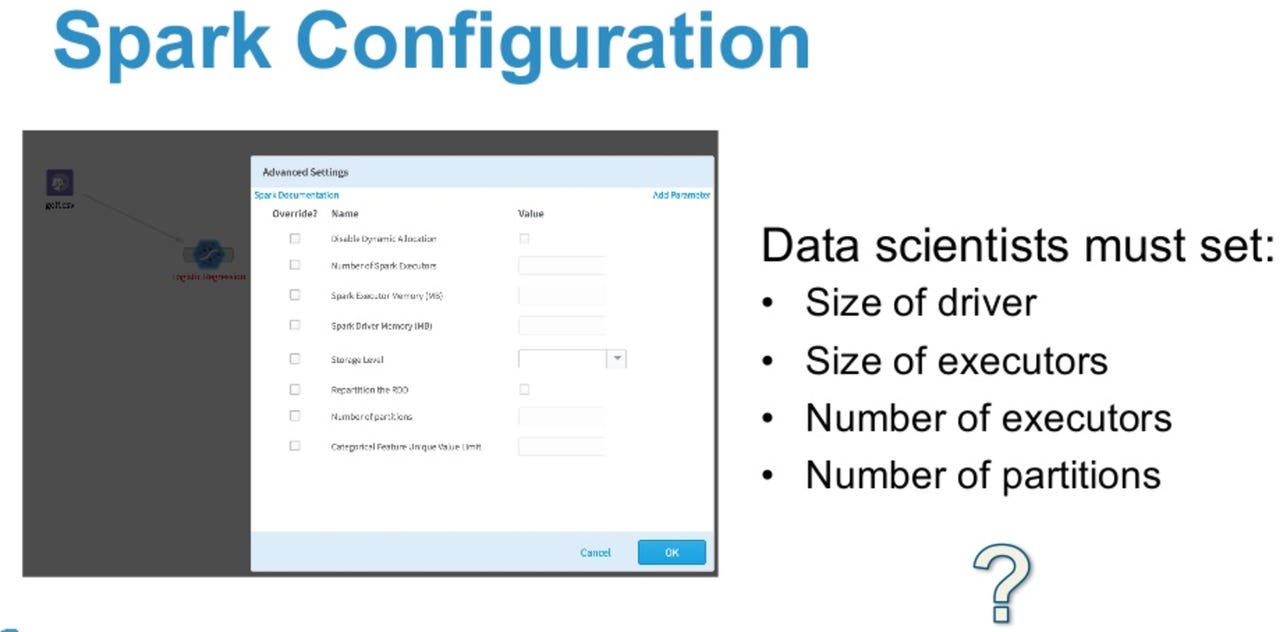
Spark Configuration
Configuring a Spark cluster is not the easiest thing in the world, even if you are a data scientist
2 of 6 Alpine Data
Look ma, no data scientist
Alpine Labs wants to support scenarios in which there is no data scientist involved
3 of 6 Alpine Data
Machine Learning to the rescue
Alpine Labs uses ML under the hood.
4 of 6 Alpine Data
Spark Overheads
Spark has its nuances, and these need to be taken into account when deploying jobs and tuning clusters
5 of 6 Alpine Data
Spark Architecture
But can data scientists really know everything about Spark?
6 of 6 Alpine Data
Spark cluster tuning challenges
Finding a good tuning solution for Spark clusters is not trivial.
Related Galleries
Holiday wallpaper for your phone: Christmas, Hanukkah, New Year's, and winter scenes
![Holiday lights in Central Park background]()
Related Galleries
Holiday wallpaper for your phone: Christmas, Hanukkah, New Year's, and winter scenes
21 Photos
Winter backgrounds for your next virtual meeting
![Wooden lodge in pine forest with heavy snow reflection on Lake O'hara at Yoho national park]()
Related Galleries
Winter backgrounds for your next virtual meeting
21 Photos
Holiday backgrounds for Zoom: Christmas cheer, New Year's Eve, Hanukkah and winter scenes
![3D Rendering Christmas interior]()
Related Galleries
Holiday backgrounds for Zoom: Christmas cheer, New Year's Eve, Hanukkah and winter scenes
21 Photos
Hyundai Ioniq 5 and Kia EV6: Electric vehicle extravaganza
![img-8825]()
Related Galleries
Hyundai Ioniq 5 and Kia EV6: Electric vehicle extravaganza
26 Photos
A weekend with Google's Chrome OS Flex
![img-9792-2]()
Related Galleries
A weekend with Google's Chrome OS Flex
22 Photos
Cybersecurity flaws, customer experiences, smartphone losses, and more: ZDNet's research roundup
![shutterstock-1024665187.jpg]()
Related Galleries
Cybersecurity flaws, customer experiences, smartphone losses, and more: ZDNet's research roundup
8 Photos
Inside a fake $20 '16TB external M.2 SSD'
![Full of promises!]()